主要内容
随机子空间分类
此示例显示如何使用随机子空间集合来提高分类的准确性。它还展示了如何使用交叉验证来确定弱学习模板和集合的良好参数。
加载数据
加载电离层数据。该数据对34个预测因子有351个二进制响应。
负载电离层;[N、D] =大小(X)
n = 351.
D = 34
resp =独特(Y)
resp =2 x1细胞{b} {' g '}
选择最近邻居的数量
找到一个不错的选择k,通过交叉验证确定分类器中最近邻的数量。选择在对数尺度上近似均匀间隔的邻居数量。
rng (8000“旋风”)%的再现性K =圆(logspace (0 log10 (N) 10));邻居数量%cvloss = 0(元素个数(K), 1);为k=1:numel(k) knn = fitcknn(X,Y,...“NumNeighbors”, K (K),“CrossVal”,“上”);cvloss (k) = kfoldLoss(资讯);结束图;绘制精度与k的对比图semilogx(k,cvloss);Xlabel(“最近邻居的数目”);ylabel ('10折叠分类错误');标题(“事例分类”);
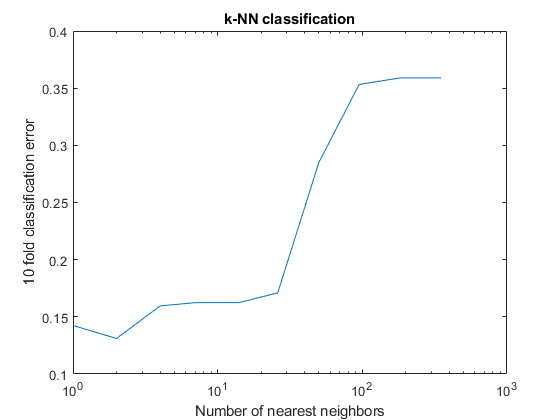
最低的交叉验证错误发生在k = 2.
创建一个集合体
创建集合体2- 使用各种维度的邻居分类,并检查所得合奏的交叉验证丢失。
这一步需要很长时间。要跟踪进度,请在每个维度结束时打印一条消息。
npredtosample =圆形(Linspace(1,D,10));%尺寸的线性间距cvloss =零(numel(npredtosample),1);学习者= templateknn(“NumNeighbors”2);为npred=1:numel(NPredToSample) subspace = fitcensemble(X,Y, X)“方法”,'子空间',“学习者”学习者,...'npredtosample'NPredToSample (npr),“CrossVal”,“上”);cvloss (npr) = kfoldLoss(子空间);流('Random Subspace %i done.\n'美国国家公共电台);结束
随机子空间1完成。随机子空间2完成了。随机子空间3完成。随机子空间4完成。随机子空间5完成。随机子空间6完成。随机子空间7完成。随机子空间8完成。随机子空间9完成。随机子空间10完成。
图;%绘制精度与维度情节(NPREDTOSAMPLE,CVLOSS);Xlabel(“随机选择的预测器数”);ylabel ('10折叠分类错误');标题(基于随机子空间的k-NN分类);
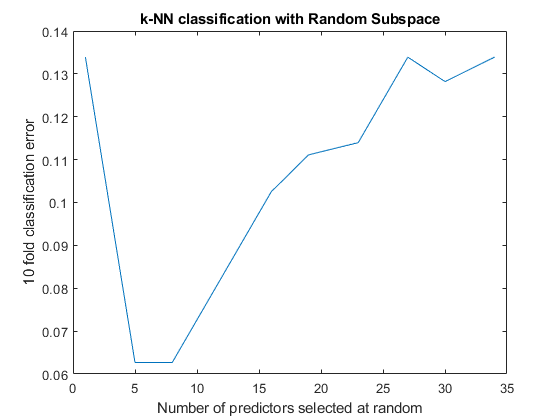
每个学习者使用5个或8个预测因子的集合具有最低的交叉验证误差。这些集合的错误率约为0.06,而其他集合的交叉验证错误率约为0.1或更多。
找一个合适的整体尺寸
在集合中找出最小数量的仍然能给出好的分类的学习者。
ens = fitcensemble(x,y,“方法”,'子空间',“学习者”学习者,...'npredtosample',5,“CrossVal”,“上”);图;%绘制精度与数字在整体情节(kfoldLoss(实体,“模式”,“累积”))xlabel(“学生人数”);ylabel ('10折叠分类错误');标题(基于随机子空间的k-NN分类);
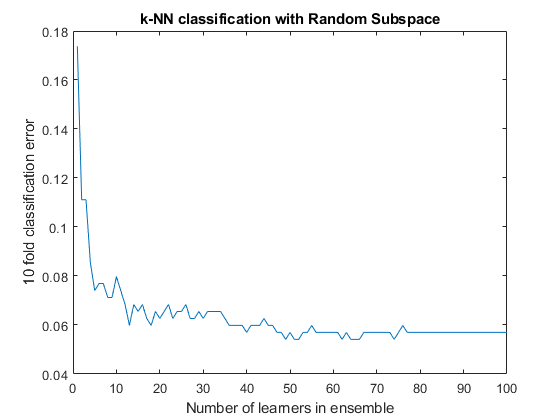
一个超过50人的合唱团似乎没有什么优势。25个学习者有可能做出好的预测。
创建最终集成
与50名学习者组成最后的合奏。压缩集成,看看压缩版本是否节省了可观的内存。
ens = fitcensemble(x,y,“方法”,'子空间',“NumLearningCycles”, 50岁,...“学习者”学习者,'npredtosample'5);岑=紧凑(ens);s1 =谁(“实体”);s2 =谁('CENS');[s1.bytes s2.bytes]%如果。Bytes =以字节为单位的大小
ans =1×21748467 1518820
紧凑的集合比完整的集合小10%左右。两者给出了相同的预测。
另请参阅
紧凑|fitcensemble|fitcknn|kfoldLoss|templateknn.
相关主题
您还可以从以下列表中选择一个网站:
