このページの翻訳は最新ではありません。ここをクリックして、英語の最新版を参照してください。
不均衡データでの分類
この例では、あるクラスに他のクラスよりはるかに多くの観測値が含まれる場合に分類を実行する方法を示します。このようなケースに対処するように設計されているので、はじめに罗斯博斯特アルゴリズムを使用します。不均衡なデータを処理する方法には、名前と値のペアの引数“先前的”または“成本”を使用するものもあります。詳細については、アンサンブル分類における不均衡データまたは一様ではない誤分類コストの処理を参照してください。
この例では、UCI機械学習アーカイブの “封面类型”データ (詳細についてはhttps://archive.ics.uci.edu/ml/datasets/Covertypeを参照) を使用します。このデータでは、森林被覆の種類を、標高、土壌の種類、水源までの距離などの予測子に基づいて分類しています。このデータには 500,000 件を超える観測値と 50を超える予測子があるため、分類器の学習や使用に時間がかかります。
布莱克德と 院长[1]がこのデータのニューラル ネット分類について説明しています。これによると、分類精度は 70.6% と見積もられています。罗斯博斯特の分類精度は 81% を超えます。
データの取得
データをワークスペースにインポートします。最後のデータ列を抽出してYという名前の変数に格納します。
枪口('https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz')装载covtype.dataY=covtype(:,end);covtype(:,end)=[];
応答データの調査
表格(Y)
价值计数百分比1211840 36.46%221830148.76%3357546.15%427470.47%594931.63%6173672.99%7205103.53%
データ点は何十万個もあります。クラス 4.に含まれているのは全体の 0.5% 未満です。このような不均衡なデータには、罗斯博斯特アルゴリズムが適切です。
品質評価用のデータの分割
データの半分は分類器のあてはめに使用し、残りの半分は生成された分類器の品質評価に使用します。
rng(10,“龙卷风”)%为了再现性零件=CVY(Y,“坚持”istrain=培训(部分);%拟合数据istest=试验(部分);%质量评估数据制表(Y(istrain))
价值计数百分比1 105919 36.46%2 141651 48.76%3 17877 6.15%4 1374 0.47%5 4747 1.63%6 8684 2.99%7 10254 3.53%
アンサンブルの作成
深いツリーを使用してアンサンブルの精度を上げます。これを行うため、決定分岐の最大数がNになるように木を設定します。Nは学習標本内の観測値の数です。また、学习者を0.1に設定し、精度が高くなるようにします。データは大規模で、深いツリーがあるため、アンサンブルの作成に時間がかかります。
N=总和(istrain);%训练样本中的观察数t=模板树(“MaxNumSplits”,N);tic rusTree=fitcensemble(covtype(istrain,:),Y(istrain),“方法”,“俄罗斯助推”,...“NumLearningCycles”,1000,“学习者”T“LearnRate”,0.1,“nprint”,100);
培训:成长弱势学习者:100名成长弱势学习者:200名成长弱势学习者:300名成长弱势学习者:400名成长弱势学习者:500名成长弱势学习者:600名成长弱势学习者:700名成长弱势学习者:800名成长弱势学习者:900名成长弱势学习者:1000名
toc
运行时间为242.836734秒。
分類誤差の検査
アンサンブルのメンバー数に対して分類誤差をプロットします。
图;tic图(损失(锈树型、covtype(istest,:)、Y(istest),“模式”,“累积的”));toc
运行时间为164.470086秒。
网格在…上;xlabel(“树的数量”); 伊拉贝尔(“测试分类错误”);
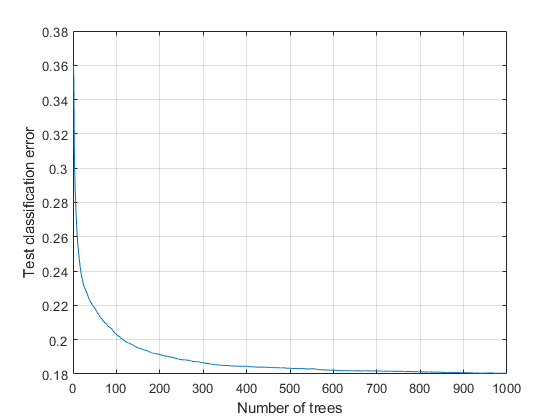
このアンサンブルは、使用しているツリー数が 116以上の場合に、分類誤差が 20% 未満となっています。500本以上の木のため、分類誤差はよりゆっくり低下します。
各クラスの混同行列を、真のクラスのパーセンテージとして調べます。
tic Yfit=预测(锈树型、共价型(istest,:);toc
运行时间为132.353489秒。
混淆图(Y(istest),Yfit,“正常化”,“行规范化”,“行摘要”,“行规范化”)

クラス 2.を除くすべてのクラスで分類精度が 90% を超えています。ただし、クラス 2.はデータの約半分を占めているため、全体の精度はそれほど高くなりません。
アンサンブルの圧縮
アンサンブルは大きくなっています。メソッド契约を使ってデータを除去します。
cmpctRus=紧凑型(锈树);sz(1)=whos(“罗斯特里”); sz(2)=谁(“cmpctRus”);[sz(1).字节sz(2).字节]
ans=1×2109× 1.6579 0.9423
圧縮されたアンサンブルのサイズは、元のアンサンブルの約半分です。
ツリーの半分をcmpctRusから削除します。この操作による予測性能への影響は最小限になると考えられます。これは、1000本の木のうち 500本を使用すればほぼ最適な精度が得られるという観測に基づいています。
cmpctRus=搬迁工人(cmpctRus[500:1000]);sz(3)=谁(“cmpctRus”);sz(3).字节
ans=452868660
圧縮されたアンサンブルで消費されるメモリは、完全な状態のアンサンブルの場合と比べて約 4.分の 1.になります。全体での損失の比率は 19% 未満となります。
L=损失(cmpctRus,covtype(istest,:),Y(istest))
L=0.1833
アンサンブルの精度にバイアスがある可能性があるため、新しいデータについての予測精度は異なる場合があります。このバイアスが発生するのは、アンサンブルサイズの圧縮にアンサンブルの評価と同じデータが使用されるためです。必要なアンサンブルサイズについて不偏推定値を得るには、交差検証を実行します。ただし、この処理は時間がかかります。
参照
[1] Blackard,J.A.和D.J.Dean.“人工神经网络和判别分析在从制图变量预测森林覆盖类型方面的比较精度”,《农业计算机与电子》第24卷,第3期,1999年,第131-151页。
参考
契约|混淆图|CVD分区|菲特森布尔|损失|预测|脱贫工人|制表|模板树|测试|训练
関連するトピック
您还可以从以下列表中选择网站:
