深度学习标度图的GPU加速
这个例子展示了如何使用gpu加速标量图计算。将计算得到的尺度图作为深度卷积神经网络(CNN)的输入特征,用于心电和语音分类。
使用GPU需要并行计算工具箱™。要查看支持的图形处理器,请参见金宝appGPU通金宝app过发布支持(并行计算工具箱).本例的音频部分需要使用audio Toolbox™来使用音频数据存储和转换后的数据存储。
基于GPU的标量图计算
在GPU上计算标量图最有效的方法是使用cwtfilterbank..在GPU上计算标量图的步骤如下:
构造
cwtfilterbank.使用所需的属性设置。将信号移动到GPU使用
gpuArray.使用滤波器组
WT计算连续小波变换(CWT)的方法。
第一次使用WT方法,cwtfilterbank.缓存GPU上的小波滤波器。结果,当使用相同的滤波器组和相同的数据类型获得多个信号的缩放标准时,实现计算中的大量时间。以下演示了推荐的工作流程。例如,使用包含661,500个样本的吉他音乐样本。
(y, fs) = audioread ('guitartune.wav');情节(y)网格在
因为大多数NVIDIA gpu使用单精度数据比双精度数据效率更高,所以将信号转换为单精度。
y =单(y);
构造匹配信号长度和采样频率的滤波器组。对于深度学习,采样频率通常是不需要的,因此可以排除。
fb = cwtfilterbank (“SignalLength”,冗长),“SamplingFrequency”fs);
最后将信号移动到GPU使用gpuArray并计算数据的CWT。绘制所产生的标量程表。
(慢性疲劳综合症,f) = fb.wt (gpuArray (y));t = 0:1 / fs:(长度(y) * 1 / fs) 1 / f;显示亮度图像(t、f、abs (cfs))轴xyylabel('赫兹')包含(“秒”)
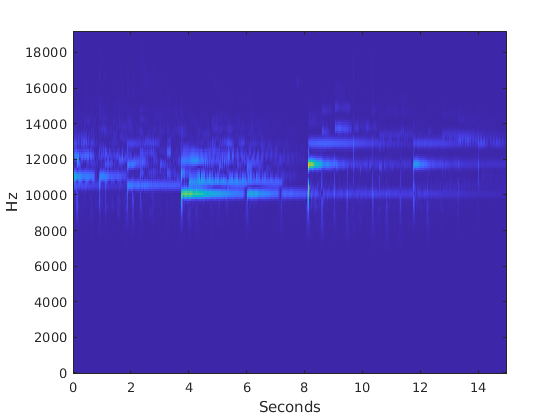
使用收集将CWT系数和任何其他输出带回CPU。
CFS =聚集(CFS);f =聚集(f);
为了证明使用GPU所获得的效率,对相同的信号在GPU和CPU上进行CWT计算的时间。这里报告的GPU计算时间是使用NVIDIA Titan V的7.0计算能力获得的。
YGPU = GPUARRAY(Y);fgpu = @()fb.wt(ygpu);tgpu = gputimeit(fgpu)
Tgpu = 0.2658
在CPU上重复相同的测量,并检查GPU与CPU时间的比率,以查看计算时间的减少。
fcpu = @ () fb.wt (y);Tcpu时间= (fcpu)
Tcpu = 3.7088
Tcpu / Tgpu
ans = 13.9533
深度学习中的标量图
CWT在深度学习中的一个常见应用是使用信号的标度图作为深度CNN的输入“图像”。这就要求对训练、验证和测试集中的每个信号计算多个尺度图。gpu通常用于加速深度网络中的训练和推理,使用gpu加速任何特征提取或数据预处理也有利于使深度网络更健壮。
为了说明这一点,下面一节将小波尺度图应用于人体心电图(ECG)分类。使用标度图处理相同的数据利用小波分析和深度学习对时间序列进行分类.在该示例中,使用Googlenet和Screezenet的传输学习将ECG波形分类为三类中的一个。为了方便起见,数据的描述以及如何获得它的方法。
ECG数据描述和下载
心电图数据来自三组人:心律失常(ARR)、充血性心力衰竭(CHF)和窦性节律正常(NSR)。总共有162个心电记录,来自三个PhysioNet数据库:MIT-BIH心律失常数据库[2] [3],MIT-BIH正常窦性节律数据库[3]BIDMC充血性心力衰竭数据库[1][3]。更具体地说,心律失常者96份,充血性心力衰竭者30份,窦性节律正常者36份。目标是训练一个模型来区分ARR、CHF和NSR。
您可以从MathWorks获得这些数据GitHub库.要从网站下载数据,请单击代码并选择下载ZIP.保存文件physionet_ECG_data-main.zip在您具有写入权限的文件夹中。此示例的说明假定您已将文件下载到临时目录,tempdir,在matlab。修改后续说明解压缩并加载数据如果您选择在不同的文件夹中下载数据tempdir.
从GitHub下载数据后,将文件解压到临时目录中。
解压缩(FullFile(Tempdir,“physionet_ECG_data-main.zip”), tempdir)
解压缩将创建文件夹physionet-ECG_data-main在临时目录中。此文件夹包含文本文件README.md和EcgData.zip..这EcgData.zip.文件包含
ECGData.matModified_physionet_data.txtLicense.txt
ECGData.mat保持此示例中使用的数据。文本文件,Modified_physionet_data.txt,是PhysioNet复制策略所需要的,并提供数据的源属性,以及对每个ECG记录应用的预处理步骤的描述。
解压缩EcgData.zip.在physionet-ECG_data-main.将数据文件加载到MATLAB工作区中。
解压缩(FullFile(Tempdir,'physionet_ecg_data-main',“ECGData.zip”),...fullfile (tempdir'physionet_ecg_data-main'))加载(FullFile(Tempdir,'physionet_ecg_data-main',“ECGData.mat”))
ECGData是一个有两个字段的结构数组:数据和标签.这数据字段是一个162乘65536的矩阵,其中每一行是以128赫兹采样的心电记录。标签是一个162 × 1的细胞阵列诊断标签,每一行一个数据.这三种诊断类型是:“加勒比海盗”,瑞士法郎的,“签约”.使用辅助函数,helperRandomSplit,将数据分成训练集和验证集,其中80%的数据用于训练,20%用于验证。将心电图诊断标签转换为分类。
[trainData, validationData, trainLabels, validationLabels] = helperRandomSplit(80,ECGData);trainLabels =分类(trainLabels);validationLabels =分类(validationLabels);
有130条记录trainData设置和32条验证记录数据.经过设计,训练数据包含了数据的80.25%(130/162)。回想一下,ARR类代表59.26%的数据(96/162),CHF类代表18.52% (30/162),NSR类代表22.22%(36/162)。检查每个类在训练和测试集中的百分比。每个班级的百分比与数据集中的整体班级百分比一致。
Ctrain = countcats (trainLabels)。/元素个数(trainLabels)。* 100
Ctrain =3×159.2308 18.4615 22.3077
Cvalid = countcats (validationLabels)。/元素个数(validationLabels)。* 100
Cvalid =3×159.3750 18.7500 21.8750
具有深层CNN - ECG数据的缩放图
GPU上的缩放计算
计算训练集和验证集的标量图。集使用gpu.来真正的使用图形处理器和假在CPU上计算标量图。为了减轻大输入矩阵对CNN的影响,并创建更多的训练和验证示例,helperECGScalograms将每个ECG波形分为四个非向量段为16384个样本,并计算所有四个段的缩放线。复制标签以匹配扩展的数据集。在这种情况下,获得消耗计算时间的估计。
frameLength = 16384;useGPU = true;抽搐;Xtrain = helperECGScalograms (trainData frameLength useGPU);
计算缩放图......从130个处理后的50个文件中处理了50个文件,其中130个文件...完成
T = toc;sprintf ('经过时间是%1.2f秒',t)
ans = '运行时间为4.22秒'
trainLabels = repelem (trainLabels 4);
使用Titan V GPU,502种Scalographer在大约4.2秒内计算。环境使用gpu.来假重复以上计算说明了使用GPU所获得的速度提升。在本例中,使用CPU需要33.3秒来计算标量图。GPU计算速度快了7倍以上。
对验证数据重复相同的过程。
useGPU = true;xvalid = HelperecgScographs(验证数据,FrameLength,UseGGPU);
计算缩放图......完成
validationLabels = repelem (validationLabels 4);
接下来设置深度CNN以处理培训和验证集。这里使用的简单网络未得到优化。该CNN仅用于说明尺度图适合存储器的情况的端到端工作流程。
深圳=大小(Xtrain);specSize =深圳(1:2);imageSize = [specSize 1];dropoutProb = 0.3;[imageInputLayer(imageSize)] = [imageInputLayer(imageSize)]'填充',“相同”maxPooling2dLayer(2,“步”20岁的,2)convolution2dLayer (3'填充',“相同”maxPooling2dLayer(2,“步”32岁的,2)convolution2dLayer (3'填充',“相同”) batchNormalizationLayer relullayer dropoutLayer(dropoutProb) fulllyconnectedlayer (3) softmaxLayer classificationLayer];
使用以下培训选项。
选择= trainingOptions ('sgdm',...“InitialLearnRate”1的军医,...“LearnRateDropPeriod”,18,...“MiniBatchSize”, 20岁,...“MaxEpochs”25岁的...“L2Regularization”1 e 1,...“阴谋”,“训练进步”,...'verbose'假的,...“洗牌”,“every-epoch”,...“ExecutionEnvironment”,“汽车”,...“ValidationData”, {Xvalid, validationLabels});
训练网络并测量验证误差。
trainNetwork (Xtrain、trainLabels层,选择);

即使这里使用的简单CNN未得到优化,验证精度也一致在高80到低90%范围内。这与通过更强大且优化的挤压罩所实现的验证精度相当利用小波分析和深度学习对时间序列进行分类的例子。此外,这是一个更有效的使用尺度图,因为在那个例子中,尺度图必须被缩放为兼容于SqueezeNet的RGB图像,以适当的图像格式保存到磁盘,然后馈送到深度网络使用imageageAtastore..
语音数字识别-使用转换数据存储的GPU计算
本节介绍如何在转换的数据存储工作流程中使用GPU加速缩放计算。
数据
克隆或下载免费口语数字数据集(FSDD),可在https://github.com/jakobovski/free-spoken-digit-dataset中获得。FSDD是一个打开的数据集,这意味着它可以随着时间的推移而增长。此示例使用在01/29/2019上提交的版本,该版本由2000个由四位发言者获得的英语数字0到9的录制组成。这个版本中的两个发言者都是美国英语的母语人士,两个发言者是英语的非男性扬声器,与比利时法国和德语口音。数据以8000 Hz采样。
有关此数据集的其他方法,包括小波散射,请参见基于小波散射和深度学习的语音数字识别.
使用audioDatastore管理数据访问并确保录制的随机分为培训和测试集。设定位置例如,您计算机上FSDD录制文件夹的位置:
pathToRecordingsFolder =“/ home / user / free-spoken-digit-dataset /录音”;位置= pathToRecordingsFolder;
点audioDatastore到新位置。
广告= audiodatastore(位置);
辅助函数helpergenLabels从FSDD文件创建标签的分类数组。列出类和每个类的例子数量。
ads.Labels = helpergenLabels(广告);总结(ads.Labels)
2 200 3 200 4 200 5 200 6 200 7 200 8 200 9 200
改变了数据存储
首先将FSDD分解为训练集和测试集。将80%的数据分配给训练集,并保留20%给测试集。
rng默认的;广告= shuffle(广告);[adsTrain, adsTest] = splitEachLabel(广告,0.8);countEachLabel (adsTrain)
ans =.10×2表标签计数_____ _____ 0 160 1 160 2 160 3 160 4 160 5 160 6 160 7 160 8 160 9 160
接下来,使用helper函数为训练和测试数据创建CWT过滤器库和转换后的数据存储,helperDigitScalogram.转换后的数据存储将每个记录转换为长度为8192的信号,在GPU上计算标量图,并将数据收集回CPU。
重置(gpuDevice(1)) fb = cwtfilterbank(“SignalLength”, 8192);adsSCTrain =变换(adsTrain @(音频、信息)helperDigitScalogram(音频、信息、fb),“IncludeInfo”,真正的);adsSCTest =变换(adsTest @(音频、信息)helperDigitScalogram(音频、信息、fb),“IncludeInfo”,真正的);
CNN深处
构建一个深度CNN,用转换后的数据存储进行训练,adscTrain.和第一个示例一样,网络没有得到优化。要点是使用GPU计算出内存不足数据的标量图来显示工作流。
numClasses = 10;dropoutProb = 0.2;numF = 12;[imageInputLayer([101 8192 1]))卷积2dlayer (5,numF,)'填充',“相同”maxPooling2dLayer(3,“步”2,'填充',“相同”) convolution2dLayer (3 2 * numF'填充',“相同”maxPooling2dLayer(3,“步”2,'填充',“相同”) convolution2dLayer(3、4 * numF,'填充',“相同”maxPooling2dLayer(3,“步”2,'填充',“相同”) convolution2dLayer(3、4 * numF,'填充',“相同”) batchNormalizationLayer reluLayer卷积2dlayer (3,4*numF,'填充',“相同”)BatchnormalizationLayer rululayer maxpooling2dlayer(2)oploutlayer(dropoutprob)全连接列(numclasses)softmaxlayer类层(“类”类别(ads.Labels));];
设置网络的训练选项。
miniBatchSize = 25;选择= trainingOptions (“亚当”,...“InitialLearnRate”1的军医,...“MaxEpochs”30岁的...“MiniBatchSize”,小匹马,...“洗牌”,“every-epoch”,...“阴谋”,“训练进步”,...'verbose'假的,...“ExecutionEnvironment”,“图形”);
培训网络。
TrousaInnet = Trainnetwork(Adssctrain,图层,选项);
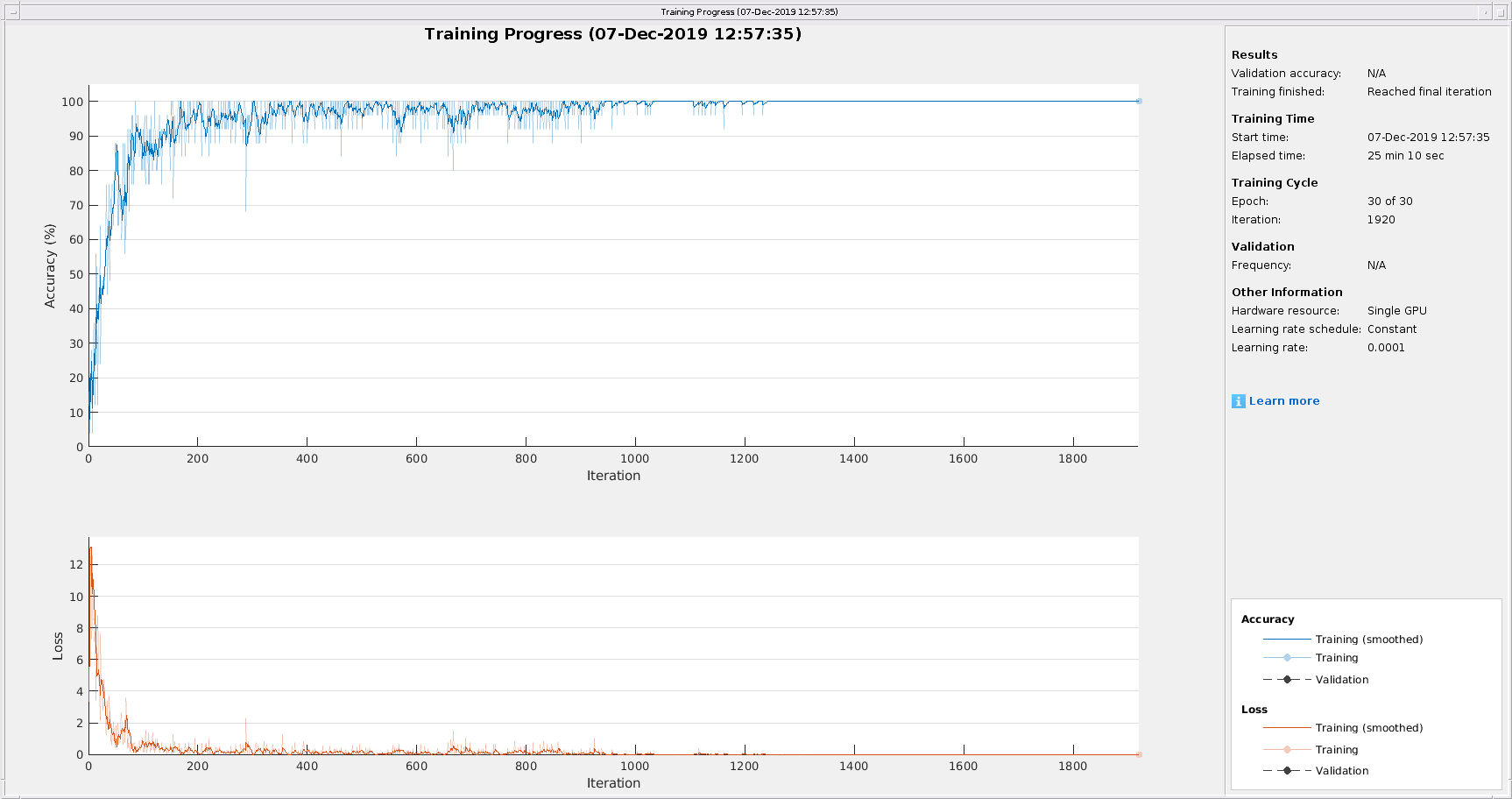
在这个例子中,训练在25分10秒内完成。如果你注释掉对gpuArray在helperDigitScalogram使用CPU获取标度图,训练时间显著增加。在这种情况下,观察到从25分10秒增加到45分38秒。
使用培训的网络预测测试集的数字标签。
Ypredicted =分类(trainedNet adsSCTest,“ExecutionEnvironment”,“CPU”);cnnAccuracy = sum(Ypredicted == adsTest.Labels)/numel(Ypredicted)*100
cnnAccuracy = 96.2500
使用GPU的推断时间大约为22秒。使用CPU时,推断时间增加了一倍,达到45秒。
训练后的网络对测试数据的性能接近96%。这可以与基于小波散射和深度学习的语音数字识别.
总结
这个例子展示了如何使用GPU来加速标量图的计算。该示例提供了有效计算内存中数据和使用转换数据存储从磁盘读取的内存不足数据标量图的最佳工作流。
参考文献
Baim, D. S., W. S. Colucci, E. S. Monrad, H. S. Smith, R. F. Wright, A. Lanoue, D. F. Gauthier, B. J. Ransil, W. Grossman, E. Braunwald。口服米力农治疗严重充血性心力衰竭患者的生存率美国心脏病学会杂志.1986年第7卷第3期,第661-670页。
Goldberger A. L., L. A. N. Amaral, L. Glass, J. M. Hausdorff, P. Ch. Ivanov, R. G. Mark, J. E. miietus, G. B. Moody, C.-K。彭,还有h·e·斯坦利。“PhysioBank, PhysioToolkit和PhysioNet:复杂生理信号新研究资源的组成部分”循环。101卷,编号23:e215-e220。(循环电子页;
http://circ.ahajournals.org/content/101/23/e215.full];2000(6月13日)。cir.101.23.e215 doi: 10.1161/01.。穆迪,g。B。和r。g。马克。" MIT-BIH心律失常数据库的影响"医学与生物工程杂志.20卷。第3页,2001年5 - 6月,第45-50页。(PMID: 11446209)
函数Labels = HelpergenLabels(广告)%此函数仅用于小波工具箱示例。它可能是%在未来的版本中更改或删除。tmp =细胞(元素个数(ads.Files), 1);表达=“[0 - 9]+ _”;为nf = 1:numel(ads.Files) idx = regexp(ads.Files{nf},expression);tmp {nf} = ads.Files {nf} (idx);结束标签=分类(tmp);结束
函数X = helperecgscaloggrams (data,window,useGPU)显示(“计算量图……”);Nsig =大小(数据,1);Nsamp =大小(数据,2);Nsegment = Nsamp /窗口;fb = cwtfilterbank (“SignalLength”,窗户,“声音”,10);ns =长度(fb.cales);x = zeros([ns,window,1,nsig * nsegment],“单一”);开始= 0;如果useGPU data = gpuArray(single(data')); / /数据其他的data =单(数据);结束为ii = 1:Nsig ts = data(:,ii);ts =重塑(ts、窗、Nsegment);ts = (ts-mean (ts)。/ max (abs (ts));为kk = 1:尺寸(ts,2)cfs = fb.wt(ts(:,kk));x(:,:,1,kk + start)=收集(ABS(CFS));结束开始=开始+ Nsegment;如果Mod (ii,50) == 0“处理 ”+ II +“文件用完了”+ nsig)结束结束DISP(“…”);data =收集(数据);结束
函数[x,INFO] = HelperReadspdata(X,INFO)%此函数仅适用于使用小波工具箱示例。它可能会改变或%在将来的释放中删除。N =元素个数(x);如果n> 8192 x = x(1:8192);elseifN < 8192 pad = 8192-N;前置液=地板(垫/ 2);postpad =装天花板(垫/ 2);X = [0 (prepad,1);x;0 (postpad 1)];结束x = x / max (abs (x));结束
函数[dataout,info] = helperdigitscalalogram (audioin,info,fb) audioin = single(audioin);audioin = gpuArray (audioin);audioin = helperReadSPData (audioin);cfs =收集(abs (fb.wt (audioin)));audioin =收集(audioin);dataout = {cfs, info.Label};结束
另请参阅
相关的话题
你也可以从以下列表中选择一个网站: