mnrval
多项Logistic回归价值
语法
描述
例子
评估类别概率标称响应
适用于额定结果的多项式回归,并估计该类别的概率。
加载样本数据。
负载fisheriris
列向量,物种,由三个不同品种的花菖蒲,setosa,云芝,弗吉尼亚。双矩阵量由上的花朵,分别四种类型的测量,以厘米为单位的长度和萼片和花瓣的宽度的。
定义标称响应变量。
sp=标称(物种);sp=双(sp);
现在SP.、1、2和3分别表示刚毛、杂色和维吉尼亚。
适合估计用花测量值作为预测变量的种类标准模型。
[B,发展,统计]=mnrfit(多边环境协定,标准普尔);
如果鸢尾花有测量值(6.3,2.8,4.9,1.7),估计其成为某种物种的概率。
X = [6.3,2.8,4.9,1.7]。pihat = mnrval(B,X);pihat
pihat =1×30 0.3977 0.6023
具有测量值(6.3,2.8,4.9,1.7)的鸢尾花成为刚毛的概率为0,花色为0.3977,弗吉尼亚为0.6023。
估计有序响应的概率估计的上、下误差界
适合多项式回归模型与类别之间的自然排序分类响应。然后,估计该类别概率估计的上下置信区间。
装载样品数据和定义的预测变量。
加载(“carbig.mat”) X =[加速度位移马力重量];
预测变量是加速度、发动机排量、马力和汽车重量。响应变量是每加仑英里数(MPG)。
创建一个序响应变量归类MPG为四个层次的9至48英里。
英里=序数(MPG, {' 1 ',' 2 ',“3”,“4”},[],[39 9日,19日,29日,48]);英里=双(英里);
以英里为单位,1表示从9到19英里每加仑的汽车,2表示从20到29英里每加仑的汽车。类似地,3和4分别表示每加仑汽油行驶里程从30到39和40到48的汽车。
拟合多项式回归模型响应变量英里。对于序数模型,默认值为“链接”是Logit模型默认值是多少“互动”是“关”.
[B, dev,统计]= mnrfit (X,英里,'模型',“顺序”);
计算每加仑汽车行驶英里数的概率估计值和95%的误差范围 = (12, 113, 110, 2670).
X = [12,113,110,2670];[pihat,dlow,喜] = mnrval(B,X,统计数据,'模型',“顺序”);pihat
pihat =1×40.0615 0.8426 0.0932 0.0027
计算类别概率估计的置信边界。
LL=pihat-dlow;UL=pihat+hi;[LL;UL]
ans =2×40.0073 0.7829 0.0283 -0.0003 0.1157 0.9022 0.1580 0.0057
估计类别计数和错误界限的名义回应
拟合一个多项式回归的名义结果和估计类别计数。
加载样本数据。
负载fisheriris
列向量,物种,由三种不同种类的鸢尾花组成,柱头花(setosa)、花斑花(versicolor)和弗吉尼亚花(virginica)。双矩阵量由上的花朵,分别四种类型的测量,以厘米为单位的长度和萼片和花瓣的宽度的。
定义标称响应变量。
sp=标称(物种);sp=双(sp);
现在SP.、1、2和3分别表示刚毛、杂色和维吉尼亚。
拟合一个标称模型,根据花的测量值来估计物种。
[B,发展,统计]=mnrfit(多边环境协定,标准普尔);
用测量值(6.3,2.8,4.9,1.7)估算100朵鸢尾花样本中每个种类的数量。
X = [6.3,2.8,4.9,1.7]。yhat = mnrval(B,X,18)
yhat =1×30 7.1578 10.8422
估计计数的误差范围。
[yhat,dlow,hi]=mnrval(B,x,18,stats,'模型',“名义上的”);
计算类别概率估计的置信边界。
LL = yhat - dlow;UL = + yhat喜;[LL; UL]
ans =2×30 3.3019 6.9863 0 11.0137 14.6981
画出计数估计
创建带有一个预测变量和一个带有三个类别的分类响应变量的样本数据。
X = [-3 -2 -1 0 1 2 3]';Y = [1 11 13;2 9 14;6 14 5;5 10 10;......5 14 6;7 13 5;8 11 6];[Y X]
ans =7×41 11 13 -3 2 9 14 -2 6 14 5 -1 5 10 10 0 5 14 6 1 7 13 5 2 8 11 6 3
对预测变量的七个不同值进行了观察x.响应变量Y有三类和数据显示有多少25个人是在每个类别Y每观察一次x.例如,当x是-3,25个个体中有1个在第1类中观察到,11个在第2类中观察到,13个在第3类中观察到。同样的,当x在1类中观察到5个个体,在2类中观察到14个个体,在3类中观察到6个个体。
绘制每个类别中的数字与x值,在堆叠的条形图上。
栏(x, Y,“堆叠”);ylim([0 25]);
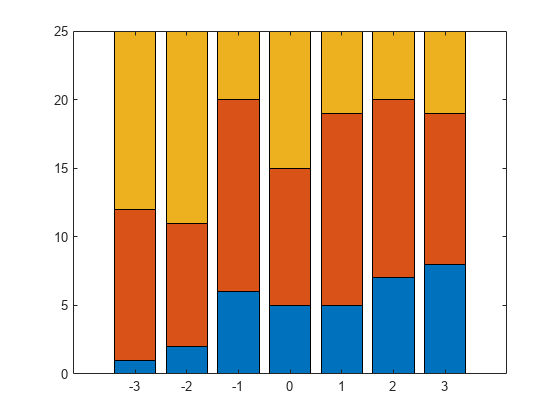
拟合个别反应类别概率的名义模型,在单个预测变量上有单独的斜率,x,为每个类别。
betaHatNom=mnrfit(x,Y,'模型',“名义上的”,......“互动”,“上”)
betaHatNom =2×2-0.6028 0.3832 0.4068 0.1948
第一排betaHatOrd包含前两个响应类别的拦截术语。第二行是斜率。mnrfit接受第三类别作为参考类别,并因此不对第三类的系数均为零。
计算三个反应类别的预测概率。
xx = linspace (4, 4) ';piHatNom = mnrval (betaHatNom, xx,'模型',“名义上的”,......“互动”,“上”);
的第三类是所述概率仅仅是1 - P( =1)-P( = 2)。
在条形图上绘制每个类别的估计累积数量。
线(XX,cumsum(25 * piHatNom,2),“线宽”,2);
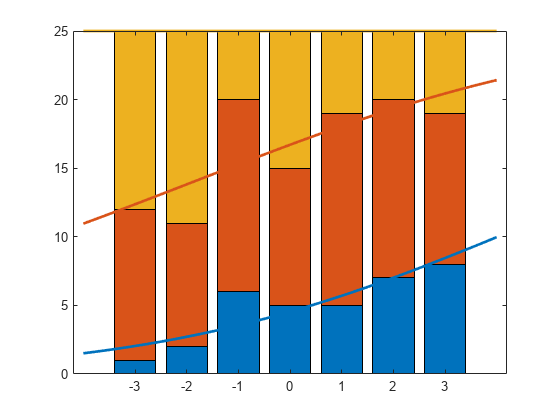
第三类累积概率始终为1。
现在,适合的累积响应类别概率“并行”序数模型,具有共同的斜率上的单个预测变量,x在所有类别:
betaHatOrd = mnrfit (x, Y,'模型',“顺序”,......“互动”,“关”)
betaHatOrd =3×1-1.5001 0.7266 0.2642
前两个要素betaHatOrd是前两个响应类别的截取项。的最后一个元素betaHatOrd是共同斜率。
计算用于前两个响应的类别的预测累积概率。第三类累积概率始终为1。
piHatOrd = mnrval (betaHatOrd, xx,'类型',“累积”,......'模型',“顺序”,“互动”,“关”);
在观察到的累积数的柱状图上绘制估计的累积数。
图()条(x,总和(Y,2),“分组”); ylim([025]);行(xx,25*piHatOrd,“线宽”,2);

输入参数
输出参数
参考文献
[1] McCullagh,P.和J.A.Nelder。广义线性模型纽约:查普曼和霍尔,1990年。
您还可以从以下列表中选择一个网站:
