压力测试的消费信贷违约概率使用面板数据
这个例子展示了如何使用消费信贷面板数据可视化(零售)观察到的违约率在不同的水平。它还显示了如何适应一个模型来预测违约概率(PD)和终身PD值,和执行压力测试分析。
消费贷款的面板数据集允许您识别不同年龄的贷款违约率模式,或年书。您可以使用分数组信息区分违约率不同的评分级别。此外,您可以使用宏观经济信息来评估经济状况如何影响消费者贷款违约率。
一个标准的逻辑回归模型,广义线性模型的一种,可以安装到零售信贷面板数据和没有宏观经济预测,使用fitLifetimePDModel从风险管理工具箱™。尽管同一个模型可以安装使用fitglm从统计和机器学习的工具箱™函数,一生违约概率(PD)模型的版本是专为信贷应用程序,并支持一生PD预测和模型验证工具,包括歧视和准确性情节这个例子所示。金宝app例子还描述了如何适应一个更高级的模型考虑到面板数据影响,广义线性混合效应模型。然而,面板数据集的影响可以忽略不计这个例子和效率的标准物流模式是首选。
逻辑回归模型预测违约概率对所有得分水平,年书,和宏观经济变量的场景。有一个简短的讨论如何预测一生PD价值观,附加功能的指针。歧视的例子展示了模型和模型精度验证和比较模型的工具。在上一节的例子中,逻辑模型是用于压力测试分析,违约的概率模型预测对于一个给定的基线,以及违约概率不良和严重不利的宏观经济情况。
有关更多信息,请参考一生的违约概率模型的概述。参见示例建模和Cox比例风险违约概率遵循相同的工作流程,但是使用Cox回归而不是逻辑回归,也有信息一生PD和寿命预期信贷损失的计算(ECL)。
面板数据描述
主要的数据集(数据)包含以下变量:
ID:贷款标识符。ScoreGroup:贷款信用评分开始时,离散分成三组:高的风险,中等风险,低风险。小无赖:年书。默认的:默认指标。这是反应变量。一年:日历年。
还有一个小的数据集(dataMacro与相应的日历年的宏观经济数据):
一年:日历年。国内生产总值:国内生产总值增长(年)。市场:市场回报率(同比)。
的变量小无赖,一年,国内生产总值,市场是观察到相应的日历年度的结束。比分集团是离散化的原始贷款信用评分时开始。的值1为默认的意味着相应的日历年贷款违约。
还有第三个数据集(dataMacroStress)与基线、不良和严重不良场景的宏观经济变量。此表用于压力测试分析。
这个示例使用模拟数据,但是同样的方法已经成功地应用于实际数据集。
加载面板数据
加载数据和视图的第一个10和最后一行表。面板数据叠加,在某种意义上,观察相同的ID存储在连续的行,创建一个瘦而高、表。面板是不平衡的,因为不是所有的标识都有相同数量的观察。
负载RetailCreditPanelData.mat流(“\ nFirst 10行:\ n”)
第十行:
disp(数据(1:10)):
ID ScoreGroup小无赖默认年__ ___________ ___ ____ ____ 1低风险1 0 1998 1997 1低风险2 0 1低风险1999 1低风险4 0 0 2001 2000 1低风险5 0 1低风险6 0 2002 1低风险7 0 2003 1低风险8 0 2004 2中等风险1 0 1997 2中等风险2 0 1998
流(“最后的10行:\ n”)
最后的10行:
disp(数据(end-9:最终,))
ID ScoreGroup小无赖……___ ____作出96819年违约风险高6 0 0 2004 96820 2003 96819高危7中等风险1 0 1997 96820中等风险2 0 0 1999 96820 1998 96820中等风险中等风险4 0 2000 96820中等风险5 0 2002 2001 96820中等风险6 0 0 2003 96820 96820中等风险7中等风险8 0 2004
nRows =身高(数据);UniqueIDs =独特(data.ID);nIDs =长度(UniqueIDs);流(IDs的总数:% d \ n 'nIDs)
IDs总数:96820
流(“总行数:% d \ n 'nRows)
总行数:646724
违约率由分数组和年书
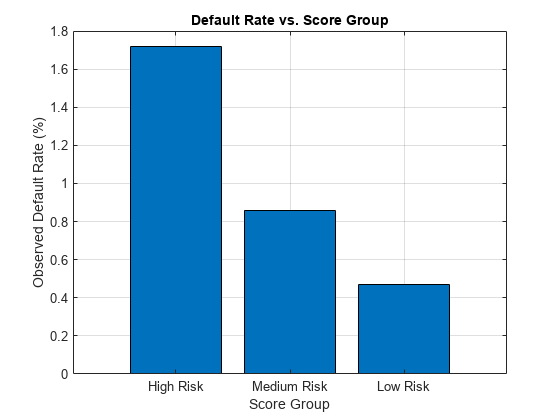
使用信用评分小组作为分组变量来计算每个分数组观察到的违约率。为此,使用groupsummary函数计算的均值默认的变量分组的ScoreGroup变量。阴谋的结果在一个条形图。正如所料,违约率下降随着信贷质量的提高。
DefRateByScore = groupsummary(数据,“ScoreGroup”,“的意思是”,“默认”);NumScoreGroups =身高(DefRateByScore);disp (DefRateByScore)
ScoreGroup GroupCount mean_Default ___________ __________ _______高风险2.0999 e + 05年0.017167中等风险2.1743 e + 05年0.0046784 0.0086006低风险2.193 e + 05
栏(DefRateByScore.ScoreGroup DefRateByScore.mean_Default * 100)标题(“违约率与分数组”)包含(“分数组”)ylabel (的观察到的违约率(%)网格)在
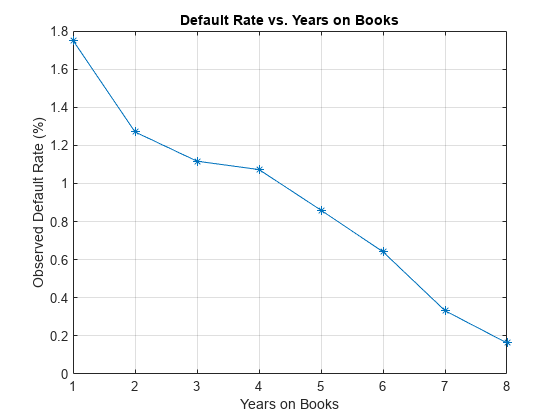
其次,计算违约率由年书(由分组小无赖变量)。由此产生的利率条件一年期违约率。例如,第三年的违约率的书是第三年,贷款违约的比例相对于贷款的数量组合过去的第二年。换句话说,第三年的违约率的行数小无赖=3和默认的= 1,除以的行数小无赖=3。
策划的结果。有明显的下降趋势,违约率下降年书籍数量的增加。年3和4有类似的违约率。然而,目前还不清楚从这个情节是否这是一个贷款产品的特征或宏观经济环境的影响。
DefRateByYOB = groupsummary(数据,“小无赖”,“的意思是”,“默认”);NumYOB =身高(DefRateByYOB);disp (DefRateByYOB)
小无赖GroupCount mean_Default ___ __________ _______ 96820 0.017507 94535 0.012704 92497 0.011168 91068 0.010728 89588 0.0085949 88570 0.006413 61689 0.0033231 8 31957 0.0016272
情节(双(DefRateByYOB.YOB), DefRateByYOB.mean_Default * 100,“- *”)标题(“违约率和年书”)包含(“年书”)ylabel (的观察到的违约率(%)网格)在
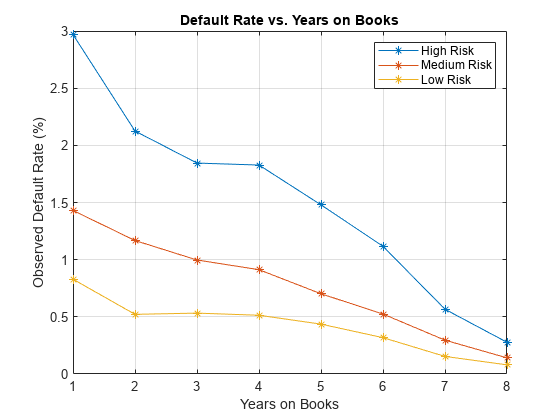
现在,集团通过分数的数量和年书然后阴谋的结果。图显示所有分数组同样的行为随着时间的推移,总体下降的趋势。年3和4是一个异常下降的趋势:利率变平的高的风险组和三年的低风险组。
DefRateByScoreYOB = groupsummary(数据,{“ScoreGroup”,“小无赖”},“的意思是”,“默认”);%显示输出表显示它是结构化的方式%只显示前10行,简洁disp (DefRateByScoreYOB (1:10)):
ScoreGroup小无赖GroupCount mean_Default ___________ ___ __________ _______高风险1 32601 0.029692高危2 31338高0.021252高危3 30138 0.018448 28661 0.014794 29438 0.018276高危风险高危6 28117 0.011168高风险7 19606 0.0056615高风险8 10094 0.0027739中等风险1 31775 0.011676 32373 0.014302中等风险
DefRateByScoreYOB2 =重塑(DefRateByScoreYOB.mean_Default,…NumYOB NumScoreGroups);情节(DefRateByScoreYOB2 * 100,“- *”)标题(“违约率和年书”)包含(“年书”)ylabel (的观察到的违约率(%)传奇(类别(data.ScoreGroup))网格在
年书和日历年
数据包含三个组,或葡萄酒:贷款开始于1997年,1998年和1999年。在1999年后的面板数据开始没有贷款。
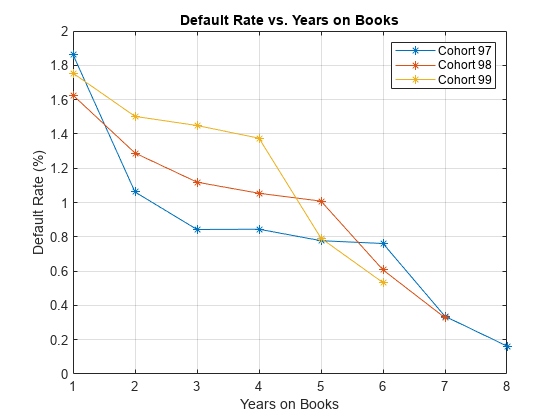
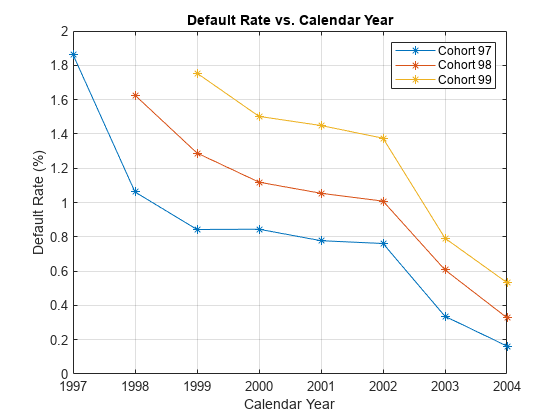
本节展示如何可视化违约率分别为每个队列。所有群组是绘制的违约率,在数年的书籍和日历年度。模式在年书建议贷款产品特点。日历年模式表明宏观经济环境的影响。
从两年到四个在书上,曲线显示三组不同的模式。然而,当策划对历年三组显示类似的行为从2000年到2002年。曲线变平。
%得到id是1997、1998和1999个军团IDs1997 = data.ID (data.YOB &data.year = = = = 1997);IDs1998 = data.ID (data.YOB &data.year = = = = 1998);IDs1999 = data.ID (data.YOB &data.year = = = = 1999);% IDs2000AndUp是未使用的,只有计算表明这是空的,%不贷款在1999年开始IDs2000AndUp = data.ID (data.YOB = = 1 &data.year > 1999);%得到违约率分别为每个队列ObsDefRate1997 = groupsummary(数据(ismember (data.ID IDs1997):),…“小无赖”,“的意思是”,“默认”);ObsDefRate1998 = groupsummary(数据(ismember (data.ID IDs1998):),…“小无赖”,“的意思是”,“默认”);ObsDefRate1999 = groupsummary(数据(ismember (data.ID IDs1999):),…“小无赖”,“的意思是”,“默认”);%的阴谋在年的书情节(ObsDefRate1997.YOB ObsDefRate1997.mean_Default * 100,“- *”)举行在情节(ObsDefRate1998.YOB ObsDefRate1998.mean_Default * 100,“- *”)情节(ObsDefRate1999.YOB ObsDefRate1999.mean_Default * 100,“- *”)举行从标题(“违约率和年书”)包含(“年书”)ylabel (的违约率(%))传说(“97”,“98”,“99”网格)在
%对历年的阴谋年=独特(data.Year);情节(ObsDefRate1997.mean_Default * 100,“- *”)举行在情节(年(2:结束),ObsDefRate1998.mean_Default * 100,“- *”)情节(年(3:结束),ObsDefRate1999.mean_Default * 100,“- *”)举行从标题(违约率与历年的)包含(“年”)ylabel (的违约率(%))传说(“97”,“98”,“99”网格)在
违约率模型使用分数组和年书
可视化数据之后,您可以构建违约率的预测模型。
将面板数据分为训练集和测试集,定义这些集基于ID数字。
NumTraining =地板(0.6 * nIDs);rng (“默认”);%的再现性NumTraining TrainIDInd = randsample (nIDs);TrainDataInd = ismember (data.ID UniqueIDs (TrainIDInd));TestDataInd = ~ TrainDataInd;
第一个模型只使用分数组和数量的年书作为违约率的预测p。违约的可能性被定义为p / (1 - p)。物流涉及的对数概率模型,或日志赔率,预测如下:
1米是一个指标的值1为中等风险贷款和0否则,和类似的1 l为低风险贷款。这是一个标准的方式处理这样的分类预测ScoreGroup。有效地有不同的常数为每个风险级别:啊为高的风险,啊+我为中等风险,啊+基地为低风险。
ModelNoMacro = fitLifetimePDModel(数据(TrainDataInd,:),“物流”,…“ModelID”,“没有宏”,“描述”,“物流模式与小无赖和分数组,但没有宏观变量的,…“IDVar”,“ID”,“LoanVars”,“ScoreGroup”,“AgeVar”,“小无赖”,“ResponseVar”,“默认”);disp (ModelNoMacro.UnderlyingModel)
紧凑的广义线性回归模型:分对数(默认)~ 1 + ScoreGroup +小无赖=二项分布估计系数:估计SE tStat pValue说____ ___________(拦截)-3.2453 0.033768 -96.106 0 ScoreGroup_Medium风险-0.7058 0.037103 -19.023 1.1014 e - 80 ScoreGroup_Low风险-1.2893 0.045635 -28.253 1.3076 e - 175小无赖-0.22693 0.008437 -26.897 2.3578 e - 159 388018观察,388014错误自由度色散:1 x ^ 2-statistic与常数模型:1.83 e + 03,假定值= 0
对于任何数据行,的价值p不是观测到的,只有一个0或1默认指标观察。校准发现模型系数,预测的值p个别行可以恢复的预测函数。
的拦截系数是常数高的风险水平(啊术语),ScoreGroup_Medium风险和ScoreGroup_Low风险系数的调整中等风险和低风险水平(我和艾尔条款)。
违约概率p和日志赔率(左侧模型)在同一方向移动时,预测变化。因此,因为调整中等风险和低风险是消极的,更好的风险水平的违约率较低,如预期。数年的系数书也是消极的,符合年书的数量总体下降的趋势中观察到的数据。
另一种方式以适应模型使用fitglm从统计和机器学习的工具箱™函数。上面的公式表示为
默认~ 1 + ScoreGroup +小无赖
的1 + ScoreGroup占基线常数和风险水平的调整。设置可选参数分布来二项表明物流模型所需的(也就是说,模型与日志赔率左侧),如下:
ModelNoMacro = fitglm(数据(TrainDataInd,:),默认~ 1 + ScoreGroup +小无赖,“分布”,“二”);
在介绍中提到的,一生的优点PD模型的安装版本fitLifetimePDModel信贷是设计应用程序,它可以预测寿命PD和支持模型验证工具,包括歧视和准确性的情节。金宝app有关更多信息,请参见一生的违约概率模型的概述。
占面板数据的影响,使用混合效果更高级的模型可以安装使用fitglme从统计和机器学习的工具箱™函数。尽管这个模型不是安装在本例中,代码很相似:
ModelNoMacro = fitglme(数据(TrainDataInd:)的默认~ 1 + ScoreGroup +小无赖+ (1 | ID)”,“分布”,“二”);
的(1 | ID)添加一个术语的公式随机效应到模型中。这种效应预测的值不了数据,但是组装模型系数。一个随机值是适合每个ID。这额外的配件需求大大增加了计算时间以适应模型在这种情况下,因为非常大量的ID。的面板数据集在这个例子中,随机项的影响可以忽略不计。随机效应的方差系数非常小,模型介绍了随机效应时几乎没有变化。简单的逻辑回归模型是首选,因为它是更快的适应和预测,以及违约率与模型预测本质上是相同的。
预测违约概率进行训练和测试数据。的预测函数预测条件PD值,行,行。我们存储数据比较预测在下一节中对宏观模型。
数据。PDNoMacro = zeros(height(data),1);%样本预测的data.PDNoMacro (TrainDataInd) =预测(ModelNoMacro、数据(TrainDataInd:));%样本外预测data.PDNoMacro (TestDataInd) =预测(ModelNoMacro、数据(TestDataInd:));
一生PD的预测,利用predictLifetime函数。终身的预测,预测的值中的每个ID值所需的预测是预测数据集。例如,预测生存概率数据集的前两个ID。看看条件PD (PDNoMacro列)和终身PD (LifetimePD列)匹配后的第一年每个ID。那一年,一生PD,因为它是一个累积概率增加。有关更多信息,请参见predictLifetime。看到也预期信贷损失计算的例子。
:data1 =数据(1:16);data1。l如果etimePD = predictLifetime(ModelNoMacro,data1); disp(data1)
ID ScoreGroup小无赖默认年PDNoMacro LifetimePD __ ___________ ___ _____ _____ _____ 1低风险1 0 1997 0.0084797 0.0084797 - 1低风险2 0 1998 1999 0.0054027 0.020513 0.0067697 0.015192 - 1低风险3 0 1低风险4 0 2000 0.0043105 0.024735 1低风险5 0 2001 0.0034384 0.028088 - 1低风险6 0 2003 2002 0.0027422 0.030753 - 1低风险7 0 0.0021867 0.032873 1低风险8 0 2004 0.0017435 - 0.034559 2中等风险1 0 1997 0.015097 - 0.015097 2中等风险2 0 1998 0.012069 0.026984 - 2中等风险3 0 2000 1999 0.0096422 0.036366 - 2中等风险4 0 0.0076996 0.043785 - 2中等风险5 0 2001 0.006146 0.049662 - 2中等风险6 0 2002 0.0049043 - 0.054323 2中等风险7 0 2003 0.0039125 0.058023 - 2中等风险8 0 2004 0.0031207 - 0.060962
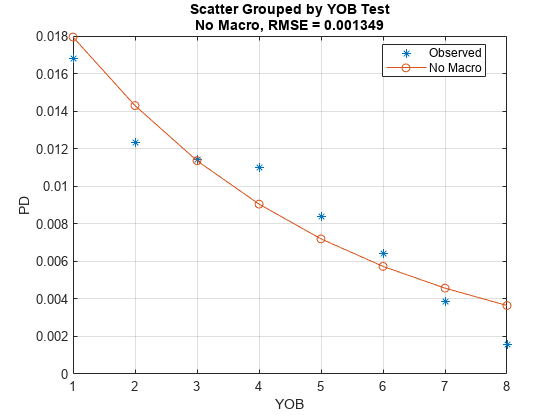
样本内(培训)或样本外可视化(测试)配合使用modelCalibrationPlot。它需要一个分组变量计算违约率和平均预测为每组PD值。使用多年的书籍作为分组变量。
DataSetChoice =“测试”;如果DataSetChoice = =“培训”印第安纳州= TrainDataInd;其他的印第安纳州= TestDataInd;结束modelCalibrationPlot (ModelNoMacro数据(印第安纳州,:),“小无赖”,“DataID”DataSetChoice)

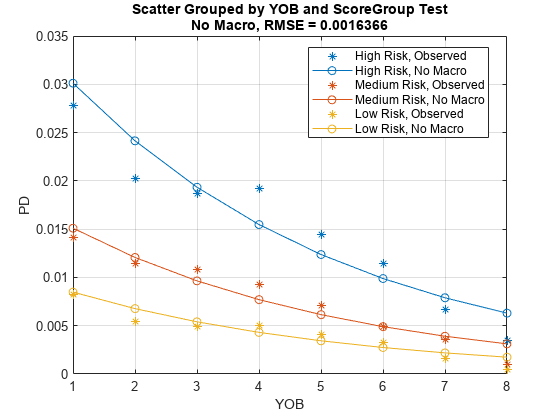
分数组可以作为第二个输入分组变量由分数符合形象化。
modelCalibrationPlot (ModelNoMacro数据(印第安纳州,:),{“小无赖”“ScoreGroup”},“DataID”DataSetChoice)
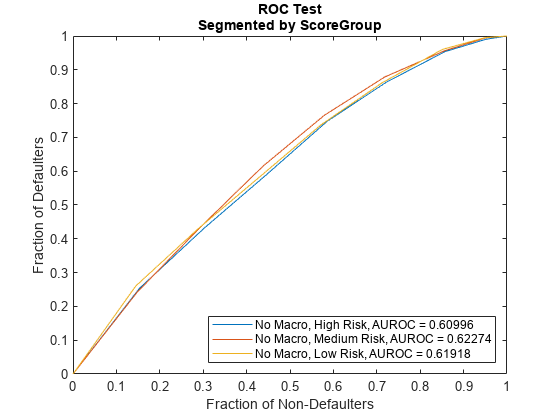
一生PD模型还支持模型验证工具的歧视。金宝app特别是,modelDiscriminationPlot接受者操作特征(ROC)曲线函数创建的阴谋。在一个单独的ROC曲线要求每个分数组。有关更多信息,请参见modelDiscriminationPlot。
modelDiscriminationPlot (ModelNoMacro数据(印第安纳州,:),“SegmentBy”,“ScoreGroup”,“DataID”DataSetChoice)
违约率模型包括宏观经济变量
趋势预测与以前的模型,作为年书的函数,有非常正则减少模式。然而,数据显示了一些偏离这一趋势。试图解释这些偏差,增加国内生产总值年增长率(所代表的国内生产总值变量)和股票市场的年回报率(所代表的市场对模型变量)。
扩展数据集添加一列国内生产总值,一个用于市场,使用的数据dataMacro表。
data =加入(数据、dataMacro);disp(数据(1:10)):
ID ScoreGroup小无赖违约PDNoMacro GDP市场__ ___________ ___ ____ ____ ____专攻1低风险1 0 1997 0.0084797 2.72 7.61 1低风险2 0 1998 0.0067697 3.57 26.24 1低风险3 0 1999 0.0054027 2.86 18.1 1低风险4 0 2000 0.0043105 2.43 3.19 1低风险5 0 2001 0.0034384 1.26 -10.51 1低风险6 0 2003 2002 0.0027422 -0.59 -22.95 1低风险7 0 0.0021867 0.63 2.78 1低风险8 0 2004 0.0017435 1.85 9.48 2中等风险1 0 1997 0.015097 2.72 7.61 2中等风险2 0 1998 0.012069 3.57 26.24
符合模型与宏观经济变量,或宏观模型,通过扩展模型公式包括国内生产总值和市场变量。
ModelMacro = fitLifetimePDModel(数据(TrainDataInd,:),“物流”,…“ModelID”,“宏”,“描述”,“物流模式与小无赖,分数组和宏观变量的,…“IDVar”,“ID”,“LoanVars”,“ScoreGroup”,“AgeVar”,“小无赖”,…“MacroVars”,{“国内生产总值”,“市场”},“ResponseVar”,“默认”);disp (ModelMacro.UnderlyingModel)
紧凑的广义线性回归模型:分对数(默认)~ 1 + GDP ScoreGroup +小无赖+ +市场=二项分布估计系数:估计SE tStat pValue __________ ___________和___________(拦截)-2.667 0.10146 -26.287 2.6919 e - 152 ScoreGroup_Medium风险-0.70751 0.037108 -19.066 4.8223 e - 81 ScoreGroup_Low风险-1.2895 0.045639 -28.253 1.2892 e - 175小无赖-0.32082 0.013636 -23.528 2.0867 e - 122 GDP市场-0.12295 0.039725 -3.095 0.0019681 -0.0071812 0.0028298 -2.5377 0.011159 388018年观察,388012错误自由度色散:1 x ^ 2-statistic与常数模型:1.97 e + 03,假定值= 0
这两个宏观经济变量显示负的系数,符合直觉,更高的经济增长降低违约率。
使用预测函数来预测条件PD。说明,这是如何预测条件PD使用宏模型训练和测试数据。结果被存储为一个新列数据表。一生PD预测也是支持的金宝apppredictLifetime功能,如所示违约率模型使用分数组和年书部分。
数据。PD米一个cro = zeros(height(data),1);%样本预测的data.PDMacro (TrainDataInd) =预测(ModelMacro、数据(TrainDataInd:));%样本外预测data.PDMacro (TestDataInd) =预测(ModelMacro、数据(TestDataInd:));
模型精度和歧视情节为模型提供现成的比较工具。
可视化样本内和样本外使用modelCalibrationPlot。通过预测的模型没有宏观经济变量作为参考模型。情节都使用年书作为单一分组变量,然后使用分数作为第二组分组变量。
DataSetChoice =“测试”;如果DataSetChoice = =“培训”印第安纳州= TrainDataInd;其他的印第安纳州= TestDataInd;结束modelCalibrationPlot (ModelMacro数据(印第安纳州,:),“小无赖”,“ReferencePD”data.PDNoMacro(印第安纳州),“ReferenceID”ModelNoMacro.ModelID,“DataID”DataSetChoice)


modelCalibrationPlot (ModelMacro数据(印第安纳州,:),{“小无赖”,“ScoreGroup”},“ReferencePD”data.PDNoMacro(印第安纳州),“ReferenceID”ModelNoMacro.ModelID,“DataID”DataSetChoice)
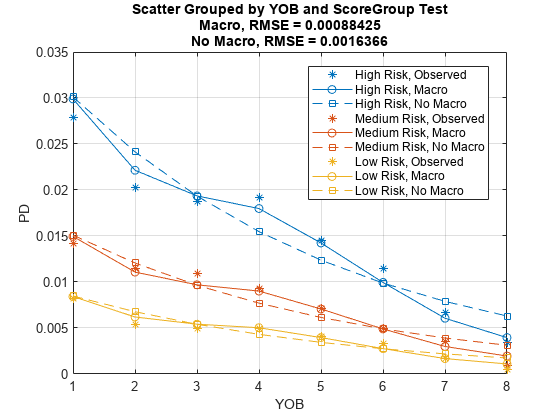
预测的准确性显著提高模型相比,没有宏观经济变量。预测条件PD值更紧密地跟随模式,观察到的违约率和均方根误差(RMSE)报道时小得多的宏观经济变量都包括在模型中。
绘制ROC曲线的宏观模型和模型没有宏观经济变量来比较他们的性能对于模型的歧视。
modelDiscriminationPlot (ModelMacro数据(印第安纳州,:),“ReferencePD”data.PDNoMacro(印第安纳州),“ReferenceID”ModelNoMacro.ModelID,“DataID”DataSetChoice)
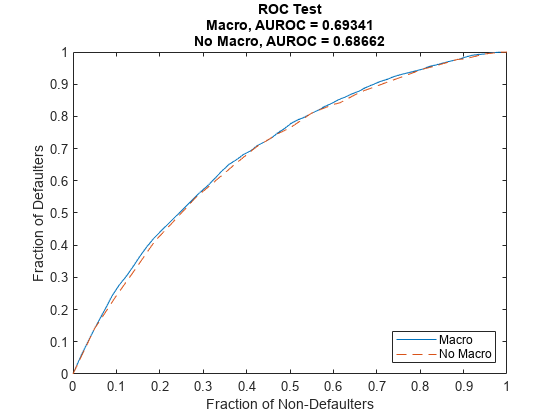
客户的排名的歧视措施的风险。两种模型执行同样的,只有很小的进步,当宏观经济变量添加到模型中。这意味着两种模型做一个类似的工作分离低风险、中等风险和高风险客户,给客户提供更高的PD值更高的风险。
尽管歧视两种模型的性能是相似的,宏观的PD值更准确的预测模型。使用这两种歧视和准确性工具对模型验证和模型的比较很重要。
压力测试的违约概率
使用安装宏观模型对预测的违约概率。
假设以下是压力场景提供的宏观经济变量,例如,通过监管机构。
disp (dataMacroStress)
国内生产总值(GDP)市场专攻基线2.27 - 15.02 -0.22 - -5.64 1.31 - 4.56严重不良
建立了一个基本数据表预测违约的概率。这是一个虚拟的数据表,为每个组合分数组一行,数年的书。
dataBaseline =表;[ScoreGroup,小无赖]= meshgrid (1: NumScoreGroups, 1: NumYOB);dataBaseline。ScoreGroup=categorical(ScoreGroup(:),1:NumScoreGroups,…类别(data.ScoreGroup),“顺序”,真正的);dataBaseline。小无赖=小无赖(:); dataBaseline.ID = ones(height(dataBaseline),1); dataBaseline.GDP = zeros(height(dataBaseline),1); dataBaseline.Market = zeros(height(dataBaseline),1);
预测,设定相同的宏观经济环境(基线、不良或严重不良)所有的分数组合组和年书的数量。
%基线预测违约的概率dataBaseline.GDP (:) = dataMacroStress.GDP (“基线”);dataBaseline.Market (:) = dataMacroStress.Market (“基线”);dataBaseline。PD=预测(米odelMacro,dataBaseline);%预测违约的概率在不利的情况下dataAdverse = dataBaseline;dataAdverse.GDP (:) = dataMacroStress.GDP (“不良”);dataAdverse.Market (:) = dataMacroStress.Market (“不良”);dataAdverse。PD=预测(米odelMacro,dataAdverse);%的概率预测违约严重不良场景dataSevere = dataBaseline;dataSevere.GDP (:) = dataMacroStress.GDP (“严重”);dataSevere.Market (:) = dataMacroStress.Market (“严重”);dataSevere。PD=预测(米odelMacro,dataSevere);
可视化的平均预测违约概率下分数组三个替代监管情况。在这里,所有分数组隐式加权平均。然而,预测也可以在贷款水平对于任何给定的投资组合的预期违约率符合贷款投资组合的实际分布。相同的可视化可以单独为每个分数组产生。
PredPDYOB = 0 (NumYOB, 3);PredPDYOB(: 1) =意味着(重塑(dataBaseline.PD, NumYOB NumScoreGroups), 2);PredPDYOB(:, 2) =意味着(重塑(dataAdverse.PD, NumYOB NumScoreGroups), 2);PredPDYOB(:, 3) =意味着(重塑(dataSevere.PD, NumYOB NumScoreGroups), 2);图;酒吧(PredPDYOB * 100);包含(“年书”)ylabel (的预期违约率(%))传说(“基线”,“不良”,“严重”)标题(“压力测试,违约概率”网格)在

引用
广义线性模型文档,请参阅广义线性模型。
广义线性混合效应模型文档,请参阅广义线性Mixed-Effects模型。
美国联邦储备理事会(美联储,fed),综合资本分析和评估(CCAR):https://www.federalreserve.gov/bankinforeg/ccar.htm
英格兰银行压力测试:https://www.bankofengland.co.uk/financial-stability
欧洲银行业管理局,欧盟压力测试:https://www.eba.europa.eu/risk-analysis-and-data/eu-wide-stress-testing
另请参阅
fitglm|fitglme|fitLifetimePDModel|预测|predictLifetime|modelDiscrimination|modelDiscriminationPlot|modelCalibration|modelCalibrationPlot|物流|Probit