余弦
与余弦相似度的文档相似度
句法
描述
例子
文档之间的相似性
创建一系列令牌化文件。
textdata = [“快速的棕色狐狸跳过了懒狗”“快速的棕色狐狸跳过懒狗”“懒狗坐在那里,没有什么”“其他动物坐在那里看着”];文档= tokenizeddocument(textdata)
文档= 4x1令牌Document:9令牌:快速的棕色狐狸跳过懒狗9令牌:快速的棕色狐狸跳过懒狗8令牌:懒狗坐在那里,没有什么6令牌:其他动物坐在那里看
计算它们之间的相似之处余弦功能。输出是稀疏矩阵。
相似之处= CasineIpilarity(文件);
在热图中可视化文档之间的相似性。
图热图(相似性);Xlabel(“文档”)ylabel(“文档”) 标题(“余弦相似之处”的)
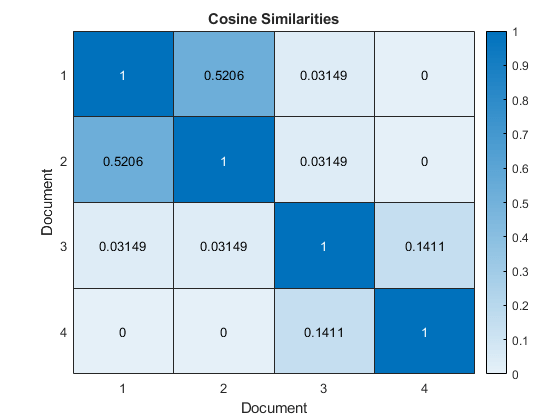
接近一个的分数表示强烈的相似性。接近零的分数表示相似性较弱。
类似于查询的相似之处
创建一个输入文档数组。
str = [“快速的棕色狐狸跳过了懒狗”“快狐狸跳过了懒狗”“狗坐在那里,没什么”“其他动物坐在那里看着”];文档= tokenizedDocument(str)
文档= 4x1令牌Document:9令牌:快速的棕色狐狸跳过懒狗8令牌:快速的狐狸跳过懒狗7令牌:狗坐在那里,没有什么6令牌:其他动物坐在那里
创建一系列查询文档。
str = [“一只棕狐跳过懒狗”“另一只狐狸跳过狗”];查询= tokenizeddocument(str)
查询= 2x1令牌地区:8令牌:棕色狐狸跳过懒狗6令牌:另一只狐狸跳过狗
计算输入和查询文档之间的相似性余弦功能。输出是稀疏矩阵。
相似性= cesineiminity(文档,查询);
在热图中可视化文档的相似之处。
图热图(相似性);Xlabel(“查询文档”)ylabel(“输入文件”) 标题(“余弦相似之处”的)
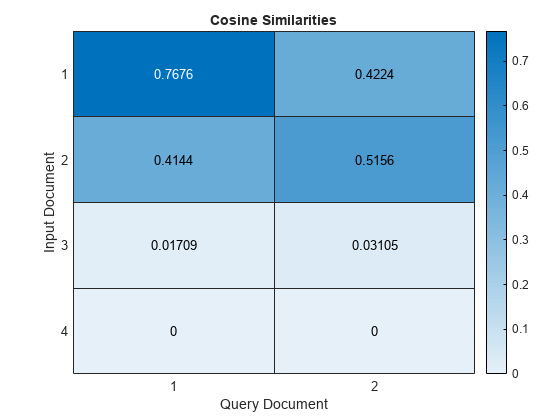
接近一个的分数表示强烈的相似性。接近零的分数表示相似性较弱。
使用词袋模型记录相似之处
从文本数据中创建一个单词袋式模型十四行诗。
filename =“sonnets.csv”;tbl = readtable(文件名,'texttype'那'细绳');textdata = tbl.sonnet;documents = tokenizedDocument(textData);bag = bagofwords(文档)
BAG =具有属性的BAGOFWORDS:COUNTS:[154x3527双]词汇:[“来自”“FIALEST”“生物”“我们”......] NUMWORDS:3527 NUMFOCUMENTS:154
使用余弦功能。输出是稀疏矩阵。
相似性=余弦(袋);
在热图中可视化前五个文档的相似性。
图热图(相似之处(1:5,1:5));Xlabel(“文档”)ylabel(“文档”) 标题(“余弦相似之处”的)
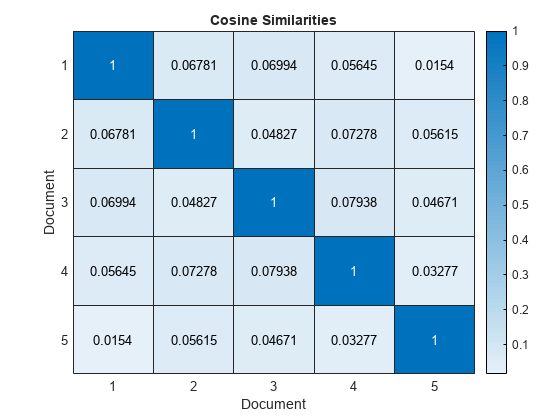
接近一个的分数表示强烈的相似性。接近零的分数表示相似性较弱。
单词数矩阵中的相似之处
对于袋式输入,余弦功能使用从模型中派生的TF-IDF矩阵来计算余弦相似度。要直接计算单词计数向量上的余弦相似之处,请输入单词计数余弦充当矩阵。
从文本数据中创建一个单词袋式模型十四行诗。
filename =“sonnets.csv”;tbl = readtable(文件名,'texttype'那'细绳');textdata = tbl.sonnet;documents = tokenizedDocument(textData);bag = bagofwords(文档)
BAG =具有属性的BAGOFWORDS:COUNTS:[154x3527双]词汇:[“来自”“FIALEST”“生物”“我们”......] NUMWORDS:3527 NUMFOCUMENTS:154
从模型中获取单词计数的矩阵。
m = bag.counts;
计算单词计数矩阵的余弦文档相似性使用余弦功能。输出是稀疏矩阵。
相似之处= CASINESIMILARY(M);
在热图中可视化前五个文档的相似性。
图热图(相似之处(1:5,1:5));Xlabel(“文档”)ylabel(“文档”) 标题(“余弦相似之处”的)
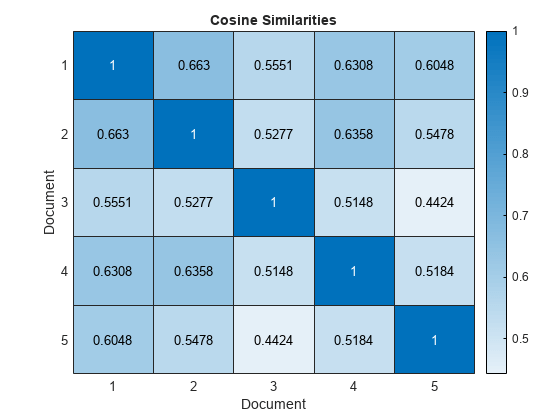
接近一个的分数表示强烈的相似性。接近零的分数表示相似性较弱。
输入参数
输出参数
版本历史记录
您还可以从以下列表中选择一个网站:
美洲
- AméricaLatina(Español)
- 加拿大(英语)
- 美国(英语)