lassoglm
用于广义线性模型的套索或弹性网正则化
语法
描述
例子
使用Lasso正则化去除冗余预测
构造一个具有冗余预测因子的数据集,并使用lassoglm.
创建一个随机矩阵X有100个观察和10个预测因子。创建正常分布的响应y只使用四种预测和少量的噪声。
RNG.默认的10 X = randn (100);重量= (0.6;0.5;0.7;0.4);y = X(:,[2 4 5 7])*weights + randn(100,1)*0.1;%小的添加噪声
执行套索正规化。
B = lassoglm (X, y);
找到75th的系数矢量λ价值B.
B (:, 75)
ans =10×10 0.5431 0 0.3944 0.6173 0 0.3473 0 0
lassoglm标识并删除冗余预测器。
广义线性模型交叉验证的套索正则化
从泊松模型构建数据,并通过使用lassoglm.
使用20个预测器创建数据。仅使用三个预测器加上常数创建泊松响应变量。
RNG.默认的%的再现性20 X = randn (100);重量=(。4;2。3);mu = exp(X(:,[5 10 15])*weights + 1);y = poissrnd(μ);
构建数据的泊松回归模型的交叉验证套索正则化。
[B, FitInfo] = lassoglm (X, y,“泊松”,“简历”10);
检查交叉验证情节以查看效果λ正则化参数。
Lassoplot(B,FitInfo,“plottype”,“简历”);传奇(“显示”)%显示传奇
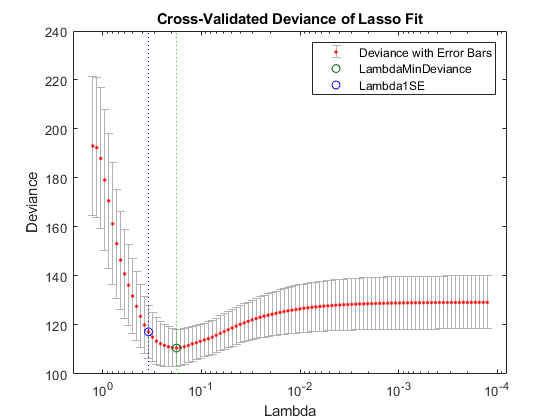
绿色圆圈和虚线定位λ以最小的交叉验证错误。蓝色圆圈和虚线定位交叉验证误差最小加上一个标准差的点。
找到与两个已识别点对应的非零模型系数。
idxLambdaMinDeviance = FitInfo.IndexMinDeviance;mincoefs = find(b(:,idxlambdamindeviance))
mincoefs =7×13 5 6 10 11 15 16
idxLambda1SE = FitInfo.Index1SE;min1coefs =找到(B (:, idxLambda1SE))
min1coefs =3×15 10 15.
来自最小加上一个标准错误点的系数正是用于创建数据的系数。
使用套索正则化预测值
预测学生在上次考试中是否获得了B或以上的成绩lassoglm.
加载考试数据集。将上次考试成绩转换为逻辑向量,其中1代表80或以上的等级和0表示低于80分。
负载考试x =等级(:,1:4);Y =等级(:,5);YBINOM =(Y> = 80);
将数据划分为训练集和测试集。
RNG.默认的%设置种子以进行再现性c = cvpartition (yBinom“坚持”, 0.3);idxTrain =培训(c, 1);idxTest = ~ idxTrain;XTrain = X (idxTrain:);yTrain = yBinom (idxTrain);XTest = X (idxTest:);欧美= yBinom (idxTest);
对训练数据进行三次交叉验证,对广义线性模型回归进行拉索正则化。假设y二项分布。选择对应的模型系数λ最低预期偏差。
[b,fitinfo] = lassoglm(xtrain,ytrain,'二重子',“简历”3);idxLambdaMinDeviance = FitInfo.IndexMinDeviance;B0 = FitInfo.Intercept (idxLambdaMinDeviance);系数= [B0;B (:, idxLambdaMinDeviance)]
COEF =5×1-21.1911 0.0235 0.0670 0.0693 0.0949
使用前一步中找到的模型系数预测测试数据的考试成绩。使用分对数的.将预测值转换为逻辑向量。
XTest yhat = glmval(系数,分对数的);yhatBinom = (yhat > = 0.5);
使用混淆矩阵确定预测的准确性。
c =困惑的园林(YTEST,Yhatbinom);
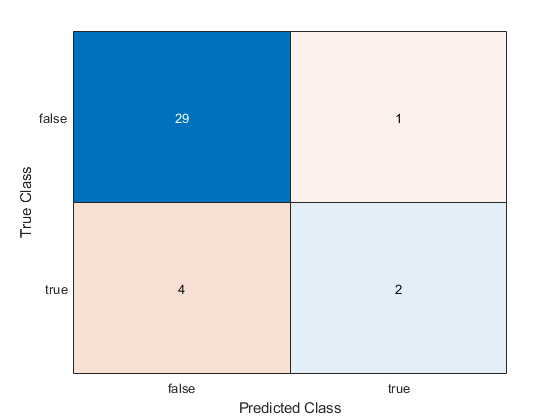
该函数正确预测了31个考试成绩。然而,该函数错误地预测了1名学生获得B或以上的成绩4学生的成绩在B以下。
输入参数
输出参数
更多关于
参考文献
[1] Tibshirani, R.“通过套索的回归收缩和选择”。皇家统计学会杂志。系列B, Vol. 58, No. 1, 1996, pp. 267-288。
[2]邹,H.和Hastie。“通过弹性网进行正则化和可变选择。”皇家统计学会杂志。系列B, Vol. 67, No. 2, 2005, pp. 301-320。
[3] Friedman, J., R. Tibshirani, T. Hastie。“基于坐标下降的广义线性模型正则化路径”统计软件杂志。卷。33,2010年第1号。https://www.jstatsoft.org/v33/i01
Hastie, T., R. Tibshirani, J. Friedman。统计学习的要素。第二版。纽约:施普林格,2008。
多布森广义线性模型导论。第二版。纽约:查普曼与霍尔/CRC出版社,2002。
P. McCullagh和J. A. Nelder。广义线性模型。第二版。纽约:1989年Chapman&Hall / CRC Press。
[7] Collett D。造型二进制数据。第二版。纽约:查普曼与霍尔/CRC出版社,2003。
扩展功能
您还可以从以下列表中选择一个网站:
