线性回归
准备数据
要开始拟合回归,请将数据放入拟合函数期望的形式中。所有回归技术从数组中的输入数据开始X响应数据在一个单独的向量中y或表或数据集数组中的输入数据TBL.作为列的响应数据TBL.。输入数据的每一行代表一个观察。每列代表一个预测器(变量)。
对于表或数据集数组TBL.,表示响应变量'responsevar'名称-值对:
mdl = fitlm(tbl,'responsevar'那'血压');
默认情况下,响应变量是最后一列。
你可以用数字分类预测因子。绝对预测器是从一组固定的可能性中取值。
对于数字数组
X,用。表示分类预测因子“分类”名称-值对。例如,指示预测因子2和3.其中6个是绝对的:mdl = fitlm(x,y,“分类”,[2,3]);%或同等mdl = fitlm(x,y,“分类”,逻辑的([0110100]);
对于表或数据集数组
TBL.,拟合功能假设这些数据类型是分类的:逻辑向量
分类载体
字符数组
字符串数组
如果要指示数值预测值是分类的,请使用
“分类”名称-值对。
代表缺少的数字数据南。若要表示其他数据类型的缺失数据,请参阅缺少群体价值。
用于输入和响应数据的数据集数组
从Excel创建数据集数组的步骤®电子表格:
ds = dataset('xlsfile'那“hospital.xls”那......'readobsnames',真的);
从工作区变量创建数据集数组:
加载Carsmall.DS =数据集(MPG,重量);ds.year =分类(model_year);
输入和响应数据的表
要从Excel电子表格创建表:
台= readtable (“hospital.xls”那......“ReadRowNames”,真的);
要从工作区变量创建表:
加载Carsmall.TBL =表(MPG,重量);tbl.year =分类(model_year);
输入数据的数字矩阵,响应的数字向量
例如,要从工作区变量创建数字数组:
加载Carsmall.X =[重量马力汽缸Model_Year];y = MPG;
要从Excel电子表格创建数字数组:
[x,xnames] = xlsread(“hospital.xls”);y = x(:,4);反应y为收缩压x(:,4)= [];%从X矩阵中删除y
请注意,非数字项,例如性别,不要出现在X。
选择拟合方法
有三种方法可以使模型与数据相匹配:
最小二乘拟合
使用Fitlm.构造模型的最小二乘拟合到数据。当您合理地确定模型的形式时,此方法最佳,主要需要找到其参数。当您想要探索一些型号时,此方法也很有用。该方法要求您手动检查数据以丢弃异常值,但有帮助(参见检查质量,调整拟合模型).
强大的健康
使用Fitlm.与抢劫案命名-值对以创建受异常值影响较小的模型。稳健拟合可省去手动丢弃异常值的麻烦。但是,步不适用于柔软的配件。这意味着当您使用强大的拟合时,您无法逐步搜索良好的模型。
逐步适合
使用步骤行程找到模型,并将参数拟合到模型中。步骤行程从一个模型开始,例如常量,并一次添加或减去术语,每次以贪婪的方式选择最佳术语,直到它不能进一步改善。使用逐步拟合找到一个好的模型,这是一个只有相关术语的模型。
结果取决于起始模型。通常,从常数模型开始会产生一个小模型。从更多项开始会产生一个更复杂的模型,但均方误差较小。请参阅比较大而小的逐步型号。
您不能使用强大的选项以及逐步拟合。所以在逐步拟合之后,检查您的异常值模型(见检查质量,调整拟合模型).
选择模型或型号范围
有几种方法可以指定线性回归模型。用你认为最方便的方法。
为了Fitlm.,您给出的模型规范是适合的模型。如果您没有给出模型规范,则默认为'线性'。
为了步骤行程,您提供的模型规格是逐步过程尝试改进的起始模型。如果您不提供模型规格,则默认起始模型为“常数”,默认的上限模型是'互动'。使用该改变上限模型上名称-值对。
笔记
还有其他选择模型的方法,例如使用套索那lassoglm.那序列, 或者plsregress.。
简短的名字
| 姓名 | 模型类型 |
|---|---|
“常数” |
模型仅包含一个常数(拦截)术语。 |
'线性' |
模型包含每个预测器的截距和线性项。 |
'互动' |
模型包含截距,线性术语和所有对不同预测器的产品(没有平方术语)。下载188bet金宝搏 |
'purequadratic' |
模型包含截距项、线性项和平方项。 |
'二次' |
模型包含截距、线性项、相互作用和平方项。 |
'Poly. |
模型是一个多项式,所有项都达到次一世在第一个预测器中,度j在第二个预测中,等等。使用数字0.通过9.。例如,'poly2111'有一个常数加上所有的线性和乘积项,也包含预测因子1的平方项。 |
例如,要使用交互模型使用Fitlm.使用矩阵预测器:
mdl = fitlm(x,y,'互动');
指定模型使用步骤行程和一个表或数据集数组TBL.预测器,假设您希望从常量开始并具有线性模型上限。假设响应变量TBL.在第三列。
mdl2 = stepwiselm(tbl,“常数”那......'上'那'线性'那'responsevar',3);
术语矩阵
一个条件矩阵T.是一个T.-经过-(P.+ 1)矩阵指定模型中的术语,其中T.是术语数量,P.是预测变量的数量,+1帐户响应变量。的价值T(i,j)是变量的指数j长期一世。
例如,假设输入包括三个预测变量一种那B.,C和响应变量y按顺序一种那B.那C,y。每一排T.代表一个术语:
[0 0 0 0]- 持续术语或拦截[0 1 0 0]-B.;同等,a ^ 0 * b ^ 1 * c ^ 0[1 0 1 0]-* C[2 0 0]-A ^ 2.[0 1 2 0]-B * (C ^ 2)
这0.在每一项的末尾表示响应变量。通常,项矩阵中的零列向量表示响应变量的位置。如果在矩阵和列向量中有预测器和响应变量,则必须包括0.对于每行最后一列中的响应变量。
公式
模型规范的公式是表单的字符向量或字符串标量
'那y〜条款'
y是响应名称。条款包含变量名
+包含下一个变量-排除下一个变量:要定义交互,术语的产物*定义交互作用和所有低阶项^将预测器提升到权力,完全如*重复,所以^包括较低的阶数()组条件
提示
默认情况下,公式包含常量(截距)项。若要从模型中排除常量项,请包括-1在公式中。
例子:
“Y~A+B+C”是一个三变线性模型,带有截距。'y〜a + b + c - 1'是一个无截距的三变量线性模型。'Y〜A + B + C + B ^ 2'是一个三变量模型,拦截和aB^2学期。'y〜a + b ^ 2 + c'与前面的例子相同,因为B^2包括A.B.学期。‘Y~A+B+C+A:B’包括一个A * B学期。'y〜a * b + c'与前面的例子相同,因为a * b = a + b + a:b。a * b * c - a: b: c '所有的相互作用一种那B.,C,除了三方互动。'Y〜a *(b + c + d)'具有所有线性项,加上下载188bet金宝搏一种使用其他每个变量。
例如,要使用交互模型使用Fitlm.使用矩阵预测器:
mdl = fitlm(x,y,'y ~ x1*x2*x3 - x1:x2:x3');
指定模型使用步骤行程和一个表或数据集数组TBL.预测器,假设您希望从常量开始并具有线性模型上限。假设响应变量TBL.命名为“y”,并且预测变量被命名“x1”那“x2”,“x3”。
mdl2 = stepwiselm(tbl,'y〜1'那'上'那“y~x1+x2+x3”);
适合数据
适合的最常见的可选论点:
例如,
mdl = fitlm(x,y,'线性'那......“RobustOpts”那'在'那'pationalvars',3);mdl2=逐步LM(待定,“常数”那......'responsevar'那'mpg'那'上'那'二次');
检查质量,调整拟合模型
拟合模型后,检查结果并进行调整。
模型显示
当您输入名称或进入时,线性回归模型显示了多种诊断DISP(MDL)。此显示给出了一些基本信息,以检查拟合模型是否充分代表数据。
例如,将线性模型适合与未存在的五个预测器中的两个且没有截距术语的数据构建的数据:
x = randn(100,5);y = x * [1; 0; 3; 0; -1] + RANDN(100,1);mdl = fitlm(x,y)
MDL =线性回归模型:Y〜1 + x1 + x2 + x3 + x4 + x5估计系数:估计系数pvalue _________ ________________________0.75264 0.45355 x3 2.8965 0.099879 29 1.1117E-48 x 4 0.04531 0.045311 0.04531 0.11708 0.41831 0.11708 0.41831 0.67667 0.67667 0.67667 0.67667 0.67667 0.67667 0.67667 0.67667 x 5 -0.97667 x 5 -0.97667 x 5 -4504 3.5930-13观察数:100,误差自由度:94根均匀误差:0.972 R线:0.93,调整0.93R-Squared:0.926 F统计与常数型号:248,P值= 1.5E-52
请注意:
显示中包含每个系数的估计值
估计列。这些值相当接近真实值[0, 1, 0; 3, 0, 1]。系数估计有一个标准误差列。
报道
pValue(衍生自T.统计数据(Tstat.)在正常误差的假设下,用于预测器1,3和5非常小。这些是用于创建响应数据的三个预测因子y。这
pValue为了(截取)那x2和x4远远大于0.01。这三个预测因子未用于创建响应数据y。显示屏包含 ,调整 ,F统计数据。
Anova.
检查拟合型号的质量,请咨询ANOVA表。例如,使用方差分析在具有五个预测因子的线性模型上:
TBL = ANOVA(MDL)
TBL =.6×5表中国学生基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金会基金9940.94382
此表提供了比模型显示的结果不同。该表清楚地表明了效果x2和x4不重要。根据你的目标,考虑移除。x2和x4来自模型。
诊断情节
诊断绘图可帮助您识别异常值,并查看模型中的其他问题或适合。例如,加载Carsmall.数据,并制作一个模型MPG作为…的函数圆筒(分类)和重量:
加载Carsmall.TBL =桌子(重量,MPG,圆柱体);tbl.cylinders =分类(tbl.cylinders);mdl = fitlm(tbl,'MPG ~气缸*重量+重量^2');
制作数据和模型的杠杆图。
绘图诊断(mdl)
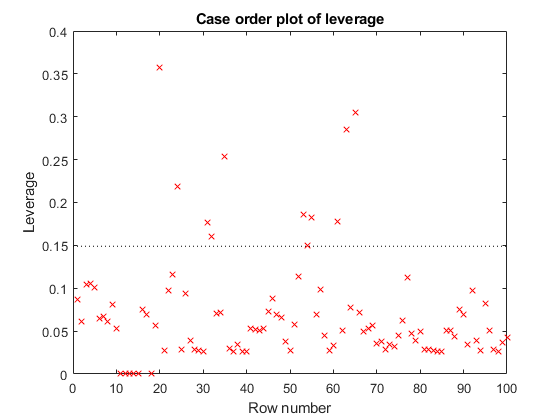
杠杆率有几点。但这剧情没有透露高杠杆点是否是异常值。
寻找库克距离较大的点。
plotDiagnostics(mdl,'cookd')

厨师距离有一点。识别它并从模型中删除它。您可以使用数据光标单击异常值并标识它,或以编程方式标识:
[〜,larg] = max(mdl.diagnostics.cooksdistance);mdl2 = fitlm(tbl,'MPG ~气缸*重量+重量^2'那'排除', larg);
残差-训练数据的模型质量
有几块剩余曲线可以帮助您发现模型或数据中的错误,异常值或相关性。最简单的剩余曲线是默认的直方图图,其显示了残差及其频率的范围,以及概率图,概率图显示了残差的分布方式与具有匹配方差的正态分布。
检验残差:
plotResiduals (mdl)

高于12的观察结果是潜在的异常值。
plotResiduals (mdl“概率”)

这两个潜在的异常值也出现在此情节上。否则,概率绘图似乎是合理的,这意味着合理适合通常分布的残留物。
您可以识别两个异常值并从数据中删除它们:
概述=查找(mdl.residuals.raw> 12)
概述=2×190 97.
要删除异常值,请使用排除名称-值对:
mdl3 = fitlm(资源描述,'MPG ~气缸*重量+重量^2'那'排除',概略);
检查MDL2的残差情节:
plotresids(MDL3)

新的残差绘图看起来相当对称,没有明显的问题。然而,残差可能存在一些串行相关性。创建一个新的曲线,以查看是否存在此类效果。
plotresids(MDL3,'滞后')

散点图显示右上象限和左下象限的交叉比其他两个象限多,表明残差之间存在正的序列相关性。
另一个潜在问题是当残留物大对于大型观察较大时。看看当前模型是否具有此问题。
plotresids(MDL3,“合适的”)
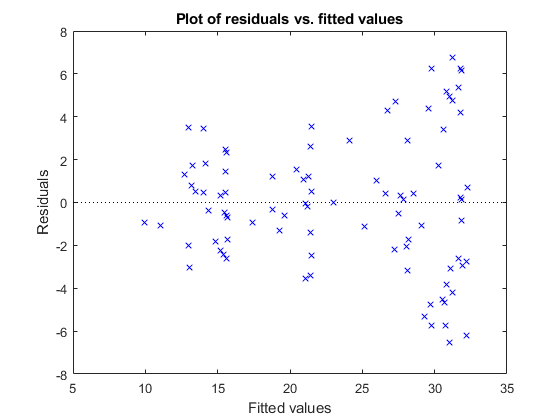
较大的拟合值有较大的残差趋势。也许模型误差与测量值成正比。
绘制预测因素效应
这个例子展示了如何使用各种可用的图来理解每个预测器对回归模型的影响。
检查响应的切片图。这分别显示了每个预测器的效果。
plotSlice(mdl)

您可以拖动单个预测值,这些值由蓝色虚线表示。您还可以在同时置信范围和非同时置信范围之间进行选择,它们由红色虚线表示。
使用效果图显示预测因子对响应影响的另一个视图。
栅格缺点(MDL)
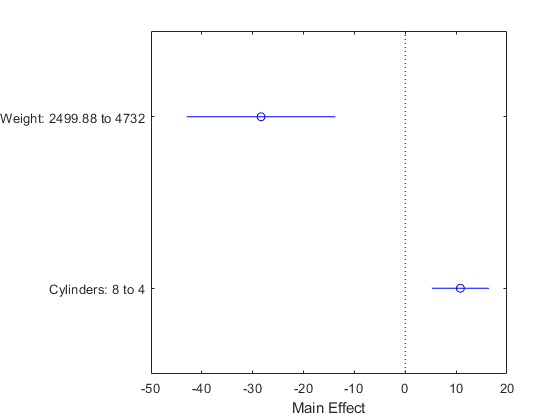
这个曲线表明改变了重量从大约2500到4732降低MPG大约30(上面蓝色圆圈的位置)。它还表明,将气缸数从8个改变为4个会提高MPG大约10(较低的蓝色圆圈)。水平蓝线代表这些预测的置信区间。当另一个改变时,预测来自一个预测器的平均值。在诸如此之类的情况下,在两个预测器相关的情况下,在解释结果时要小心。
除了改变另一个改变时,代替观察平均在预测器上的效果,请检查相互作用图中的关节相互作用。
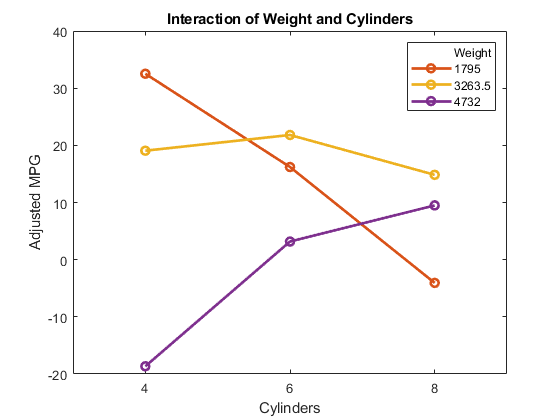
plotInteraction (mdl“重量”那“汽缸”)

相互作用图显示了改变一个预测器与另一个固定的效果的效果。在这种情况下,绘图更有信息。例如,显示了降低相对轻的汽车中的汽缸数量(重量= 1795)导致里程增加,但降低了相对较重的汽车中的汽缸数量(重量= 4732)导致里程减少。
为了更详细地查看交互,请查看具有预测的交互曲线。该曲线在改变另一个时固定一个预测器,并将效果作为曲线绘制。看看各种固定数量的圆柱体的交互。
plotInteraction (mdl“汽缸”那“重量”那“预测”)
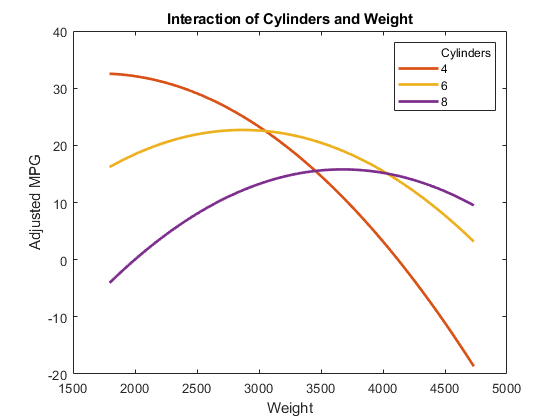
现在看看与各种固定水平的重量相互作用。
plotInteraction (mdl“重量”那“汽缸”那“预测”)
绘制术语效果
此示例显示如何使用各种可用的图来了解回归模型中每个术语的效果。
创建一个添加的可变图形体重^ 2作为添加的变量。
已添加绘图(mdl,'重量^2')
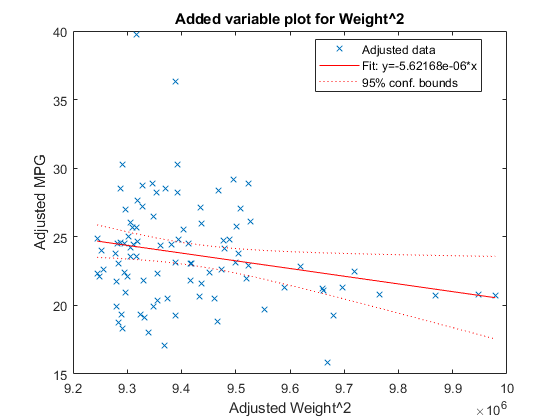
这张图显示了两者的拟合结果体重^ 2和MPG除了体重^ 2.使用的理由绘图仪是要了解您通过添加的模型的额外改进体重^ 2。符合这些点的线的系数是系数体重^ 2在完整的模型中。这体重^ 2预测器只是在重要性的边缘(pValue<0.05),如您在系数表显示中所见。你也可以在情节中看到这一点。置信区间看起来不能包含水平线(常数)y),因此零斜率模型与数据不一致。
为整体创建模型的添加变量绘图。
plotadded(mdl)

整个模型非常重要,因此界限不会靠近包含水平线。该线的斜率是拟合倾斜的斜率,预测器突出到其最佳拟合方向上,或换句话说,系数矢量的标准。
改变模型
有两种方法可以改变模型:
如果您使用的是使用型号步骤行程, 然后步只有当您提供不同的上层或下模型时,才能产生效果。步使用模型时不起作用抢劫案。
例如,从里程的线性模型开始卡比格数据:
加载卡比格TBL =表(加速,位移,马力,重量,MPG);mdl = fitlm(tbl,'线性'那'responsevar'那'mpg')
mdl=线性回归模型:MPG~1+加速度+位移+马力+重量估计系数:估计当前pValue uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(截距)45.251 2.456 18.424 7.0721e-55加速度-0.023148 0.1256-0.1843 0.85388位移-0.0060009 0.0067093-0.89441 0.37166马力-0.043608 0.016573-2.6312 0.008849重量-0.0052805 0.00081085-6.5123 2.3025e-10观测次数:392,误差自由度:387均方根误差:4.25 R平方:0.707,经调整的R平方:0.704 F-统计与常数模型:233,p-值=9.63e-102
尝试使用最多10个步骤改进模型:
mdl1 =步骤(mdl,'nsteps',10)
1.添加位移:马力,FSTAT = 87.4802,pvalue = 7.05273e-19
MDL1 =线性回归型号:MPG〜1 +加速+重量+位移*马力估计系数:估算系数PVALUE __________ ________________ ____________1052 21.010071 0.010071 - 0.03945/0.0100718.0623 9.5014E-15马力-0.24313 0.026068 -9重量-0.0014367 0.00084041 -1.7095 0.08041 -1.7095 0.088166位移:马力0.00054236 5.7987E-05 9.3531 7.3531 7.0527E -19观察数:392,误差自由度:386根均匀误差:3.84 R线:0.761,调整R线:0.758 F统计与常数型号:246,P值= 1.32E-117
步在一次改变之后停止了。
要尝试简化模型,请删除加速度和重量术语从mdl1:
mdl2 = removeTerms (mdl1,“加速+重量”)
mdl2 =线性回归模型:MPG ~ 1 +排量*马力估计系数:Estimate SE tStat pValue __________ _________ _______ ___________ (Intercept) 53.051 1.526 34.765 3.0201e-121位移-0.098046 0.0066817 -14.674 4.3203e-39马力-0.23434 0.019593 -11.96 2.8024e-28位移:马力388均方根误差:3.94 r平方:0.747,调整r平方:0.745 f统计量与常数模型:381,p-value = 3e-115
mdl2仅使用取代和马力,与数据的拟合度几乎与mdl1在里面调整的R角公制。
预测或模拟对新数据的响应
一种linearmodel.对象提供三个函数来预测或模拟对新数据的响应:预测那Feval.,随机的。
预测
使用预测为了预测和获得预测的置信区间的功能。
加载卡比格数据并创建响应的默认线性模型MPG到加速度那取代那马力,重量预测因子。
加载卡比格X = [加速,位移,马力,重量];mdl = fitlm(x,mpg);
从最小,平均值和最大值创建三行的预测器数组。X包含一些南值,因此使用忽略的函数南价值观。
Xnew = [nanmin (X); nanmean (X); nanmax (X));
查找预测的模型响应和预测上的置信区间。
[NewMPG,NewMPGCI]=预测(mdl,Xnew)
newmpg =3×134.1345 23.4078 4.7751
newmpgci =3×231.6115 36.6575 22.9859 23.8298 0.6134 8.9367
在平均反应上的置信度窄于最小或最大响应的信心。
Feval.
使用Feval.功能来预测反应。当您从表或数据集数组创建模型时,Feval.通常比较方便预测预测反应。当您有新的预测数据时,您可以将它传递给Feval.无需创建表或矩阵。然而,Feval.不提供信心范围。
加载卡比格数据集并创建响应的默认线性模型MPG的预测因素加速度那取代那马力,重量。
加载卡比格TBL =表(加速,位移,马力,重量,MPG);mdl = fitlm(tbl,'线性'那'responsevar'那'mpg');
预测预测器的平均值的模型响应。
newmpg = feval(MDL,纳米(加速),纳米(位移),纳米(马力),纳米(重量))
newmpg = 23.4078.
随机的
使用随机的模拟响应的功能。这随机的功能模拟新的随机响应值,等于平均预测加上随机干扰与训练数据相同的差异。
加载卡比格数据并创建响应的默认线性模型MPG到加速度那取代那马力,重量预测因子。
加载卡比格X = [加速,位移,马力,重量];mdl = fitlm(x,mpg);
从最小,平均值和最大值创建三行的预测器数组。
Xnew = [nanmin (X); nanmean (X); nanmax (X));
生成新的预测模型响应,包括某种随机性。
RNG('默认')重复性的%Xnew NewMPG =随机(mdl)
newmpg =3×136.4178 31.1958 -4.8176
因为MPG似乎不明智,尝试再次预测两次。
Xnew NewMPG =随机(mdl)
newmpg =3×137.7959 24.7615 -0.7783
Xnew NewMPG =随机(mdl)
newmpg =3×132.2931 24.8628 19.9715
显然,第三个(最大)行的预测Xnew.它们不可靠。
共享拟合模型
假设您有一个线性回归模型,例如mdl从以下命令。
加载卡比格TBL =表(加速,位移,马力,重量,MPG);mdl = fitlm(tbl,'线性'那'responsevar'那'mpg');
要与他人分享模型,您可以:
提供模型显示。
mdl
mdl=线性回归模型:MPG~1+加速度+位移+马力+重量估计系数:估计当前pValue uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(截距)45.251 2.456 18.424 7.0721e-55加速度-0.023148 0.1256-0.1843 0.85388位移-0.0060009 0.0067093-0.89441 0.37166马力-0.043608 0.016573-2.6312 0.008849重量-0.0052805 0.00081085-6.5123 2.3025e-10观测次数:392,误差自由度:387均方根误差:4.25 R平方:0.707,经调整的R平方:0.704 F-统计与常数模型:233,p-值=9.63e-102
提供模型定义和系数。
mdl.formula.
ANS = MPG〜1 +加速+位移+马力+重量
MDL.Coeffitynames.
ans =1x5细胞第1列到第4列{'(截距)}{'加速度'}{'位移'}{'马力'}第5列{'重量'}
mdl.cofficients.Estimate
ans =5×145.2511 -0.0231 -0.0060 -0.0436 -0.0053
也可以看看
linearmodel.|方差分析|Fitlm.|套索|plotresivs|预测|序列|步骤行程
相关话题
你也可以从以下列表中选择一个网站:
