定义文本译码器模型的功能
这个例子显示了如何定义一个文本译码器模型函数。
在深度学习的环境中,译码器是深入学习网络的一部分,一个潜在的向量映射到一些样本空间。您可以使用解码各种任务的向量。例如,
初始化一个周期性网络文本生成的编码向量。
Sequence-to-sequence翻译使用编码向量作为上下文向量。
图像字幕通过编码向量作为上下文向量。
加载数据
加载的数据进行编码sonnetsEncoded.mat。这个垫子文件包含这个词编码,mini-batch序列X和相应的编码数据Z编码器的输出中使用的例子定义文本编码器模型函数(深度学习工具箱)。
s =负载(“sonnetsEncoded.mat”);内附= s.enc;X = s.X;Z = s.Z;[latentDimension, miniBatchSize] =大小(Z, 1:2);
初始化模型参数
译码器的目标是生成序列给出一些初始输入数据和网络状态。
初始化参数模型。
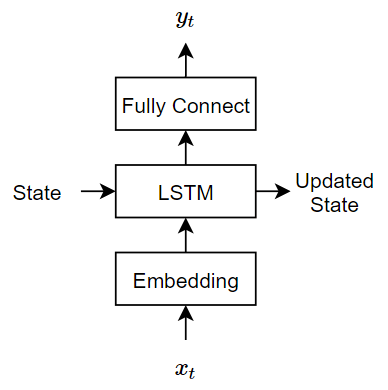
解码器可以使用LSTM初始化输入编码器的输出。对于每一个时间步,译码器预测下一个时间步长,并使用输出为下一个时间步的预测。编码器和解码器使用相同的嵌入。
这个模型使用三个操作:
嵌入地图词指数范围1
vocabularySize向量的维数embeddingDimension,在那里vocabularySize是在编码的词汇和单词的数量embeddingDimension嵌入是组件的数量了。LSTM操作需要一个字作为输入向量和输出1 -
numHiddenUnits向量,numHiddenUnits是隐藏的数量单位LSTM操作。LSTM网络的初始状态(状态在第一个时间步)编码向量,所以隐藏单位的数量必须匹配的潜在维度编码器。完全连接操作增加输入权重矩阵添加偏见和输出向量的大小
vocabularySize。
指定的尺寸参数。嵌入的大小必须与编码器。
embeddingDimension = 100;vocabularySize = enc.NumWords;numHiddenUnits = latentDimension;
创建一个结构参数。
参数=结构;
初始化使用高斯使用嵌入的权重initializeGaussian函数附加到这个例子作为支持文件。金宝app指定一个意味着(0)和标准偏差为0.01。欲了解更多,请看高斯函数初始化(深度学习工具箱)。
深圳= [embeddingDimension vocabularySize];μ= 0;σ= 0.01;parameters.emb。重量= initializeGaussian (sz、μ、σ);
初始化可学的参数解码器LSTM操作:
可学的参数的大小取决于输入的大小。因为输入LSTM操作词向量序列的嵌入操作,输入通道的数量embeddingDimension。
输入权重矩阵的大小
4 * numHiddenUnits——- - - - - -inputSize,在那里inputSize输入数据的维数。复发性权重矩阵的大小
4 * numHiddenUnits——- - - - - -numHiddenUnits。偏差矢量的大小
4 * numHiddenUnits1。
深圳= [4 * numHiddenUnits embeddingDimension];numOut = 4 * numHiddenUnits;numIn = embeddingDimension;parameters.lstmDecoder。InputWeights = initializeGlorot(深圳、numOut numIn);parameters.lstmDecoder。RecurrentWeights = initializeOrthogonal ([4 * numHiddenUnits numHiddenUnits]);parameters.lstmDecoder。偏见= initializeUnitForgetGate (numHiddenUnits);
初始化可学的参数编码器完全连接操作:
初始化权重Glorot初始值设定项。
使用零使用初始化偏差
initializeZeros函数附加到这个例子作为支持文件。金宝app欲了解更多,请看零初始化(深度学习工具箱)。
可学的参数的大小取决于输入的大小。因为输入的输出是完全连接操作LSTM操作,输入通道的数量numHiddenUnits。使完全连接操作的输出向量和大小latentDimension,指定输出的大小latentDimension。
权重矩阵的大小
outputSize——- - - - - -inputSize,在那里outputSize和inputSize分别对应的输出和输入维度。偏差矢量的大小
outputSize1。
使完全连接操作的输出向量和大小vocabularySize,指定输出的大小vocabularySize。
深圳= [vocabularySize numHiddenUnits];μ= 0;σ= 1;parameters.fcDecoder。重量= initializeGaussian (sz、μ、σ);parameters.fcDecoder。偏见= initializeZeros ([vocabularySize 1]);
定义模型译码器函数
创建函数modelDecoder中列出,译码器模型函数部分的示例中,计算译码器的输出模型。的modelDecoder函数,取词序列作为输入指标,模型参数和序列长度,并返回相应的潜在特征向量。
使用模型函数模型损失函数
当培训深度学习模型与一个定制的循环,你必须计算损失的损失和梯度对可学的参数。这个计算取决于正向模型的传递函数的输出。
通常有两种方法来生成文本数据的译码器:
闭环——对于每一个时间步,使用先前的预测作为输入进行预测。
开环——对于每一个时间步,作出预测使用输入从外部源(例如,培训目标)。
闭环的一代
闭环生成模型生成数据时一次一个时间步,使用前面的预测未来预测作为输入。与开环,这个过程不需要任何输入之间的预测和最适合场景没有监督。例如,语言翻译模型,生成输出文本。
初始化隐藏状态的LSTM网络编码器的输出Z。
状态=结构;状态。HiddenState = Z;状态。CellState = 0(大小(Z),“喜欢”,Z);
一步,首次使用数组的开始标记作为译码器的输入。为简单起见,从第一个时间步提取数组开始标记的训练数据。
decoderInput = X (:: 1);
Preallocate译码器的输出大小numClasses——- - - - - -miniBatchSize——- - - - - -sequenceLength相同的数据类型dlX,在那里sequenceLength所需的长度的一代,例如,培训目标的长度。对于这个示例,指定一个序列的长度16。
sequenceLength = 16;Y = 0 (vocabularySize miniBatchSize sequenceLength,“喜欢”,X);Y = dlarray (Y,“认知行为治疗”);
对于每一个时间步,预测下一个时间步的顺序使用modelDecoder函数。每次预测后,找到相对应的指标的最大值解码器输出和使用这些指数作为下一个时间步的译码器的输入。
为t = 1: sequenceLength [Y (:,:, t)、州)= modelDecoder(参数、decoderInput状态);[~,idx] = max (Y (:,:, t));decoderInput = idx;结束
输出是一个vocabularySize——- - - - - -miniBatchSize——- - - - - -sequenceLength数组中。
大小(Y)
ans =1×33595 32 16
这个代码片段显示了一个示例执行闭环生成模型梯度函数。
函数(损失,梯度)= modelLoss(参数X, sequenceLengths)%编码输入。Z = modelEncoder(参数X, sequenceLengths);%初始化LSTM状态。状态=结构;状态。HiddenState = Z;状态。CellState = 0(大小(Z),“喜欢”,Z);%初始化译码器的输入。decoderInput = X (:: 1);%闭环预测。sequenceLength =大小(X, 3);Y = 0 (numClasses miniBatchSize sequenceLength,“喜欢”,X);为t = 1: sequenceLength [Y (:,:, t)、州)= modelDecoder(参数、decoderInput状态);[~,idx] = max (Y (:,:, t));decoderInput = idx;结束%计算损失。%……%计算梯度。%……结束
开环代:老师强迫
训练时闭环生成预测最可能的词序列中的每个步骤可能导致次优的结果。例如,在一个图像字幕工作流,如果解码器预测一个标题的第一个词是“a”,当给定一个大象的形象,然后的概率预测下一个单词“大象”变得更加不可能,因为极低概率的“大象”这个词出现在英语文本。
帮助网络收敛速度,您可以使用老师要求:使用目标值作为译码器的输入,而不是先前的预测。使用老师迫使有助于学习的网络特征的以后的步骤序列,而无需等待网络正确生成的更早的时间步骤序列。
执行老师强迫,使用modelEncoder函数直接与目标序列作为输入。
初始化隐藏状态的LSTM网络编码器的输出Z。
状态=结构;状态。HiddenState = Z;状态。CellState = 0(大小(Z),“喜欢”,Z);
使用目标序列作为输入进行预测。
Y = modelDecoder(参数X,状态);
输出是一个vocabularySize——- - - - - -miniBatchSize——- - - - - -sequenceLength数组,sequenceLength输入序列的长度。
大小(Y)
ans =1×33595 32 14
这个代码片段显示了一个示例执行老师迫使一个梯度函数模型。
函数(损失,梯度)= modelLoss(参数X, sequenceLengths)%编码输入。Z = modelEncoder(参数X);%初始化LSTM状态。状态=结构;状态。HiddenState = Z;状态。CellState = 0(大小(Z),“喜欢”,Z);%老师强迫。Y = modelDecoder(参数X,状态);%计算损失。%……%计算梯度。%……结束
译码器模型函数
的modelDecoder函数,使用模型作为输入参数,序列的指数,和网络状态,并返回解码序列。
因为lstm函数是有状态(当给定一个时间序列作为输入,该函数在每个时间步)之间传播并更新状态,嵌入和fullyconnect功能是当分布式默认情况下(当给定一个时间序列作为输入,功能独立操作每个时间步),modelDecoder功能支持序列和单一金宝app时间步输入。
函数[Y,状态]= modelDecoder(参数X,状态)%嵌入。重量= parameters.emb.Weights;X =嵌入(X,重量);% LSTM。inputWeights = parameters.lstmDecoder.InputWeights;recurrentWeights = parameters.lstmDecoder.RecurrentWeights;偏见= parameters.lstmDecoder.Bias;hiddenState = state.HiddenState;cellState = state.CellState;[Y, hiddenState, cellState] = lstm (X, hiddenState cellState,…inputWeights recurrentWeights,偏差);状态。HiddenState = HiddenState;状态。CellState = CellState;%完全连接。重量= parameters.fcDecoder.Weights;偏见= parameters.fcDecoder.Bias;Y = fullyconnect (Y,重量,偏差);结束
另请参阅
wordEncoding|word2ind|doc2sequence|tokenizedDocument