视觉词袋图像分类
使用计算机视觉工具箱™ 通过创建视觉单词包来进行图像类别分类的功能。该过程生成表示图像的可视单词出现的直方图。这些直方图用于训练图像类别分类器。下面的步骤描述了如何设置图像,创建视觉词汇包,然后训练和应用图像类别分类器。
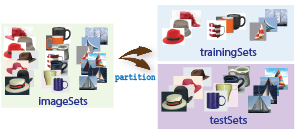
步骤1:设置图像类别集
将图像组织并划分为训练和测试子集。使用图像数据存储函数存储用于训练图像分类器的图像。将图像组织到类别中使处理大型图像集更加容易。你可以使用splitEachLabel函数将图像分割为训练和测试数据。
阅读类别的图像和创建图像集。
setDir =完整文件(toolboxdir( '视力'), 'visiondata', 'imageSets');IMDS = imageDatastore(setDir, 'IncludeSubfolders',真, 'LABELSOURCE',... 'foldernames');
将集合分为训练和测试图像子集。在这个例子中,30%的图像被分割用于训练,其余的用于测试。
[trainingSet,testSet]=splitEachLabel(imds,0.3,“随机化”);
步骤2:创建功能包
创建视觉词汇,或特征的袋,通过从每个类别的代表性图像中提取特征描述符。
这个面包对象通过使用k-均值聚类基于统计与机器学习工具箱的特征描述子提取算法训练集. 算法迭代地将描述符分组为千互斥集群。将得到的簇紧凑,并通过类似的特征分隔开。每个群集中心表示的特征,或视觉词。
可以基于特征检测器提取特征,也可以定义网格以提取特征描述符。网格方法可能会丢失细粒度的尺度信息。因此,对于不包含明显特征的图像(如包含风景的图像,如海滩),请使用网格。使用加速鲁棒特征(或SURF)检测器提供更大的尺度不变性。默认情况下,算法运行'网格'方法。

该算法工作流程对图像进行整体分析。图像必须有适当的标签来描述它们所表示的类。例如,一组汽车图像可以标记为汽车。工作流不依赖于空间信息,也不依赖于标记图像中的特定对象。视觉文字袋技术依赖于无定位的检测。
步骤3:培养的图像分类随着袋的视觉词的
这个trainImageCategoryClassifier函数返回图像分类器。该函数使用纠错输出码(ECOC)框架和二进制支持向量机(SVM)分类器训练多类分类器。这个金宝appTrainImageCategoryAssifier系列功能使用的由返回的视觉词袋面包目的是在图像组成的视觉词直方图编码图像。的视觉词直方图然后被用作阳性和阴性样品来训练分类器。


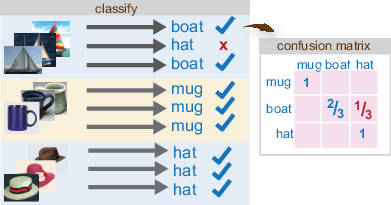
步骤4:分类的图像或图像集
使用图像分类助手预测方法确定新图像的类别。
参考
[1] C.R.Dance、L.Fan、J.Willamowski和C.Bray。带关键点袋的视觉分类. 计算机视觉统计学习研讨会。ECCV1(1-22),1-2。
相关话题
也可以从以下列表中选择网站:
