强大的功能选择使用NCA的回归
执行特征选择是稳健的使用NCA定制稳健损失函数的异常值。
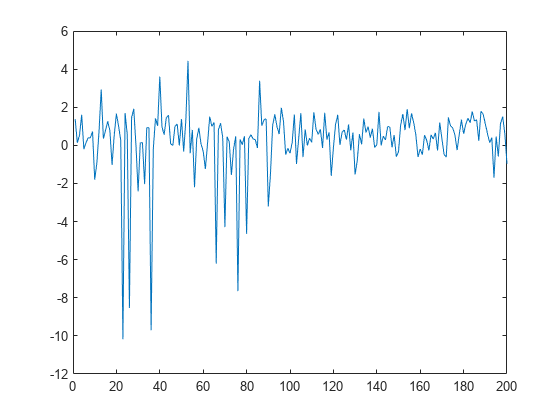
产生离群数据
生成的采样数据进行回归,其中响应取决于三个预测器,即预测器4,图7和13。
rng (123“旋风”)%的再现性n = 200;X = randn (n, 20);y = cos (X (:, 7)) + sin (X (:, 4)。* X (:, 13)) + 0.1 * randn (n, 1);
向数据中添加异常值。
numoutliers = 25;outlieridx =地板(linspace(10,90,numoutliers));Y(outlieridx)= 5 * randn(numoutliers,1);
图中的数据。
图图(y)的
使用非稳健的损失函数
特征选择算法的性能在很大程度上取决于正则化参数的取值。一个好的实践是调整正则化参数,以获得在特性选择中使用的最佳值。使用五倍交叉验证调整正则化参数。使用均方误差(MSE):
首先,将数据划分为5重。在各个折叠,软件将使用4 /数据用于训练和第五进行验证(测试)1 /数据的第5位。
CVP = cvpartition(长度(Y),“kfold”5);numtestsets = cvp.NumTestSets;
计算λ值以测试和创建一个数组来存储损失值。
lambdavals = linspace(50 0 3) *性病(y) /长度(y);lossvals = 0(长度(lambdavals), numtestsets);
执行NCA和计算每个损失 价值和每个折叠。
为I = 1:长度(lambdavals)为K = 1:numtestsets Xtrain = X(cvp.training(K),:);ytrain = Y(cvp.training(K),:);XTEST = X(cvp.test(K),:);ytest = Y(cvp.test(K),:);NCA = fsrnca(Xtrain,ytrain,“FitMethod”,'精确',…“求解”,'lbfgs',“放牧”,0,“λ”,lambdavals(i)中,…“LossFunction”,'MSE');lossvals(I,K)=损失(NCA,XTEST,ytest,“LossFunction”,'MSE');结束结束
绘制每个值对应的平均损失。
figure meanloss = mean(loss svals,2);情节(lambdavals meanloss,“滚装”)xlabel(“λ”)ylabel(“损失(MSE)”)网格上
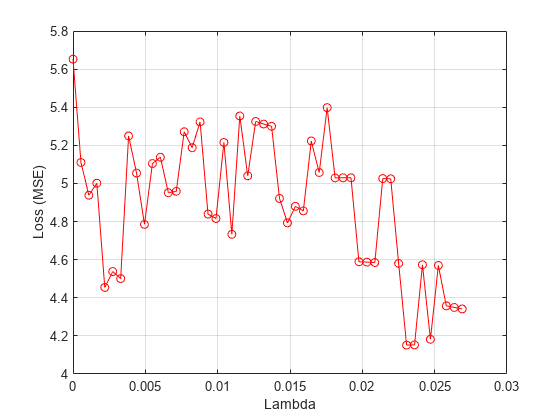
找出 产生最小平均损失的值。
[~,idx] = min(意味着(lossvals, 2));bestlambda = lambdavals (idx)
bestlambda = 0.0231
用最好的执行特征选择 值和MSE。
NCA = fsrnca(X,Y,“FitMethod”,'精确',“求解”,'lbfgs',…“放牧”1,“λ”bestlambda,“LossFunction”,'MSE');
ø求解= LBFGS,HessianHistorySize = 15,LineSearchMethod = weakwolfe | ==================================================================================================== ||ITER |FUN VALUE |NORM GRAD |NORM STEP |CURV |GAMMA |ALPHA |接受| |====================================================================================================| | 0 | 6.414642e+00 | 8.430e-01 | 0.000e+00 | | 7.117e-01 | 0.000e+00 | YES | | 1 | 6.066100e+00 | 9.952e-01 | 1.264e+00 | OK | 3.741e-01 | 1.000e+00 | YES | | 2 | 5.498221e+00 | 4.267e-01 | 4.250e-01 | OK | 4.016e-01 | 1.000e+00 | YES | | 3 | 5.108548e+00 | 3.933e-01 | 8.564e-01 | OK | 3.599e-01 | 1.000e+00 | YES | | 4 | 4.808456e+00 | 2.505e-01 | 9.352e-01 | OK | 8.798e-01 | 1.000e+00 | YES | | 5 | 4.677382e+00 | 2.085e-01 | 6.014e-01 | OK | 1.052e+00 | 1.000e+00 | YES | | 6 | 4.487789e+00 | 4.726e-01 | 7.374e-01 | OK | 5.593e-01 | 1.000e+00 | YES | | 7 | 4.310099e+00 | 2.484e-01 | 4.253e-01 | OK | 3.367e-01 | 1.000e+00 | YES | | 8 | 4.258539e+00 | 3.629e-01 | 4.521e-01 | OK | 4.705e-01 | 5.000e-01 | YES | | 9 | 4.175345e+00 | 1.972e-01 | 2.608e-01 | OK | 4.018e-01 | 1.000e+00 | YES | | 10 | 4.122340e+00 | 9.169e-02 | 2.947e-01 | OK | 3.487e-01 | 1.000e+00 | YES | | 11 | 4.095525e+00 | 9.798e-02 | 2.529e-01 | OK | 1.188e+00 | 1.000e+00 | YES | | 12 | 4.059690e+00 | 1.584e-01 | 5.213e-01 | OK | 9.930e-01 | 1.000e+00 | YES | | 13 | 4.029208e+00 | 7.411e-02 | 2.076e-01 | OK | 4.886e-01 | 1.000e+00 | YES | | 14 | 4.016358e+00 | 1.068e-01 | 2.696e-01 | OK | 6.919e-01 | 1.000e+00 | YES | | 15 | 4.004521e+00 | 5.434e-02 | 1.136e-01 | OK | 5.647e-01 | 1.000e+00 | YES | | 16 | 3.986929e+00 | 6.158e-02 | 2.993e-01 | OK | 1.353e+00 | 1.000e+00 | YES | | 17 | 3.976342e+00 | 4.966e-02 | 2.213e-01 | OK | 7.668e-01 | 1.000e+00 | YES | | 18 | 3.966646e+00 | 5.458e-02 | 2.529e-01 | OK | 1.988e+00 | 1.000e+00 | YES | | 19 | 3.959586e+00 | 1.046e-01 | 4.169e-01 | OK | 1.858e+00 | 1.000e+00 | YES | |====================================================================================================| | ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT | |====================================================================================================| | 20 | 3.953759e+00 | 8.248e-02 | 2.892e-01 | OK | 1.040e+00 | 1.000e+00 | YES | | 21 | 3.945475e+00 | 3.119e-02 | 1.698e-01 | OK | 1.095e+00 | 1.000e+00 | YES | | 22 | 3.941567e+00 | 2.350e-02 | 1.293e-01 | OK | 1.117e+00 | 1.000e+00 | YES | | 23 | 3.939468e+00 | 1.296e-02 | 1.805e-01 | OK | 2.287e+00 | 1.000e+00 | YES | | 24 | 3.938662e+00 | 8.591e-03 | 5.955e-02 | OK | 1.553e+00 | 1.000e+00 | YES | | 25 | 3.938239e+00 | 6.421e-03 | 5.334e-02 | OK | 1.102e+00 | 1.000e+00 | YES | | 26 | 3.938013e+00 | 5.449e-03 | 6.773e-02 | OK | 2.085e+00 | 1.000e+00 | YES | | 27 | 3.937896e+00 | 6.226e-03 | 3.368e-02 | OK | 7.541e-01 | 1.000e+00 | YES | | 28 | 3.937820e+00 | 2.497e-03 | 2.397e-02 | OK | 7.940e-01 | 1.000e+00 | YES | | 29 | 3.937791e+00 | 2.004e-03 | 1.339e-02 | OK | 1.863e+00 | 1.000e+00 | YES | | 30 | 3.937784e+00 | 2.448e-03 | 1.265e-02 | OK | 9.667e-01 | 1.000e+00 | YES | | 31 | 3.937778e+00 | 6.973e-04 | 2.906e-03 | OK | 4.672e-01 | 1.000e+00 | YES | | 32 | 3.937778e+00 | 3.038e-04 | 9.502e-04 | OK | 1.060e+00 | 1.000e+00 | YES | | 33 | 3.937777e+00 | 2.327e-04 | 1.069e-03 | OK | 1.597e+00 | 1.000e+00 | YES | | 34 | 3.937777e+00 | 1.959e-04 | 1.537e-03 | OK | 4.026e+00 | 1.000e+00 | YES | | 35 | 3.937777e+00 | 1.162e-04 | 1.464e-03 | OK | 3.418e+00 | 1.000e+00 | YES | | 36 | 3.937777e+00 | 8.353e-05 | 3.660e-04 | OK | 7.304e-01 | 5.000e-01 | YES | | 37 | 3.937777e+00 | 1.412e-05 | 1.412e-04 | OK | 7.842e-01 | 1.000e+00 | YES | | 38 | 3.937777e+00 | 1.277e-05 | 3.808e-05 | OK | 1.021e+00 | 1.000e+00 | YES | | 39 | 3.937777e+00 | 8.614e-06 | 3.698e-05 | OK | 2.561e+00 | 1.000e+00 | YES | |====================================================================================================| | ITER | FUN VALUE | NORM GRAD | NORM STEP | CURV | GAMMA | ALPHA | ACCEPT | |====================================================================================================| | 40 | 3.937777e+00 | 3.159e-06 | 5.299e-05 | OK | 4.331e+00 | 1.000e+00 | YES | | 41 | 3.937777e+00 | 2.657e-06 | 1.080e-05 | OK | 7.038e-01 | 5.000e-01 | YES | | 42 | 3.937777e+00 | 7.054e-07 | 7.036e-06 | OK | 9.519e-01 | 1.000e+00 | YES | Infinity norm of the final gradient = 7.054e-07 Two norm of the final step = 7.036e-06, TolX = 1.000e-06 Relative infinity norm of the final gradient = 7.054e-07, TolFun = 1.000e-06 EXIT: Local minimum found.
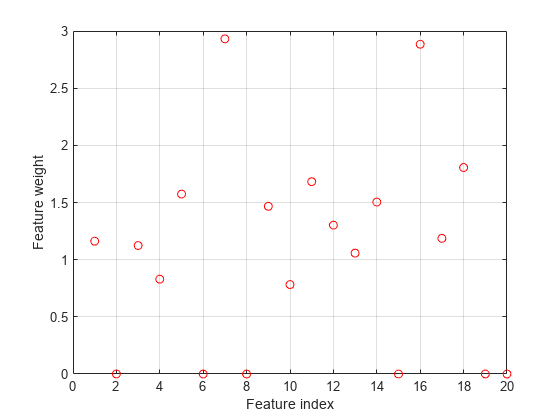
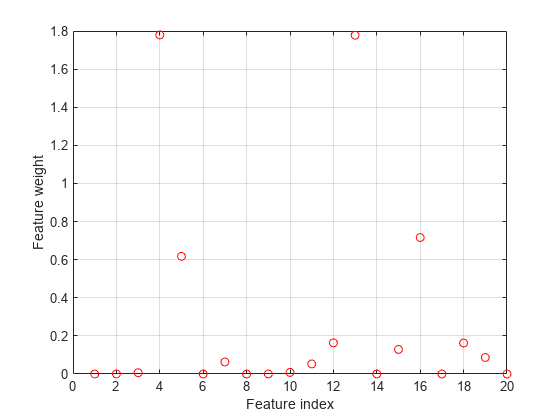
绘制选择功能。
图绘制(nca.FeatureWeights,“罗”)网格上xlabel(“功能指数”)ylabel(“特征权重”)
方法预测响应值NCA模拟并绘制拟合(预测)响应值和实际响应值。
图嵌合=预测(NCA,X);图(Y,“r”。)举行上积(安装,'B-')xlabel(“指数”)ylabel(“拟合值”)
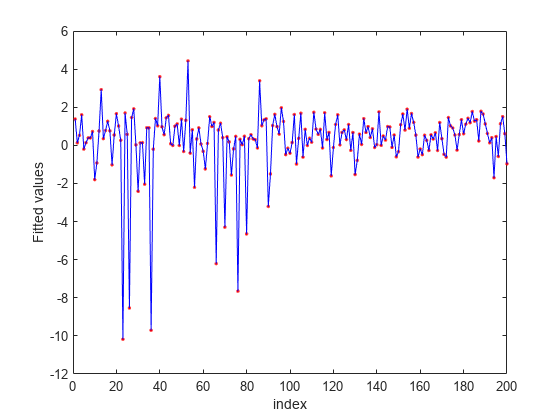
fsrnca试图以适应数据包括异常值的每一个点。其结果是它分配的非零权重的许多功能,除了预测4,7,和13。
使用内置健壮的损耗功能
重复调优正则化参数的相同过程,这次使用内置的 不敏感损失函数:
-不敏感损失函数对异常值的鲁棒性优于均方误差。
lambdavals = linspace(50 0 3) *性病(y) /长度(y);CVP = cvpartition(长度(Y),“kfold”5);numtestsets = cvp.NumTestSets;lossvals = 0(长度(lambdavals), numtestsets);为I = 1:长度(lambdavals)为K = 1:numtestsets Xtrain = X(cvp.training(K),:);ytrain = Y(cvp.training(K),:);XTEST = X(cvp.test(K),:);ytest = Y(cvp.test(K),:);NCA = fsrnca(Xtrain,ytrain,“FitMethod”,'精确',…“求解”,“sgd”,“放牧”,0,“λ”,lambdavals(i)中,…“LossFunction”,'epsiloninsensitive',‘ε’,0.8);lossvals(I,K)=损失(NCA,XTEST,ytest,“LossFunction”,'MSE');结束结束
的 使用的值取决于数据,也可以使用交叉验证来确定最佳值。但选择 值的本实施例的范围进行。的选择 在这个例子中,主要是用于说明该方法的鲁棒性。
绘制每个值对应的平均损失。
figure meanloss = mean(loss svals,2);情节(lambdavals meanloss,“滚装”)xlabel(“λ”)ylabel(“损失(MSE)”)网格上

找到产生最小平均损失的值。
[~,idx] = min(意味着(lossvals, 2));bestlambda = lambdavals (idx)
bestlambda = 0.0187
使用适合邻里成分分析模型 -不敏感的损失函数和最好的lambda值。
NCA = fsrnca(X,Y,“FitMethod”,'精确',“求解”,“sgd”,…“λ”bestlambda,“LossFunction”,'epsiloninsensitive',‘ε’,0.8);
绘制选择功能。
图绘制(nca.FeatureWeights,“罗”)网格上xlabel(“功能指数”)ylabel(“特征权重”)
绘制拟合值。
图嵌合=预测(NCA,X);图(Y,“r”。)举行上积(安装,'B-')xlabel(“指数”)ylabel(“拟合值”)
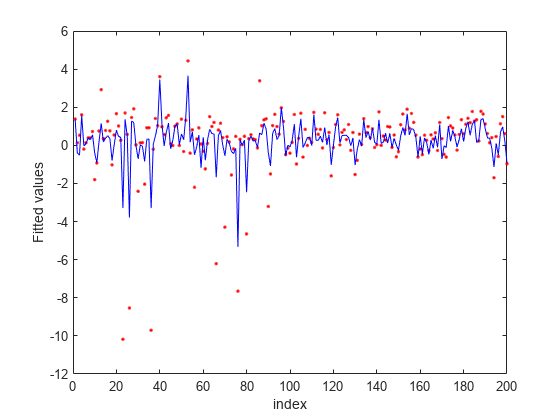
不敏感的损失似乎更稳健的异常值。它确定了比MSE作为相关的功能较少。拟合表明,它仍然受到一些异常值的影响。
使用自定义鲁棒损失函数
定义一个自定义鲁棒损失函数,该函数对异常值具有鲁棒性,可用于回归的特征选择:
customlossFcn = @(YI,YJ)1 - EXP(-abs(bsxfun(@减去,苡仁,YJ')));
使用自定义的鲁棒损失函数调整正则化参数。
lambdavals = linspace(50 0 3) *性病(y) /长度(y);CVP = cvpartition(长度(Y),“kfold”5);numtestsets = cvp.NumTestSets;lossvals = 0(长度(lambdavals), numtestsets);为I = 1:长度(lambdavals)为K = 1:numtestsets Xtrain = X(cvp.training(K),:);ytrain = Y(cvp.training(K),:);XTEST = X(cvp.test(K),:);ytest = Y(cvp.test(K),:);NCA = fsrnca(Xtrain,ytrain,“FitMethod”,'精确',…“求解”,'lbfgs',“放牧”,0,“λ”,lambdavals(i)中,…“LossFunction”,customlossFcn);lossvals(I,K)=损失(NCA,XTEST,ytest,“LossFunction”,'MSE');结束结束
绘制每个值对应的平均损失。
figure meanloss = mean(loss svals,2);情节(lambdavals meanloss,“滚装”)xlabel(“λ”)ylabel(“损失(MSE)”)网格上
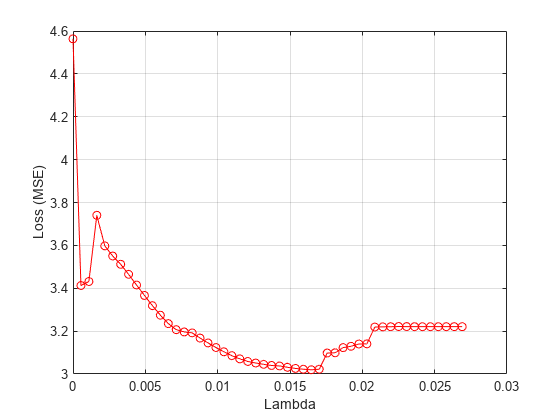
找出 产生最小平均损失的值。
[~,idx] = min(意味着(lossvals, 2));bestlambda = lambdavals (idx)
bestlambda = 0.0165
使用自定义鲁棒损失函数和best进行特征选择 价值。
NCA = fsrnca(X,Y,“FitMethod”,'精确',“求解”,'lbfgs',…“放牧”1,“λ”bestlambda,“LossFunction”,customlossFcn);
ø求解= LBFGS,HessianHistorySize = 15,LineSearchMethod = weakwolfe | ==================================================================================================== ||ITER |FUN VALUE |NORM GRAD |NORM STEP |CURV |GAMMA |ALPHA |接受| |====================================================================================================| | 0 | 8.610073e-01 | 4.921e-02 | 0.000e+00 | | 1.219e+01 | 0.000e+00 | YES | | 1 | 6.582278e-01 | 2.328e-02 | 1.820e+00 | OK | 2.177e+01 | 1.000e+00 | YES | | 2 | 5.706490e-01 | 2.241e-02 | 2.360e+00 | OK | 2.541e+01 | 1.000e+00 | YES | | 3 | 5.677090e-01 | 2.666e-02 | 7.583e-01 | OK | 1.092e+01 | 1.000e+00 | YES | | 4 | 5.620806e-01 | 5.524e-03 | 3.335e-01 | OK | 9.973e+00 | 1.000e+00 | YES | | 5 | 5.616054e-01 | 1.428e-03 | 1.025e-01 | OK | 1.736e+01 | 1.000e+00 | YES | | 6 | 5.614779e-01 | 4.446e-04 | 8.350e-02 | OK | 2.507e+01 | 1.000e+00 | YES | | 7 | 5.614653e-01 | 4.118e-04 | 2.466e-02 | OK | 2.105e+01 | 1.000e+00 | YES | | 8 | 5.614620e-01 | 1.307e-04 | 1.373e-02 | OK | 2.002e+01 | 1.000e+00 | YES | | 9 | 5.614615e-01 | 9.318e-05 | 4.128e-03 | OK | 3.683e+01 | 1.000e+00 | YES | | 10 | 5.614611e-01 | 4.579e-05 | 8.785e-03 | OK | 6.170e+01 | 1.000e+00 | YES | | 11 | 5.614610e-01 | 1.232e-05 | 1.582e-03 | OK | 2.000e+01 | 5.000e-01 | YES | | 12 | 5.614610e-01 | 3.174e-06 | 4.742e-04 | OK | 2.510e+01 | 1.000e+00 | YES | | 13 | 5.614610e-01 | 7.896e-07 | 1.683e-04 | OK | 2.959e+01 | 1.000e+00 | YES | Infinity norm of the final gradient = 7.896e-07 Two norm of the final step = 1.683e-04, TolX = 1.000e-06 Relative infinity norm of the final gradient = 7.896e-07, TolFun = 1.000e-06 EXIT: Local minimum found.
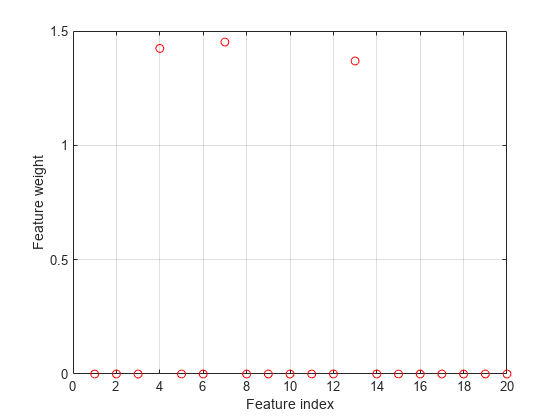
绘制选择功能。
图绘制(nca.FeatureWeights,“罗”)网格上xlabel(“功能指数”)ylabel(“特征权重”)
绘制拟合值。
图嵌合=预测(NCA,X);图(Y,“r”。)举行上积(安装,'B-')xlabel(“指数”)ylabel(“拟合值”)

在这种情况下,损失不会受异常值和结果是基于大多数观测值的。fsrnca检测预测4,图7和13作为相关特征,并且不选择任何其他功能。
为什么损失函数的选择会影响结果?
首先,计算损失函数为两个观察之间的差的值系列。
δy = linspace (-10, 1000);
计算自定义损失函数值。
customlossvals = customlossFcn(DELTAY,0);
计算不敏感损失函数和值。
epsinsensitive = @(YI,YJ,E)MAX(0,ABS(bsxfun(@减去,苡仁,YJ')) - E);epsinsenvals = epsinsensitive(DELTAY,0,0.5);
计算MSE损失函数和值。
MSE = @(YI,YJ)(YI-YJ')^ 2。msevals = MSE(DELTAY,0);
现在,画出损失函数,看看它们的区别,以及为什么它们会影响结果。
图图(DELTAY,customlossvals,“g -”δy epsinsenvals,'B-',DELTAY,msevals,的r -)xlabel(“(yi - yj)”)ylabel(“损失(咦,yj)”)传说(“customloss”,'epsiloninsensitive','MSE'20)ylim ([0])
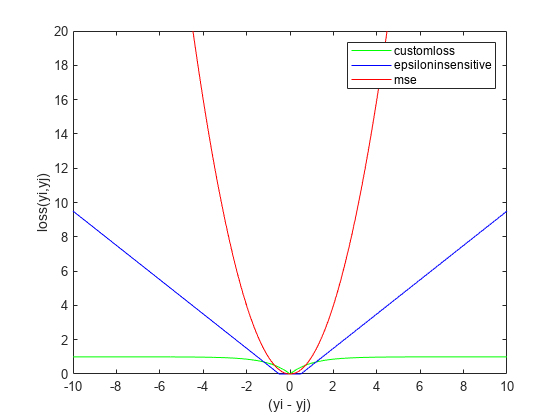
随着两个响应值之差的增大,mse呈二次增大,这使得它对异常值非常敏感。作为fsrnca为了尽量减少这种损失,最终会识别出更多相关的特性。与mse相比,epsilon不敏感损失对离群值的抵抗能力更强,但最终它确实开始随着两个观测值之差的增大而线性增大。当两个观测值之间的差值增大时,鲁棒损失函数确实趋近于1并保持在该值,即使观测值之间的差值不断增大。在三种模型中,它对异常值的鲁棒性最强。
另请参阅
FeatureSelectionNCARegression|fsrnca|失利|预测|改装
