文本分析工具箱
テキストデータの解析とモデル化
文本分析工具箱™には,テキストデータの前処理や解析,モデル化を行うためのアルゴリズムと可視化手法が備わっています。このツールボックスで作成したモデルは,センチメント分析,予知保全,トピックモデリングなどの用途に使用できます。
文本分析工具箱には,機器のログ,ニュースフィード,アンケート,オペレーターのレポート,ソーシャルメディアといったソースの生テキストを処理するためのツールが付属しています。一般的なファイル形式からテキストを抽出し,生テキストを前処理し,個々の単語を抽出して,テキストを数値表現に変換してから統計モデルを作成できます。
LSAやLDA,単語埋め込みなどの機械学習技術を使用して,高次元のテキストデータセットからクラスターを見つけ,特徴量を作成できます。文本分析工具箱で作成した特徴量を他のデータソースの特徴量と組み合わせて、テキストや数値、その他のタイプのデータを使用する機械学習モデルを構築できます。
詳細を見る:


テキストデータの抽出
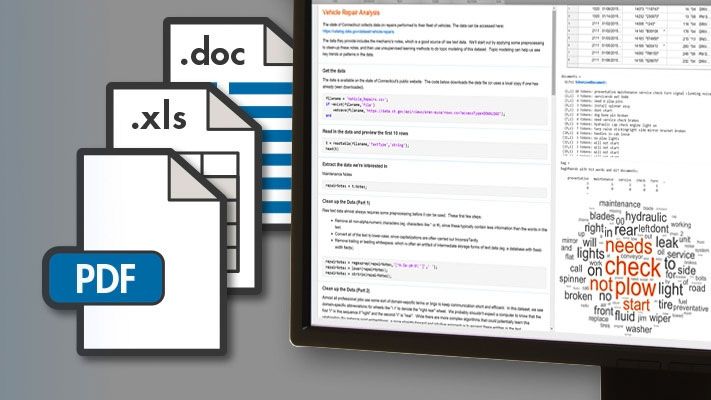
単一のファイルまたは大規模なファイルの集合(PDF、HTML、微软®词®、Excel®ファイルなど)からMATLAB®にテキストデータをインポートします。

Microsoft Word文書の集合からテキストを抽出。

フォントのサイズや色を使用して単語の相対頻度を示すワードクラウド。
言語サポート
文本分析工具箱には,英語や日本語,ドイツ語,韓国語に対応した言語固有の前処理機能が備わっています。ほとんどの機能は,他の言語のテキストでも機能します。

日本語テキストのインポート,準備,解析。
テキストデータのクリーニング
高水準のフィルター処理関数を適用してURL, HTMLタグおよび句読点などの不要なコンテンツを削除し,スペルを修正します。

生テキスト(左)を簡略化し,最も有意な単語(右)を処理し。
ストップワードのフィルター処理と単語の原形への正規化
解析で有意なテキストデータに優先順位をつけるために,一般的な単語や,出現頻度が非常に高い/低い単語,非常に長い/短い単語をフィルター処理により除外します。ボキャブラリを語幹化して原形にするか,レンマ化して辞書の形式にすることで削減し,文書の幅広い意味またはセンチメントに焦点を当てます。

“や”“などのストップワードを文書から削除。
文,トークン品詞の識別
トークン化アルゴリズムを使用して,生テキストを単語の集合に自動的に分割します。コンテキストに合わせて,文の境界や品詞の詳細,その他の関連情報を追加します。

トークン化された文書に品詞や文の詳細を追加。

モデル内で出現頻度が最も高い単語を識別して可視化。
単語の埋め込みとエンコード
word2vecのCBoW(连续Bag-Of-Words)やskip-gramモデルなどの単語埋め込みモデルの学習を行います。fastTextや手套などの事前学習済みのモデルをインポートします。

単語埋め込みを使用して,テキスト散布図のクラスターを可視化。
トピックモデリング
潜在的ディリクレ配分法(LDA)や潜在意味解析(LSA)などの機械学習アルゴリズムを使用して,大規模なテキストデータセットの基本パターン,傾向,複雑な関連性を発見し,可視化します。

嵐のレポートデータ内のトピックを識別。
文書要約とキーワード抽出
1つ以上の文書から要約や関連キーワードを自動抽出し,文書の類似性および重要性を評価します。

テキストから要約を抽出。
センチメント分析
テキストデータ内で表現されている態度や意見を識別し,文が肯定的であるか,中立であるか,否定的であるかを分類します。センチメントをリアルタイムに予測できるモデルを構築します。

肯定的および否定的なセンチメントを予測する単語の識別。
テキストの分類
ディープラーニングにより,テキストのカテゴリを識別できる単語埋め込みを使用してテキスト記述を分類します。

テキストデータ分類のためのディープニューラルネットワークの学習。
テキストの生成
ディープラーニングを使用して,観測されたテキストに基づき新しいテキストを生成します。

ジェイン・オースティンの”高慢と偏見“とディープラーニングのLSTMネットワークを使用したテキストの生成。