主要内容
并行列车分类集合
此示例显示如何并行训练分类集合。该模型具有十个红色和十个绿色基地,以及通常分布在基地的红色和绿色群体。目标是根据其位置对点进行分类。这些分类是模糊的,因为某些基地位于其他颜色的位置。
创建并绘制每种颜色的10个基地位置。
rng默认%的再现性GRNPOP = MVNRND([1,0],眼睛(2),10);Redpop = mvnrnd([0,1],眼睛(2),10);绘图(GRNPOP(:,1),GRNPOP(:,2),'走')举行在情节(redpop (: 1) redpop (:, 2),'ro')举行离开
在随机基点以每种颜色创建40,000点。
n = 40000;Redpts =零(n,2); grnpts = redpts;为了i = 1:n gnpts(i,:) = mvnrnd(grnpop(randi(10),:),眼睛(2)* 0.02);redpts(i,:) = mvnrnd(Redpop(randi(10),:),眼睛(2)* 0.02);结尾图绘图(GNPTS(:,1),GRNPTS(:2),'走')举行在绘图(已删除(:,1),已删除(:,2),'ro')举行离开
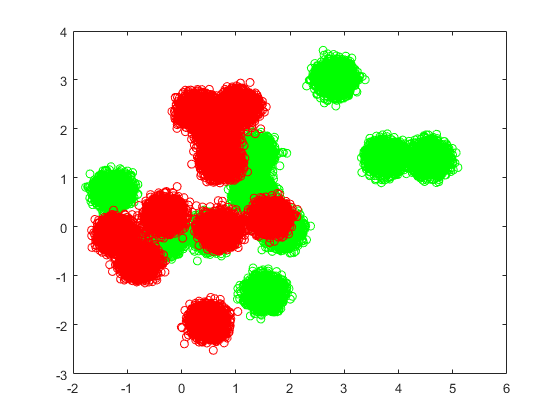
cdata = [grnpts; redpts];GRP = ONE(2 * N,1);%绿色标签1,红色标签-1GRP(n + 1:2 * n)= -1;
适合数据的袋装分类。有关并行培训的比较,请在串行中拟合集合并返回培训时间。
tic mdl = fitcensemble(cdata,grp,'方法'那“包”);stime = toc.
Stime = 9.0782.
评估拟合型号的袋装损失。
myerr = oobbloss(mdl)
Myerr = 0.0572.
使用可重复的树模板和并行子流并行创建袋装分类模型。您可以在集群上创建一个并行池或本地计算机上的线程工作台的并行池。要选择适当的并行环境,请参阅在基于线程和基于过程的环境之间进行选择。
parpool.
使用“本地”配置文件启动并行池(Parpool)连接到并行池(工人数:6)。
ANS = ProcessPool具有属性:Connected:True NumWorkers:6群集:本地连接文件:{} autoaddclientPath:true idledimeout:30分钟(剩余30分钟)spmded:true
s = randstream('MRG32K3A');选项= statset(“使用adPlall”,真的,“userubstreams”,真的,“溪流”,s);t = templatetree(“可重复”,真的);tic mdl2 = fitcensemble(cdata,grp,'方法'那“包”那'学习者',t,'选项',选项);ptime = toc.
Ptime = 6.2527
在这个六核系统上,并行培训过程更快。
speedup = stime / ptime
Speedup = 1.4519
评估此模型的袋袋损失。
myerr2 = oobLoss (mdl2)
myerr2 = 0.0577
错误率与第一个模型的错误率相似。
为了演示模型的重现性,重置随机数流并再次拟合模型。
重置;tic mdl2 = fitcensemble(cdata,grp,'方法'那“包”那'学习者',t,'选项',选项);TOC.
经过时间为3.953355秒。
检查丢失与之前的损失相同。
myerr2 = oobLoss (mdl2)
myerr2 = 0.0577
也可以看看
相关的话题
您还可以从以下列表中选择一个网站:
