小波时散射心电信号分类
这个例子展示了如何使用小波时散射和支持向量机(SVM)分类器人类心电图(ECG)信号分类。金宝app在小波散射,数据通过一系列小波变换,非线性,和平均化的时间系列生产低方差表示传播。小波时散射产量信号表示不敏感的输入信号的变化,而不会牺牲类辨性。你必须有小波工具箱™和统计和机器学习工具箱™来运行这个例子。在这个例子中使用的数据是公开的,从PhysioNet。你可以找到在这个例子中深度学习的办法处理这一分类问题分类时间序列的小波分析和深入学习和机器学习在这个例子中的方法信号分类使用基于小波特征和支持向量机金宝app。
数据说明
本例中使用三组或班级获得的心电图数据,人们:有心律失常者,充血性心脏衰竭的人,并与人正常窦性节律。该示例使用从三个PhysioNet数据库162个心电图记录:MIT-BIH心律失常数据库[3] [5],MIT-BIH正常窦性心律数据库[3],和该BIDMC充血性心力衰竭数据库[2] [3]。在总共有从人96级的录音与心律失常,从与充血性心脏衰竭的人30个录音,并从与正常窦性节律的人36分的录音。我们的目标是训练分类心律失常(ARR),充血性心脏衰竭(CHF),和正常窦性心律(NSR)区别开来。
下载数据
第一步是下载从数据GitHub的库。要下载数据,请点击克隆或下载并选择下载ZIP。保存文件physionet_ECG_data-master.zip一个文件夹中,你有写权限。在这个例子中的说明假设您已经下载的文件到临时目录,(TEMPDIR在MATLAB)。修改解压和加载数据的后续指令,如果你选择从下载文件夹中的不同数据TEMPDIR。如果您熟悉使用Git,你可以下载最新版本的工具(混帐),并使用从提示系统命令获得数据混帐克隆https://github.com/mathworks/physionet_ECG_data/。
文件physionet_ECG_data-master.zip包含
ECGData.zip
README.md
和ECGData.zip包含
ECGData.mat
Modified_physionet_data.txt
LICENSE.TXT。
ECGData.mat保持在这个例子中使用的数据。.txt文件,Modified_physionet_data.txt,由PhysioNet的复制策略所需,并提供了源归因用于数据以及的预处理步骤的说明适用于每个ECG记录。
加载文件
如果按照上一节中的下载说明,输入以下命令来解压缩两个存档文件。
解压(完整文件(TEMPDIR,'physionet_ECG_data-master.zip'),TEMPDIR)解压缩(完整文件(TEMPDIR,“physionet_ECG_data主”,'ECGData.zip')...完整文件(TEMPDIR,'ECGData'))
之后您解压缩文件ECGData.zip,将数据加载到MATLAB。
负载(完整文件(TEMPDIR,'ECGData','ECGData.mat'))
ECGData是具有两个字段的结构数组:数据和标签。数据是162逐65536矩阵,其中每一行是在128赫兹采样的ECG记录。每个ECG时间序列具有512秒的总的持续时间。标签是诊断标签的162×1单元阵列,一个用于每行数据。三种诊断类别是:“ARR”(心律失常),“CHF”(充血性心脏衰竭),和“NSR”(正常窦性心律)。
创建训练和测试数据
随机的数据分成两组 - 训练和测试数据集。助手功能helperRandomSplit执行随机分裂。helperRandomSplit接受所需的分割百分比为训练数据和ECGData。该helperRandomSplit函数输出两个数据集与一组标签的每一个沿。每行trainData和测试数据是ECG信号。中的每个元素trainLabels和testLabels包含数据矩阵的相应行中的类别标签。在这个例子中,我们随机在每类训练集分配的数据的70%百分比。剩余的30%被保持为不用于测试(预测)和被分配到测试组。
percent_train = 70;[trainData,TESTDATA,trainLabels,testLabels] =...helperRandomSplit(percent_train,ECGData);
有113条记录中trainData集和49个记录测试数据。按照设计,训练数据包含69.75%(113/162)的数据。回想一下,ARR类占数据的59.26% (96/162),CHF类占18.52% (30/162),NSR类占22.22%(36/162)。检查每个班在训练和测试集中所占的百分比。每个类中的百分比与数据集中的总体类百分比一致。
卡加利轻铁= countcats(分类(trainLabels))./ numel(trainLabels)* 100 = CTEST countcats(分类(testLabels))./ numel(testLabels)。* 100
卡加利轻铁= 59.2920 18.5841 22.1239 CTEST = 59.1837 18.3673 22.4490
情节样品
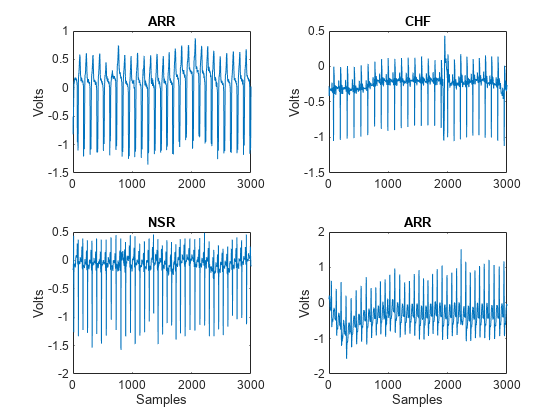
绘制四个随机选择记录的第一个几千个样本来自ECGData。助手功能helperPlotRandomRecords做这个。helperPlotRandomRecords接受ECGData和一个随机种子作为输入。使得来自每个类中至少有一个记录绘制初始种子被设定为14。您可以执行helperPlotRandomRecords同ECGData作为唯一的输入参数多次,你希望得到的各种每一类相关的心电图波形的感觉。您可以在这个例子中的最后发现在配套功能部分这种源代码和所有辅助功能。金宝app
helperPlotRandomRecords(ECGData,14)
小波时散射
关键参数来指定一个小波时散射分解是不随时间变化的比例,小波变换的次数,和每倍频程的子波在每个小波滤波器组的数量。在许多应用中,两个过滤银行的级联足以取得良好的业绩。在这个例子中,我们构建使用默认的滤波器组小波时间散射分解:每倍频程8个小波在第一滤波器组和第二滤波器组每倍频程1个小波。不变性规模被设置为150秒。
N =尺寸(ECGData.Data,2);SF = waveletScattering('SignalLength',N,'InvarianceScale',150,'采样频率',128);
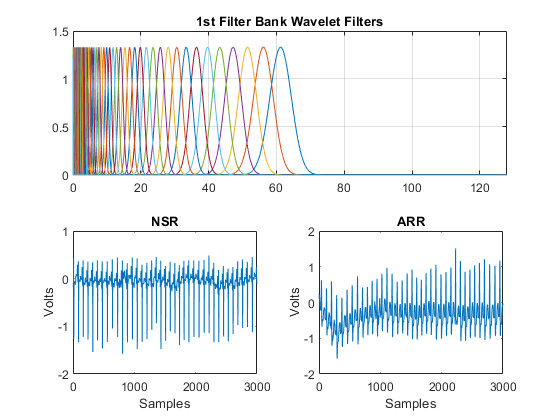
你可以用下面的可视化两个滤波器组的小波滤波器。
[FB,F,filterparams] =滤波器(SF);副区(211)情节(F,FB {2} .psift)XLIM([0 128])格上标题(“第1滤波器组小波过滤器”);副区(212)情节(F,FB {3} .psift)XLIM([0 128])格上标题(“第二滤波器组小波过滤器”);xlabel('赫兹');
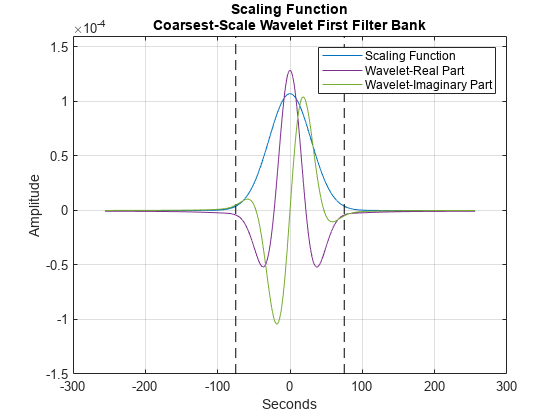
为了证明不变性规模,获得逆傅立叶在时间0秒变换缩放函数和中心它的。两个垂直的黑线标记-75和75秒边界。此外,绘制最粗尺度(最低频率)的实部和虚部从第一滤波器组的小波。需要注意的是最粗尺度小波不超过规模不变的决定的时候支持缩放功能。金宝app这是小波时散射的一个重要特性。
数字;披= ifftshift(IFFT(FB {1} .phift));psiL1 = ifftshift(IFFT(FB {2} .psift(:,端)));T =(-2 ^ 15:2 ^ 15-1)。* 1/128;scalplt =情节(T,PHI);保持上格上ylim([ - 1.5E-4 1.6E-4]);情节([ - 75 -75],[ - 1.5E-4 1.6E-4],'K--');情节([75 75],[ - 1.5E-4 1.6E-4],'K--');xlabel(“秒”);ylabel('振幅');wavplt =情节(T,[真实(psiL1)IMAG(psiL1)]);图例([scalplt wavplt(1)wavplt(2)],{“缩放功能”,“小波的实部”,“小波的虚部”});标题({“缩放功能”;“粗尺度小波第一滤波器组”})
构建散射分解框架后,获得训练数据作为基质的散射系数。当您运行featureMatrix具有多个信号,每个列被处理的单个信号。
scat_features_train = featureMatrix(SF,trainData');
输出featureMatrix在这种情况下是416×16逐113。张量的每一页,scat_features_train,是一个信号的散射变换。小波变换散射在时间临界下采样基于所述缩放函数的带宽。在这种情况下,这导致了对每个416条散射路径16个的时间窗。
为了获得与SVM分类器兼容的矩阵,重塑多信号散射转变成一个矩阵,其中每一列对应于一个散射路径和每行是一个散射时间窗口。在这种情况下,你获得1808行,因为有每个训练数据的113个信号的16个时间窗。
Nwin =尺寸(scat_features_train,2);scat_features_train =置换(scat_features_train,[2 3 1]);scat_features_train =重塑(scat_features_train,...大小(scat_features_train,1)*大小(scat_features_train,2),[]);
重复此过程,测试数据。原来,scat_features_test是416×16逐49,因为在训练集合49个的ECG波形。重塑的SVM分类器之后,将特征矩阵784是按416。
scat_features_test = featureMatrix(SF,TESTDATA');scat_features_test =置换(scat_features_test,[2 3 1]);scat_features_test =重塑(scat_features_test,...大小(scat_features_test,1)*大小(scat_features_test,2),[]);
由于每个信号我们获得了16楼散射的窗口,我们需要创建标签相匹配窗口的数量。助手功能createSequenceLabels做此基础上的窗口数量。
[sequence_labels_train,sequence_labels_test] = createSequenceLabels(Nwin,trainLabels,testLabels);
交叉验证
对于分类,两个分析进行。第一次使用所有散射数据和适合多类SVM与二次内核。总共有在整个数据集2592组散射的序列,16为每个162个信号。错误率,或损失,估计是使用5倍交叉验证。
scat_features = [scat_features_train;scat_features_test];allLabels_scat = [sequence_labels_train;sequence_labels_test];RNG(1);模板= templateSVM(...'KernelFunction',“多项式”,...'PolynomialOrder',2,...'KernelScale','汽车',...'BoxConstraint'1,...“标准化”,真正的);classificationSVM = fitcecoc(...scat_features,...allLabels_scat,...“学习者”,模板,...'编码','onevsone',...“类名”{'ARR';'CHF';'NSR'});kfoldmodel = crossval(classificationSVM,'KFold',5);
计算损耗和混淆矩阵。显示精度。
predLabels = kfoldPredict(kfoldmodel);损耗= kfoldLoss(kfoldmodel)* 100;confmatCV = confusionmat(allLabels_scat,predLabels)fprintf中('精度为2.2F%百分之。\ N',100-损失);
confmatCV = 1535 0 1 1 479 0 0 0 576精度为百分之99.92。
精确度为99.92%,这是相当不错的,但实际的结果是更好的考虑,这里每个时间窗口被单独分类。有用于每个信号16个单独的分类。使用简单多数票获得每个散射表示一个类预测。
类分类=({'ARR','CHF','NSR'});[ClassVotes,ClassCounts] = helperMajorityVote(predLabels,[trainLabels; testLabels],类);
确定基于类的预测对于每组散射时间窗的模式下的实际交叉验证精度。如果模式不是给定一组独特的,helperMajorityVote返回所指示的分类误差'NoUniqueMode'。这导致在混淆矩阵一个额外的列,在这种情况下是全零,因为唯一的模式存在于每个组散射的预测。
CVaccuracy =总和(当量(ClassVotes,分类([trainLabels; testLabels])))/ 162 * 100;fprintf中(“真正的交叉验证精度%2.2F百分比。\ N”,CVaccuracy);MVconfmatCV = confusionmat(ClassVotes,分类([trainLabels; testLabels]));MVconfmatCV
真正的交叉验证准确度是百分之100.00。MVconfmatCV = 96 0 0 0 0 30 0 0 0 0 36 0 0 0 0 0
散射已正确分类的交叉验证模型中的所有信号。如果您检查ClassCounts,你看到2个分类错误的时间窗confmatCV归因于其中16个散射的窗口15被正确分类2点的信号。
SVM分类
在接下来的分析中,我们适应多类二次SVM训练数据只(70%),然后使用该模型进行的测试坚守了数据的30%的预测。有测试集49个的数据记录。对个人散射Windows中使用的多数票。
模型= fitcecoc(...scat_features_train,...sequence_labels_train,...“学习者”,模板,...'编码','onevsone',...“类名”{'ARR','CHF','NSR'});predLabels =预测(模式,scat_features_test);[TestVotes,TestCounts] = helperMajorityVote(predLabels,testLabels,类);testaccuracy =总和(当量(TestVotes,分类(testLabels)))/ numel(testLabels)* 100;fprintf中(“测试精度%2.2F百分比。\ n”,testaccuracy);testconfmat = confusionmat(TestVotes,分类(testLabels));testconfmat
测试精度为97.96个百分点。testconfmat = 29 1 0 0 0 8 0 0 0 0 11 0 0 0 0 0
对测试数据集的分类精确度约为98%。混淆矩阵显示,一个CHF记录被误判为ARR。所有48个其它信号的正确分类。
摘要
该实施例使用小波时散射和SVM分类器进行分类ECG波形分成三个诊断类之一。小波散射被证明是一个强大的特征提取器,其仅需要最小的一组的用户指定的参数,以产生一组用于分类强大的功能。与例子比较一下信号分类使用基于小波特征和支持向量机金宝app,这需要专业知识的显著量手工艺特色的分类使用。随着小波时散射,你只需要指定时间不变性的规模,滤波器组(或小波变换)的数量,并且每倍频程的小波数量。小波散射的组合变换和SVM分类器施加SVM到保持输出测试组的散射变换时在交叉验证模型和98%正确分类,得到100%的分类。
参考
Anden,J.,的Mallat,S. 2014深散射光谱,在信号处理中,62,16,第4114-4128 IEEE交易。
Baim DS,Colucci的WS,蒙拉德ES,史密斯HS,赖特RF,Lanoue A,高塞尔DF,Ransil BJ,格罗斯曼W,患者口服米力农治疗严重充血性心脏衰竭Braunwald的E.生存。1986年心脏病三月j的美国大学;图7(3):661-670。
戈德伯格AL,阿马拉尔LAN,玻璃L,豪斯多夫JM,Ivanov的PCH,马克RG,Mietus JE,穆迪GB,彭C-K,斯坦利HE。PhysioBank,PhysioToolkit和PhysioNet:一个新的研究资源的组件的复杂生理信号。循环。卷。101,第23号,2000 6月13日,第E215-E220。
http://circ.ahajournals.org/content/101/23/e215.full的Mallat,S.,2012年集团不变的散射。通信在纯粹与应用数学,65%,10,第1331至1398年。
穆迪GB,马克RG。在MIT-BIH心律失常数据库的影响。IEEE主机在医学和生物学20(3):45-50(2001年5月 - 6月)。(PMID:11446209)
金宝app支持功能
helperPlotRandomRecords曲线4个的ECG信号中随机选自ECGData。
功能helperPlotRandomRecords(ECGData,randomSeed)%该功能仅用于支持XpwWaveletMLExample。金宝app它可能%的变化或在将来的版本中删除。如果nargin == 2 RNG(randomSeed)结束M =尺寸(ECGData.Data,1);idxsel = randperm(M,4);对于numplot = 1:4副区(2,2,numplot)情节(ECGData.Data(idxsel(numplot),1:3000))ylabel(“伏”)如果numplot> 2 xlabel(“样品”)结束标题(ECGData.Labels {idxsel(numplot)})结束结束
helperMajorityVote发现在预测类别标签对于每组散射时间窗口的模式。该函数返回两个类别标签模式和分级预测为每组散射时间窗的数量。如果没有独特的模式,helperMajorityVote返回“错误”的一类标签,以表明集合散射窗户的是分类错误。
功能[ClassVotes,ClassCounts] = helperMajorityVote(predLabels,origLabels,班)%该功能是支持ECGWaveletTimeS金宝appcatteringExample的。它可能%的变化或在将来的版本中删除。%制作绝对阵列如果标签尚未分类predLabels =分类(predLabels);origLabels =分类(origLabels);%来料既predLabels和origLabels是分类矢量Npred = numel(predLabels);Norig = numel(origLabels);Nwin = Npred / Norig;predLabels =重塑(predLabels,Nwin,Norig);ClassCounts = countcats(predLabels);[mxcount,IDX] = MAX(ClassCounts);ClassVotes =类(IDX);%检查的最大值任何关系,并确保它们被标记为如果模式发生%的误差超过一次modecnt = modecount(ClassCounts,mxcount);ClassVotes(modecnt> 1)=分类({'错误'});ClassVotes = ClassVotes(:);%-------------------------------------------------------------------------功能modecnt = modecount(ClassCounts,mxcount)modecnt = Inf文件(大小(ClassCounts,2),1);对于NC = 1:尺寸(ClassCounts,2)modecnt(NC)= histc(ClassCounts(:,NC),mxcount(NC));结束结束%EOF结束
也可以看看
相关话题
您还可以选择从下面的列表中的网站: