trainWordEmbedding
列车字嵌入
描述
例子
从文件列车Word中嵌入
培养一个字使用示例文本文件尺寸100嵌入exampleSonnetsDocuments.txt。该文件包含预处理莎士比亚十四行诗的版本,每行一个十四行诗和文字分开一个空格。
文件名=“exampleSonnetsDocuments.txt”;EMB = trainWordEmbedding(文件名)
训练:100%损失:2.7062剩余时间:0小时0分钟。
EMB = wordEmbedding与性能:尺寸:100词汇:[1x502字符串]
查看Word中使用文本散点图嵌入tsne。
词语= emb.Vocabulary;V = word2vec(EMB,字);XY = tsne(V);textscatter(XY,字)

从文档列车字嵌入
训练单词使用示例数据嵌入sonnetsPreprocessed.txt。此文件包含莎士比亚十四行诗的预处理版本。该文件包含每行一个十四行诗,文字分离通过的空间。提取文本sonnetsPreprocessed.txt,拆分文本的换行符的文件,然后记号化文档。
文件名=“sonnetsPreprocessed.txt”;STR = extractFileText(文件名);的TextData = SPLIT(STR,换行);文档= tokenizedDocument(的TextData);
培养一个字嵌入使用trainWordEmbedding。
EMB = trainWordEmbedding(文档)
训练:100%损失:3.20363剩余时间:0小时0分钟。
EMB = wordEmbedding与性能:尺寸:100词汇:[1x401字符串]
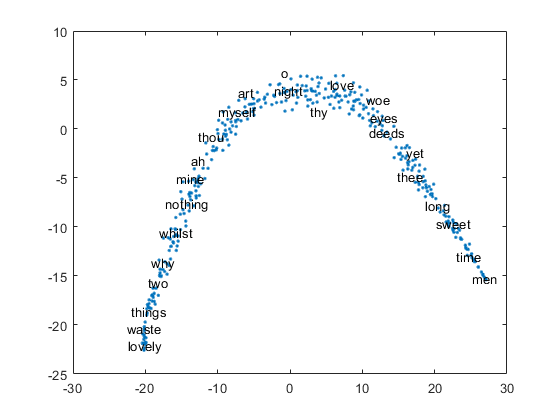
可视化这个词用在文本散点图嵌入tsne。
词语= emb.Vocabulary;V = word2vec(EMB,字);XY = tsne(V);textscatter(XY,字)
指定的Word嵌入选项
加载的示例数据。文件sonnetsPreprocessed.txt包含莎士比亚十四行诗的预处理版本。该文件包含每行一个十四行诗,文字分离通过的空间。提取文本sonnetsPreprocessed.txt,拆分文本的换行符的文件,然后记号化文档。
文件名=“sonnetsPreprocessed.txt”;STR = extractFileText(文件名);的TextData = SPLIT(STR,换行);文档= tokenizedDocument(的TextData);
指定的单词嵌入维为50。为了减少由所述模型废弃的字的数目,集'MinCount'3。为训练的时间更长,设置历元的数目为10。
EMB = trainWordEmbedding(文档,...'尺寸'50,...'MinCount',3,...'NumEpochs',10)
训练:100%损失:2.86391剩余时间:0小时0分钟。
EMB = wordEmbedding与性能:尺寸:50词汇:[1x750字符串]
查看Word中使用文本散点图嵌入tsne。
词语= emb.Vocabulary;V = word2vec(EMB,字);XY = tsne(V);textscatter(XY,字)

输入参数
输出参数
更多关于
提示
训练算法使用由函数给出的线程数maxNumCompThreads。要了解如何改变通过MATLAB使用的线程数®见maxNumCompThreads。
也可以看看
doc2sequence|fastTextWordEmbedding|readWordEmbedding|tokenizedDocument|vec2word|word2vec|wordEmbedding|wordEmbeddingLayer|wordEncoding|writeWordEmbedding
介绍了在R2017b
您还可以选择从下面的列表中的网站:
