偏最小二乘
偏最小二乘导论
偏最小二乘(请)回归是一种用于包含相关预测变量的数据的技术。这种技术构建了新的预测变量,称为组件,为原始预测变量的线性组合。PLS在考虑观测响应值的同时构建了这些分量,导致了一个具有可靠预测能力的简约模型。
多元线性回归找到最适合响应的预测因子的组合。
主成分分析发现具有大方差的预测因子的组合,降低相关性。该技术不使用响应值。
PLS发现与响应值有很大协方差的预测因子的组合。
因此,PLS结合了有关预测因子和响应的方差的信息,同时也考虑了它们之间的相关性。
PLS与其他回归和特征变换技术具有相同的特征。它类似于岭回归因为它被用在有相关预测的情况下。它类似于逐步回归(或更一般的特征选择技术),因为它可以用来选择更小的模型术语集。PLS与这些方法的不同之处在于,它将原始的预测空间转化为新的成分空间。
这个函数plsregress进行PLS回归。
执行偏最小二乘回归
这个例子演示了如何执行PLS回归,以及如何在PLS模型中选择组件的数量。
考虑生物化学需氧量的数据moore.mat,里面塞满了预测器的嘈杂版本,以引入相关性。
负载摩尔: y =摩尔(6);%响应X0 =摩尔(:,1:5);%原预测X1 = X0 + 10 * randn(大小(X0));%相关预测因子X = (X0, X1);
使用plsregress用与预测因子相同的分量进行PLS回归,然后将响应中解释的方差百分比作为分量数目的函数绘图。
[XL, yl, X, y,β,PCTVAR] = plsregress (X, y, 10);情节(1:10,cumsum (100 * PCTVAR (2:)),“o”)包含(“PLS组件数量”) ylabel (“以y解释的方差百分比”)
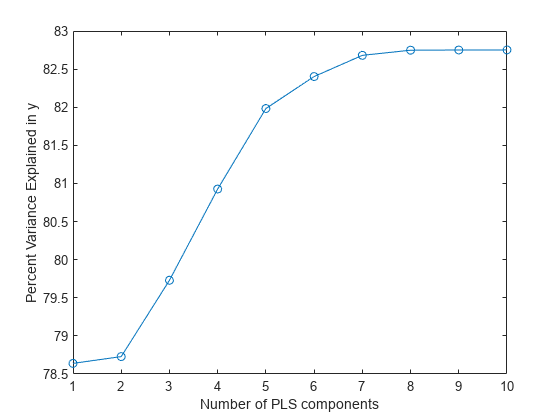
PLS模型中组件数量的选择是一个关键步骤。这张图给出了一个粗略的指示,显示了将近80%的方差y由第一个组件解释,多达五个额外组件作出重要贡献。
下面计算六分量模型。
[XL, yl, X, y,β,PCTVAR, MSE,统计]= plsregress (X, y, 6);yfit = [ones(size(X,1),1) X]* β;情节(y, yfit,“o”)
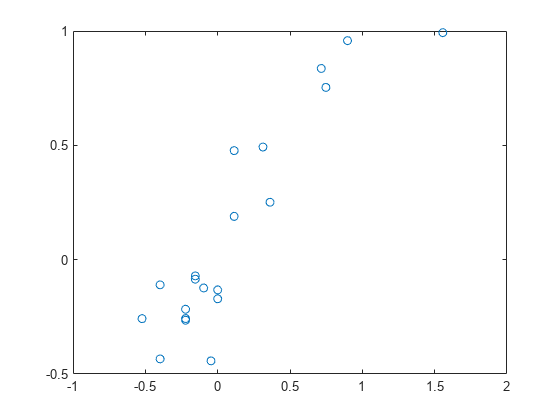
在拟合响应和观测响应之间的散点显示出合理的相关性,这被 统计。
TSS =总和(y-mean (y)) ^ 2);RSS = ((y-yfit) ^ 2)总和;Rsquared = 1 - RSS/TSS
Rsquared = 0.8240
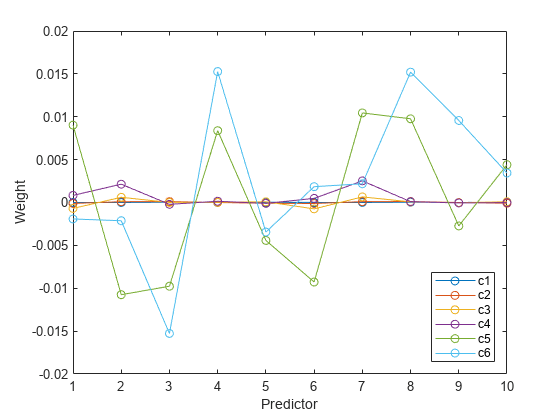
这六个分量中每个分量的十个预测因子的权重图显示,其中两个分量(最后两个计算出来的)解释了大部分的方差X.
图绘制(1:10,统计数据。W,“啊——”)({传奇“c1”,c2的,“c3”,“c4”,“c5”,“c6”},“位置”,“最佳”)包含(“预测”) ylabel (“重量”)
均方根误差图表明,只要有两个分量就可以提供一个足够的模型。
图yyaxis左情节(0:6 MSE (1:)“o”) yyaxis正确的情节(0:6 MSE (2:)“o”)传说(的均方误差预测,“MSE响应”)包含(“组件”)
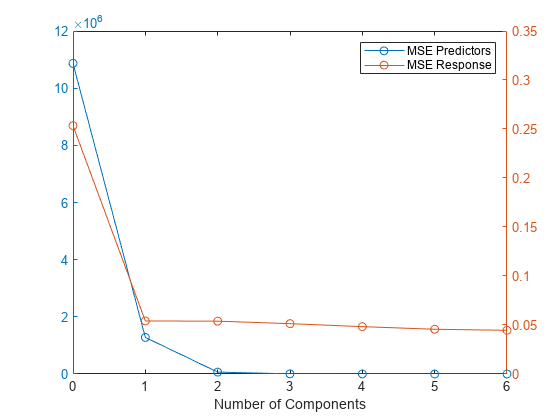
均方误差的计算plsregress是由指定交叉验证类型和蒙特卡罗重复次数的可选名称-值参数控制的。
另请参阅
相关的话题
你也可以从以下列表中选择一个网站:
