适合
计算查询点的Shapley值
描述
新索引=健康(讲解员,queryPoint)queryPoint),并将计算得到的Shapley值存储在ShapleyValues的属性新索引.的沙普利对象讲解员包含机器学习模型和计算福利值的选项。
适合使用创建时指定的Shapley值计算选项讲解员.的名称-值参数可以更改选项适合函数。函数返回沙普利对象新索引包含新计算的福利值。
新索引=健康(讲解员,queryPoint,名称,值)“UseParallel”,真的并行计算Shapley值。
例子
创建沙普利对象和计算福利值适合
训练一个回归模型并创建一个沙普利对象。当你创建沙普利对象,如果未指定查询点,则软件不会计算福利值。使用对象功能适合来计算指定查询点的Shapley值。然后使用对象函数创建Shapley值的柱状图情节.
加载carbig数据集,其中包含在20世纪70年代和20世纪80年代初进行的汽车测量。
负载carbig
创建包含预测器变量的表加速度,气缸等等,以及响应变量MPG..
台=表(加速度、汽缸、排量、马力、Model_Year重量,MPG);
在培训集中删除缺失值可以帮助减少内存消耗并加速培训Fitrkernel.函数。删除缺失的值TBL..
tbl = rmmissing(tbl);
训练一个黑匣子模型MPG.通过使用Fitrkernel.函数
RNG('默认')重复性的%mdl = fitrkernel(tbl,“英里”,“CategoricalPredictors”[2 - 5]);
创建一个沙普利对象。指定数据集TBL.,因为mdl不包含培训数据。
讲解员=沙普利(mdl(资源)
explainer = shapley with properties: BlackboxModel: [1x1 RegressionKernel] QueryPoint: [] BlackboxFitted: [] ShapleyValues: [] NumSubsets: 64 X: [392x7 table] CategoricalPredictors: [2 5] Method: ' interinteral -kernel'
讲解员存储训练数据TBL.在里面X财产。
计算所有预测变量的福音值,以获得第一次观察TBL..
: queryPoint =(资源(1)
queryPoint =表1×7加速气缸位移马力Model_Year体重MPG ____________ _________ ____________ __________ __________ ______ ___ 12 8 307 130 70 3504
讲解员=适合(讲解员,queryPoint);
对于回归模型,沙普利使用预测的响应计算福利值,并将它们存储在ShapleyValues财产。中的值显示ShapleyValues财产。
讲解员。ShapleyValues
ans =.6×2表预测器ShapleyValue ______________ ____________“加速度”-0.1561“气缸”-0.18306“位移”-0.34203“马力”-0.27291“Model_Year”-0.2926“重量”-0.32402
控件显示查询点的预测响应,并绘制查询点的Shapley值情节函数。要在任何预测器名称中显示现有的下划线,请更改TickLabelInterpreter坐标轴的值“没有”.
讲解员。BlackboxFitted
ans = 21.0495
f =数字;绘图(解释器)f.currentaxes.ticklabelinterpreter =“没有”;
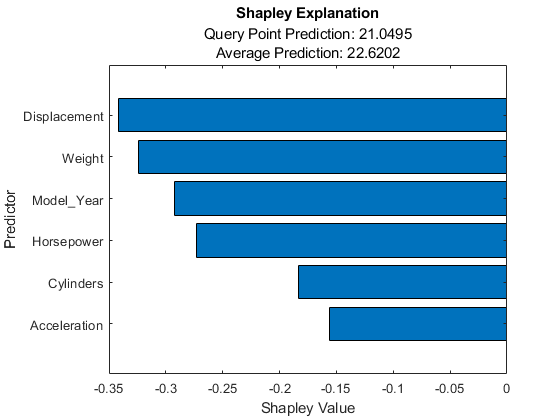
水平条图显示了所有变量的福音值,按其绝对值排序。由于相应的变量,每个福族值解释了从平均值到平均值的查询点的偏差。
计算多个查询点的Shapley值
训练分类模型并创建沙普利对象。然后计算多个查询点的Shapley值。
加载Creditrating_Historical.数据集。该数据集包含客户id及其财务比率、行业标签和信用评级。
台= readtable (“CreditRating_Historical.dat”);
使用的方法训练信用评级的黑箱模型fitcecoc函数。使用从第二列到第七列的变量TBL.作为预测变量。
黑箱= fitcecoc(资源描述,“评级”,...“PredictorNames”,tbl.properties.variablenames(2:7),...“CategoricalPredictors”,“行业”);
创建一个沙普利对象与之黑箱模型。为了更快的计算,将25%的观测数据从TBL.并使用样本来计算Shapley值。指定使用kernelSHAP算法的扩展。
RNG('默认')重复性的%c = cvpartition(资源描述。评级,“坚持”,0.25);tbl_s = tbl(测试(c),:);解释者=福利(Blackbox,Tbl_s,“方法”,“conditional-kernel”);
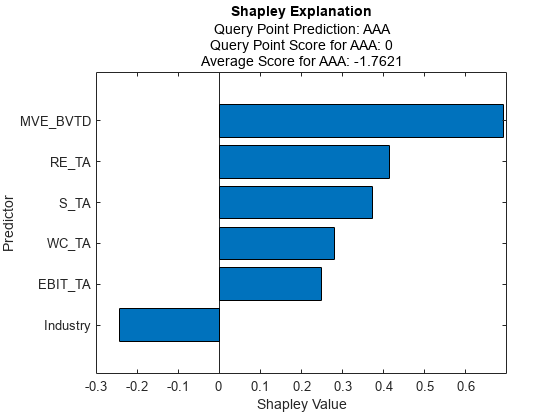
查找其真实评级值为的两个查询点AAA和B,分别。
queryPoint (1) =: tbl_(找到(strcmp (: tbl_。评级,“AAA”),1),:);querypoint(2,:) = tbl_s(find(strcmp(tbl_s.rating,“B”), 1),:)
queryPoint =2×8表ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA行业评级 _____ ______ ______ _______ ________ _____ ________ _______ 58258 0.511 0.869 0.106 8.538 0.732 - 2 {' AAA '} 82367 -0.078 -0.042 0.011 0.262 0.167 7 {B}
计算并绘制第一个查询点的Shapley值。要在任何预测器名称中显示现有的下划线,请更改TickLabelInterpreter坐标轴的值“没有”.
explainer1 =适合(讲解员,queryPoint (1:));f1 =图;情节(explainer1) f1.CurrentAxes。TickLabelInterpreter =“没有”;
计算并绘制第二个查询点的福音值。
explainer2 =适合(讲解员,queryPoint (2:));f2 =图;情节(explainer2) f2.CurrentAxes。TickLabelInterpreter =“没有”;
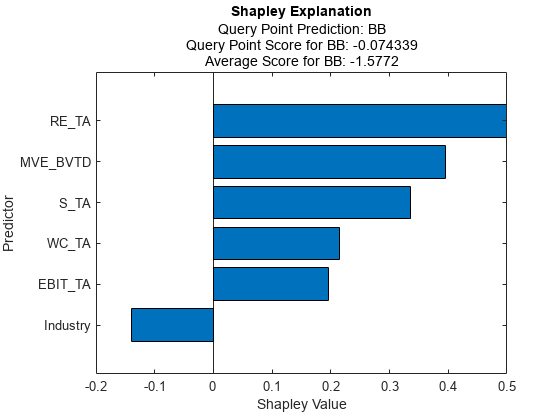
第二个查询点的真实评级是B,但预测的评级是BB.图中显示了预测评级的Shapley值。
explainer1和explainer2包括分别为第一个查询点和第二查询点的福音值。
输入参数
输出参数
更多关于
参考
扩展功能
你也可以从以下列表中选择一个网站:
