广义线性模型GydF4y2Ba
什么是广义线性模型?GydF4y2Ba
线性回归模型描述一个响应和一个或多个预测项之间的线性关系。然而,很多时候存在非线性关系。GydF4y2Ba非线性回归GydF4y2Ba描述一般的非线性模型。一类特殊的非线性模型,称为GydF4y2Ba广义线性模型GydF4y2Ba,使用线性方法。GydF4y2Ba
回想一下,线性模型具有以下特点:GydF4y2Ba
在预测器的每组值下,响应具有正常分布,其平均值GydF4y2Baμ.GydF4y2Ba.GydF4y2Ba
一个系数向量GydF4y2BaB.GydF4y2Ba定义线性组合GydF4y2BaXGydF4y2BaB.GydF4y2Ba的预测因素GydF4y2BaXGydF4y2Ba.GydF4y2Ba
该模型是GydF4y2Baμ.GydF4y2Ba=GydF4y2BaXGydF4y2BaB.GydF4y2Ba.GydF4y2Ba
在广义的线性模型中,这些特征是如下推广:GydF4y2Ba
对于预测器的每一组值,响应都有一个分布GydF4y2Ba正常的GydF4y2Ba那GydF4y2Ba一键GydF4y2Ba那GydF4y2Ba泊松GydF4y2Ba那GydF4y2BaγGydF4y2Ba,或GydF4y2Ba逆高斯GydF4y2Ba,参数包括平均值GydF4y2Baμ.GydF4y2Ba.GydF4y2Ba
一个系数向量GydF4y2BaB.GydF4y2Ba定义线性组合GydF4y2BaXGydF4y2BaB.GydF4y2Ba的预测因素GydF4y2BaXGydF4y2Ba.GydF4y2Ba
一种GydF4y2Ba链接功能GydF4y2BaFGydF4y2Ba将模型定义为GydF4y2BaFGydF4y2Ba(GydF4y2Baμ.GydF4y2Ba) =GydF4y2BaXGydF4y2BaB.GydF4y2Ba.GydF4y2Ba
准备数据GydF4y2Ba
要开始拟合回归,请将数据放入拟合函数期望的形式中。所有回归技术从数组中的输入数据开始GydF4y2BaXGydF4y2Ba响应数据在一个单独的向量中GydF4y2BayGydF4y2Ba或表或数据集数组中的输入数据GydF4y2BaTBL.GydF4y2Ba和响应数据作为列GydF4y2BaTBL.GydF4y2Ba.输入数据的每一行代表一个观察。每一列代表一个预测器(变量)。GydF4y2Ba
对于表或数据集数组GydF4y2BaTBL.GydF4y2Ba,表示响应变量GydF4y2Ba“ResponseVar”GydF4y2Ba名称值对:GydF4y2Ba
mdl = fitglm(tbl,GydF4y2Ba“ResponseVar”GydF4y2Ba那GydF4y2Ba'血压'GydF4y2Ba);GydF4y2Ba
默认情况下,响应变量是最后一列。GydF4y2Ba
您可以使用数字GydF4y2Ba分类GydF4y2Ba预测因子。绝对预测器是从一组固定的可能性中取值。GydF4y2Ba
对于数字数组GydF4y2Ba
XGydF4y2Ba,用。表示分类预测因子GydF4y2Ba“分类”GydF4y2Ba名称-值对。例如,指示预测因子GydF4y2Ba2GydF4y2Ba和GydF4y2Ba3.GydF4y2Ba其中6个是绝对的:GydF4y2Bamdl = fitglm(x,y,GydF4y2Ba“分类”GydF4y2Ba,[2,3]);GydF4y2Ba%或等价GydF4y2Bamdl = fitglm(x,y,GydF4y2Ba“分类”GydF4y2Ba,逻辑([0 1 1 0 0]));GydF4y2Ba
对于表或数据集数组GydF4y2Ba
TBL.GydF4y2Ba,拟合函数假设这些数据类型是分类的:GydF4y2Ba逻辑向量GydF4y2Ba
分类向量GydF4y2Ba
字符数组GydF4y2Ba
字符串数组GydF4y2Ba
如果要指示数值预测器是分类的,请使用GydF4y2Ba
“分类”GydF4y2Ba名称-值对。GydF4y2Ba
表示丢失的数字数据为GydF4y2Ba南GydF4y2Ba.表示其他数据类型的缺失数据,请参阅GydF4y2Ba失踪组值GydF4y2Ba.GydF4y2Ba
对于一个GydF4y2Ba
“二”GydF4y2Ba数据矩阵模型GydF4y2BaXGydF4y2Ba, 响应GydF4y2BayGydF4y2Ba可:GydF4y2Ba二进制列向量 - 每个条目代表成功(GydF4y2Ba
1GydF4y2Ba)或失败(GydF4y2Ba0.GydF4y2Ba).GydF4y2Ba整数的两列矩阵 - 第一列是每次观察中取得成功的数量,第二列是该观察中的试验次数。GydF4y2Ba
对于一个GydF4y2Ba
“二”GydF4y2Ba模型与表或数据集GydF4y2BaTBL.GydF4y2Ba:GydF4y2Ba使用GydF4y2Ba
ResponseVarGydF4y2Ba的列的名称-值对GydF4y2BaTBL.GydF4y2Ba这给出了每种观察中的成功次数。GydF4y2Ba使用GydF4y2Ba
Binomialsize.GydF4y2Ba的列的名称-值对GydF4y2BaTBL.GydF4y2Ba这给出了每次观察中的试验数量。GydF4y2Ba
用于输入和响应数据的数据集数组GydF4y2Ba
例如,从Excel创建数据集数组GydF4y2Ba®GydF4y2Ba电子表格:GydF4y2Ba
ds =数据集(GydF4y2Ba'xlsfile'GydF4y2Ba那GydF4y2Ba“hospital.xls”GydF4y2Ba那GydF4y2Ba...GydF4y2Ba'readobsnames'GydF4y2Ba,真正的);GydF4y2Ba
从工作区变量创建数据集数组:GydF4y2Ba
负载GydF4y2BacarsmallGydF4y2BaDS =数据集(MPG,重量);ds.year =序数(model_year);GydF4y2Ba
输入和响应数据的表GydF4y2Ba
要从工作区变量创建表:GydF4y2Ba
负载GydF4y2BacarsmallGydF4y2BaTBL =表(MPG,重量);tbl.year =序数(model_year);GydF4y2Ba
数字矩阵的输入数据,数字向量的响应GydF4y2Ba
例如,要从工作区变量创建数字数组:GydF4y2Ba
负载GydF4y2BacarsmallGydF4y2BaX =[重量马力汽缸Model_Year];y = MPG;GydF4y2Ba
从Excel电子表格创建数字数组:GydF4y2Ba
[x,xnames] = xlsread(GydF4y2Ba“hospital.xls”GydF4y2Ba);y = X (:, 4);GydF4y2Ba反应y为收缩压GydF4y2Bax(:,4)= [];GydF4y2Ba从X矩阵中去掉yGydF4y2Ba
请注意非数字项,例如GydF4y2Ba性别GydF4y2Ba,不出现在GydF4y2BaXGydF4y2Ba.GydF4y2Ba
选择广义的线性模型和链接功能GydF4y2Ba
通常,你的数据表明了广义线性模型的分布类型。GydF4y2Ba
| 响应数据类型GydF4y2Ba | 建议的模型分布式GydF4y2Ba |
|---|---|
| 任何实数GydF4y2Ba | '普通的'GydF4y2Ba |
| 任何正数GydF4y2Ba | '伽玛'GydF4y2Ba或GydF4y2Ba逆高斯分布的GydF4y2Ba |
| 任何一个非负整数GydF4y2Ba | “泊松”GydF4y2Ba |
从0到的整数GydF4y2BaNGydF4y2Ba, 在哪里GydF4y2BaNGydF4y2Ba是一个固定的正值吗GydF4y2Ba |
“二”GydF4y2Ba |
使用该模型分发类型设置GydF4y2Ba分布GydF4y2Ba名称-值对。在选择模型类型之后,选择一个链接函数来映射平均值GydF4y2Baμ.GydF4y2Ba和线性预测器GydF4y2BaXB.GydF4y2Ba.GydF4y2Ba
| 价值GydF4y2Ba | 描述GydF4y2Ba |
|---|---|
“comploglog”GydF4y2Ba |
日志(日志((1 -GydF4y2Baμ.GydF4y2Ba))) =GydF4y2BaXB.GydF4y2Ba |
|
μ.GydF4y2Ba=GydF4y2BaXB.GydF4y2Ba |
|
日志(GydF4y2Baμ.GydF4y2Ba) =GydF4y2BaXB.GydF4y2Ba |
|
日志(GydF4y2Baμ.GydF4y2Ba/ (1 -GydF4y2Baμ.GydF4y2Ba)) =GydF4y2BaXB.GydF4y2Ba |
|
日志(日志(GydF4y2Baμ.GydF4y2Ba)) =GydF4y2BaXB.GydF4y2Ba |
“probit”GydF4y2Ba |
φ.GydF4y2Ba1GydF4y2Ba(GydF4y2Baμ.GydF4y2Ba) =GydF4y2BaXB.GydF4y2Ba,其中φ是正常(高斯)累积分布函数GydF4y2Ba |
“互惠”GydF4y2Ba,默认为发行版GydF4y2Ba'伽玛'GydF4y2Ba |
μ.GydF4y2Ba1GydF4y2Ba=GydF4y2BaXB.GydF4y2Ba |
|
μ.GydF4y2BaP.GydF4y2Ba=GydF4y2BaXB.GydF4y2Ba |
表格的细胞阵列GydF4y2Ba |
用户指定的链接功能(参见GydF4y2Ba自定义链接功能GydF4y2Ba)GydF4y2Ba |
非默认链接功能主要适用于二项式模型。这些非默认链接功能是GydF4y2Ba“comploglog”GydF4y2Ba那GydF4y2Ba'loglog'GydF4y2Ba,GydF4y2Ba“probit”GydF4y2Ba.GydF4y2Ba
自定义链接功能GydF4y2Ba
link函数定义了这种关系GydF4y2BaFGydF4y2Ba(GydF4y2Baμ.GydF4y2Ba) =GydF4y2BaXB.GydF4y2Ba在平均响应之间GydF4y2Baμ.GydF4y2Ba线性组合GydF4y2BaXB.GydF4y2Ba=GydF4y2BaXGydF4y2Ba*GydF4y2BaB.GydF4y2Ba的预测因素。您可以选择一个内置的链接函数,也可以通过指定链接函数来定义自己的链接函数GydF4y2BaflGydF4y2Ba,它的导数GydF4y2BaFD.GydF4y2Ba和它的逆GydF4y2BaFI.GydF4y2Ba:GydF4y2Ba
链接功能GydF4y2Ba
flGydF4y2Ba计算GydF4y2BaFGydF4y2Ba(GydF4y2Baμ.GydF4y2Ba).GydF4y2Ba链接功能的衍生作用GydF4y2Ba
FD.GydF4y2Ba计算GydF4y2BaDF.GydF4y2Ba(GydF4y2Baμ.GydF4y2Ba) /GydF4y2BadµGydF4y2Ba.GydF4y2Ba逆函数GydF4y2Ba
FI.GydF4y2Ba计算GydF4y2BaGGydF4y2Ba(GydF4y2BaXB.GydF4y2Ba) =GydF4y2Baμ.GydF4y2Ba.GydF4y2Ba
你可以用两种等价的方式来指定一个自定义链接函数。每种方法都包含接受表示值的单个数组的函数句柄GydF4y2Baμ.GydF4y2Ba或GydF4y2BaXB.GydF4y2Ba,并返回相同大小的数组。函数句柄要么在单元格数组中,要么在结构中:GydF4y2Ba
表格的细胞阵列GydF4y2Ba
{FL FD FI}GydF4y2Ba,包含三个函数句柄,使用GydF4y2Ba@GydF4y2Ba,定义链接(GydF4y2BaflGydF4y2Ba),链接的导数(GydF4y2BaFD.GydF4y2Ba),以及反向链接(GydF4y2BaFI.GydF4y2Ba).GydF4y2Ba结构GydF4y2Ba
S.GydF4y2Ba@GydF4y2Ba:GydF4y2BaS.GydF4y2Ba。关联GydF4y2BaS.GydF4y2Ba。衍生物GydF4y2BaS.GydF4y2Ba.InverseGydF4y2Ba
例如,使用模型使用GydF4y2Ba“probit”GydF4y2Ba链接功能:GydF4y2Ba
X = [2100 2300 2500 2700 2900GydF4y2Ba...GydF4y2Ba3100 3300 3500 3700 3900 4100 4300]';N = [48 42 31 34 31 21 23 23 21 16 17 21]';Y = [1 2 0 3 8 8 14 17 19 15 17 21];g = fitglm(x,[y n],GydF4y2Ba...GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分配”GydF4y2Ba那GydF4y2Ba“二”GydF4y2Ba那GydF4y2Ba'关联'GydF4y2Ba那GydF4y2Ba“probit”GydF4y2Ba)GydF4y2Ba
g =广义线性回归模型:probit(y) ~ 1 + x1分布=二项式估计系数:估计SE tStat pValue(截距)-7.3628 0.66815 -11.02 3.0701e-28 x1 0.0023039 0.00021352 10.79 3.8274e-27 12个观测值,10个误差自由度GydF4y2Ba
的自定义链接函数可以执行相同的匹配操作GydF4y2Ba“probit”GydF4y2Ba链接功能:GydF4y2Ba
s = {@norminv, @ (x) 1. / normpdf (norminv (x)), @normcdf};g = fitglm(x,[y n],GydF4y2Ba...GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分配”GydF4y2Ba那GydF4y2Ba“二”GydF4y2Ba那GydF4y2Ba'关联'GydF4y2Ba,s)GydF4y2Ba
g =广义线性回归模型:链接(y) ~ 1 + x1分布=二项式估计系数:估计SE tStat pValue(截距)-7.3628 0.66815 -11.02 3.0701e-28 x1 0.0023039 0.00021352 10.79 3.8274e-27 12个观测值,10个误差自由度GydF4y2Ba
这两种型号是一样的。GydF4y2Ba
同样,你也可以写作GydF4y2BaS.GydF4y2Ba作为结构而不是单元格阵列:GydF4y2Ba
s.link = @norminv;s.derivative = @(x)1./normpdf(norminv(norminv(x));s.inverse = @normcdf;g = fitglm(x,[y n],GydF4y2Ba...GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分配”GydF4y2Ba那GydF4y2Ba“二”GydF4y2Ba那GydF4y2Ba'关联'GydF4y2Ba,s)GydF4y2Ba
g =广义线性回归模型:链接(y) ~ 1 + x1分布=二项式估计系数:估计SE tStat pValue(截距)-7.3628 0.66815 -11.02 3.0701e-28 x1 0.0023039 0.00021352 10.79 3.8274e-27 12个观测值,10个误差自由度GydF4y2Ba
选择拟合方法和模型GydF4y2Ba
有两种方法可以创建一个拟合型号。GydF4y2Ba
使用GydF4y2Ba
fitglmGydF4y2Ba当您对广义的线性模型有一个好主意时,或者稍后要调整模型以包括或排除某些术语时。GydF4y2Ba使用GydF4y2Ba
stepwiseglmGydF4y2Ba当您希望使用逐步回归符合您的模型。GydF4y2BastepwiseglmGydF4y2Ba从一个模型(比如一个常数)开始,每次增加或减少一个项,每次以一种贪婪的方式选择最优项,直到无法进一步改进为止。使用逐步拟合找到一个好的模型,一个只有相关条款的模型。GydF4y2Ba结果取决于起始模型。通常,从一个常量模型开始,可以得到一个小模型。从更多的项开始会导致一个更复杂的模型,但它具有更低的均方误差。GydF4y2Ba
在这两种情况下,为拟合函数提供一个模型(它是初始模型)GydF4y2BastepwiseglmGydF4y2Ba).GydF4y2Ba
使用这些方法之一指定一个模型。GydF4y2Ba
简短的模型名称GydF4y2Ba
| 的名字GydF4y2Ba | 模型类型GydF4y2Ba |
|---|---|
“不变”GydF4y2Ba |
模型只包含一个常数(截距)项。GydF4y2Ba |
“线性”GydF4y2Ba |
模型包含每个预测器的截距和线性项。GydF4y2Ba |
“互动”GydF4y2Ba |
模型包含截距、线性项和不同预测因子对的所有乘积(没有平方项)。下载188bet金宝搏GydF4y2Ba |
'purequadratic'GydF4y2Ba |
模型包含截距、线性项和平方项。GydF4y2Ba |
'二次'GydF4y2Ba |
模型包含截距,线性术语,交互和平方术语。GydF4y2Ba |
“聚GydF4y2Ba |
模型是一个多项式,所有项都达到次GydF4y2Ba一世GydF4y2Ba在第一个预测因子,学位GydF4y2BajGydF4y2Ba在第二个预测中,等等。使用数字GydF4y2Ba0.GydF4y2Ba通过GydF4y2Ba9.GydF4y2Ba.例如,GydF4y2Ba“poly2111”GydF4y2Ba有一个常数加上所有的线性和乘积项,也包含预测因子1的平方项。GydF4y2Ba |
计算矩阵GydF4y2Ba
一个条件矩阵GydF4y2BaT.GydF4y2Ba是一个GydF4y2BaT.GydF4y2Ba-经过-(GydF4y2BaP.GydF4y2Ba+ 1)矩阵指定模型中的术语,其中GydF4y2BaT.GydF4y2Ba是术语数量,GydF4y2BaP.GydF4y2Ba为预测变量的个数,+1表示响应变量。的价值GydF4y2BaT (i, j)GydF4y2Ba是变量的指数GydF4y2BajGydF4y2Ba在术语GydF4y2Ba一世GydF4y2Ba.GydF4y2Ba
例如,假设一个输入包含三个预测变量GydF4y2Bax1GydF4y2Ba那GydF4y2Bax2GydF4y2Ba,GydF4y2Bax3GydF4y2Ba和响应变量GydF4y2BayGydF4y2Ba按顺序GydF4y2Bax1GydF4y2Ba那GydF4y2Bax2GydF4y2Ba那GydF4y2Bax3GydF4y2Ba,GydF4y2BayGydF4y2Ba.每一行的GydF4y2BaT.GydF4y2Ba代表一个术语:GydF4y2Ba
[0 0 0]GydF4y2Ba- 持续术语或拦截GydF4y2Ba[0 1 0 0]GydF4y2Ba-GydF4y2Bax2GydF4y2Ba;同样,GydF4y2Bax1 ^ 0 * x2 ^ 1 * x3 ^ 0GydF4y2Ba[1 0 1 0]GydF4y2Ba-GydF4y2Bax1 * x3GydF4y2Ba[2 0 0]GydF4y2Ba-GydF4y2Bax1 ^ 2GydF4y2Ba[0 1 2 0]GydF4y2Ba-GydF4y2Bax2 * (x3 ^ 2)GydF4y2Ba
这GydF4y2Ba0.GydF4y2Ba在每一项的末尾表示响应变量。通常,项矩阵中的零列向量表示响应变量的位置。如果在矩阵和列向量中有预测器和响应变量,则必须包括GydF4y2Ba0.GydF4y2Ba获取每行最后一列中的响应变量。GydF4y2Ba
公式GydF4y2Ba
模型规范的公式是表单的字符向量或字符串标量GydF4y2Ba
'GydF4y2Ba那GydF4y2BayGydF4y2Ba〜GydF4y2Ba术语GydF4y2Ba'GydF4y2Ba
yGydF4y2Ba是响应名称。GydF4y2Ba术语GydF4y2Ba包含GydF4y2Ba变量名称GydF4y2Ba
+GydF4y2Ba包含下一个变量GydF4y2Ba-GydF4y2Ba排除下一个变量GydF4y2Ba:GydF4y2Ba定义一种互动,一种术语的产物GydF4y2Ba*GydF4y2Ba定义交互作用和所有低阶项GydF4y2Ba^GydF4y2Ba将预测器提升到一个指数,就像GydF4y2Ba*GydF4y2Ba重复,所以GydF4y2Ba^GydF4y2Ba包括较低的阶数GydF4y2Ba()GydF4y2Ba组条件GydF4y2Ba
小费GydF4y2Ba
默认情况下,公式包括常数(拦截)术语。要从模型中排除常量术语,包括GydF4y2Ba-1GydF4y2Ba的公式。GydF4y2Ba
例子:GydF4y2Ba
'y ~ x1 + x2 + x3'GydF4y2Ba是一个带截距的三变量线性模型。GydF4y2Ba'y ~ x1 + x2 + x3 - 1'GydF4y2Ba是一个无截距的三变量线性模型。GydF4y2Ba'y〜x1 + x2 + x3 + x2 ^ 2'GydF4y2Ba是一个三变量模型,拦截和aGydF4y2Bax2 ^ 2GydF4y2Ba学期。GydF4y2Ba'y ~ x1 + x2^2 + x3'GydF4y2Ba和前面的例子一样,因为GydF4y2Bax2 ^ 2GydF4y2Ba包括A.GydF4y2Bax2GydF4y2Ba学期。GydF4y2Ba'y ~ x1 + x2 + x3 + x1:x2'GydF4y2Ba包括一个GydF4y2Bax1 * x2GydF4y2Ba学期。GydF4y2Ba'y ~ x1*x2 + x3'GydF4y2Ba和前面的例子一样,因为GydF4y2BaX1 *x2 = X1 + x2 + X1:x2GydF4y2Ba.GydF4y2Ba'y ~ x1*x2*x3 - x1:x2:x3'GydF4y2Ba所有的相互作用GydF4y2Bax1GydF4y2Ba那GydF4y2Bax2GydF4y2Ba,GydF4y2Bax3GydF4y2Ba,除了三方互动。GydF4y2Bay ~ x1*(x2 + x3 + x4)'GydF4y2Ba所有的线性项,加上乘积下载188bet金宝搏GydF4y2Bax1GydF4y2Ba和其他变量。GydF4y2Ba
数据拟合模型GydF4y2Ba
使用拟合型号使用GydF4y2BafitglmGydF4y2Ba或GydF4y2BastepwiseglmGydF4y2Ba.在它们之间选择GydF4y2Ba选择拟合方法和模型GydF4y2Ba.对于除了正常分布的人之外的广义线性模型,请给出GydF4y2Ba分布GydF4y2Ba名称-值对,如GydF4y2Ba选择广义的线性模型和链接功能GydF4y2Ba.例如,GydF4y2Ba
mdl = fitglm(x,y,GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分布”GydF4y2Ba那GydF4y2Ba“泊松”GydF4y2Ba)GydF4y2Ba% 要么GydF4y2Bamdl = fitglm(x,y,GydF4y2Ba'二次'GydF4y2Ba那GydF4y2Ba...GydF4y2Ba“分布”GydF4y2Ba那GydF4y2Ba“二”GydF4y2Ba)GydF4y2Ba
检查质量并调整拟合模型GydF4y2Ba
拟合模型后,检验结果。GydF4y2Ba
模型显示GydF4y2Ba
当您输入名称或进入时,线性回归模型显示了多种诊断GydF4y2BaDISP(MDL)GydF4y2Ba.此显示给出了一些基本信息,以检查拟合模型是否充分代表数据。GydF4y2Ba
例如,将泊松模型拟合到由5个不影响响应的预测因子中的2个构建的数据中,并且没有截距项:GydF4y2Ba
RNG(GydF4y2Ba“默认”GydF4y2Ba)GydF4y2Ba重复性的%GydF4y2BaX = randn (100 5);mu = exp(x(:,[1 4 5])* [。4; .2; .3]);y = poissrnd(μ);mdl = fitglm(x,y,GydF4y2Ba...GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分布”GydF4y2Ba那GydF4y2Ba“泊松”GydF4y2Ba)GydF4y2Ba
mdl =广义线性回归模型:log(y) ~ 1 + x1 + x2 + x3 + x4 + x5Estimate SE tStat pValue (Intercept) 0.039829 0.10793 0.36901 0.71212 x1 0.38551 0.076116 5.0647 4.0895e-07 x2 -0.034905 0.086685 -0.40266 0.6872 x3 -0.17826 0.093552 -1.9054 0.056722 x4 0.21929 0.09357 2.3436 0.019097 x5 0.28918 0.1094 2.6432 0.0082126 100个观测值,94个误差自由度p-value = 1.55e-08GydF4y2Ba
注意:GydF4y2Ba
显示中包含每个系数的估计值GydF4y2Ba
估计GydF4y2Ba柱子。这些值合理地附近真实值GydF4y2Ba[0; 4; 0; 0; .2; .3]GydF4y2Ba,可能除了的系数GydF4y2Bax3GydF4y2Ba并不是很近GydF4y2Ba0.GydF4y2Ba.GydF4y2Ba系数估计有一个标准误差列。GydF4y2Ba
报道GydF4y2Ba
pValueGydF4y2Ba(衍生自GydF4y2BaT.GydF4y2Ba预测器1,4和5的定期假设下的统计数据很小。这些是用于创建响应数据的三个预测因子GydF4y2BayGydF4y2Ba.GydF4y2Ba这GydF4y2Ba
pValueGydF4y2Ba为了GydF4y2Ba(拦截)GydF4y2Ba那GydF4y2Bax2GydF4y2Ba和GydF4y2Bax3GydF4y2Ba大于0.01。这三个预测因子未用于创建响应数据GydF4y2BayGydF4y2Ba.这GydF4y2BapValueGydF4y2Ba为了GydF4y2Bax3GydF4y2Ba只是在GydF4y2Ba0。GydF4y2Ba,因此可能被认为是可能重要的。GydF4y2Ba显示包含卡方统计。GydF4y2Ba
诊断情节GydF4y2Ba
诊断绘图可帮助您识别异常值,并查看模型中的其他问题或适合。为了说明这些绘图,请考虑与逻辑链接功能的二项式回归。GydF4y2Ba
这GydF4y2Ba物流模型GydF4y2Ba对比例数据很有用。它定义了比例之间的关系GydF4y2BaP.GydF4y2Ba和重量GydF4y2BaW.GydF4y2Ba由:GydF4y2Ba
日志(GydF4y2BaP.GydF4y2Ba/ (1 -GydF4y2BaP.GydF4y2Ba)] =GydF4y2BaB.GydF4y2Ba1GydF4y2Ba+GydF4y2BaB.GydF4y2Ba2GydF4y2BaW.GydF4y2Ba
这个例子符合二项模型的数据。这些数据是由GydF4y2Bacarbig.matGydF4y2Ba,其中包含各种重量的大型汽车的测量数据。每一个重量GydF4y2BaW.GydF4y2Ba有相应数量的汽车GydF4y2Ba总计GydF4y2Ba以及相应数量的低里程汽车GydF4y2Ba贫穷的GydF4y2Ba.GydF4y2Ba
假设的值是合理的GydF4y2Ba贫穷的GydF4y2Ba跟随GydF4y2Ba一键GydF4y2Ba分布,试验的次数由GydF4y2Ba总计GydF4y2Ba成功的百分比取决于GydF4y2BaW.GydF4y2Ba.这种分布可以通过使用带有链接函数对数的广义线性模型(GydF4y2Baμ.GydF4y2Ba/ (1 -GydF4y2Baμ.GydF4y2Ba)) =GydF4y2BaXGydF4y2BaB.GydF4y2Ba.调用这个链接函数GydF4y2Ba分对数的GydF4y2Ba.GydF4y2Ba
W = [2100 2300 2500 2700 2900 3100GydF4y2Ba...GydF4y2Ba3300 3500 3700 3900 4100 4300]'总= [48 42 31 31 21 23 23 21 16 17 21]';差= [1 2 0 3 8 8 14 17 19 15 17 21]'mdl = fitglm(w,[总计],GydF4y2Ba...GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分布”GydF4y2Ba那GydF4y2Ba“二”GydF4y2Ba那GydF4y2Ba'关联'GydF4y2Ba那GydF4y2Ba分对数的GydF4y2Ba)GydF4y2Ba
MDL =通用线性回归模型:Logit(Y)〜1 + X1分布=二项式估计系数:估计SE TSTAT PVALUE(截距)-13.38 1.394 -9.5986 8.10192-22 x1 0.11212 0.0.00044258 9.4739E-21 3.4739E-21 3.4739E-21 3.4739E-21 3.4739E-21 12观察结果,10次错误自由度分散度:1 chi ^ 2统计与常数型号:242,p值= 1.3e-54GydF4y2Ba
看模型适合数据的程度如何。GydF4y2Ba
plotslice(mdl)GydF4y2Ba

这个拟合看起来相当好,置信范围相当宽。GydF4y2Ba
要查看更多细节,请创建一个杠杆图。GydF4y2Ba
Plotdiagnostics(MDL)GydF4y2Ba

这是典型的由预测变量排序的回归。对于具有相对极端预测值的点(在任意方向上),每个拟合点的杠杆较高,对于具有平均预测值的点,杠杆较低。在有多个预测器的例子中,并且点不是按预测值排序的,这个图可以帮助您确定哪些观察值具有较高的杠杆作用,因为它们是由它们的预测值衡量的离群值。GydF4y2Ba
残差-训练数据的模型质量GydF4y2Ba
有几个残差图可以帮助您发现模型或数据中的错误、异常值或相关性。最简单的残差图是默认的直方图,它显示残差的范围及其频率,以及概率图,它显示残差的分布如何与具有匹配方差的正态分布相比较。GydF4y2Ba
这个例子显示了拟合泊松模型的残差图。数据构造有5个预测器中的2个不影响响应,也没有截取项:GydF4y2Ba
RNG(GydF4y2Ba“默认”GydF4y2Ba)GydF4y2Ba重复性的%GydF4y2BaX = randn (100 5);mu = exp(X(:,[1 4 5])*[2;1;.5]);y = poissrnd(μ);mdl = fitglm(x,y,GydF4y2Ba...GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分布”GydF4y2Ba那GydF4y2Ba“泊松”GydF4y2Ba);GydF4y2Ba
检验残差:GydF4y2Ba
plotResiduals (mdl)GydF4y2Ba
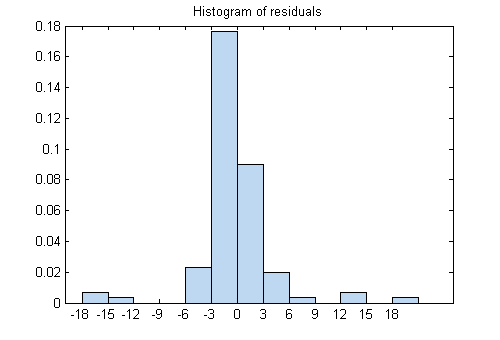
大多数残差聚在0附近,有几个在±18附近。看看另一个残差图。GydF4y2Ba
plotResiduals (mdlGydF4y2Ba'适合'GydF4y2Ba)GydF4y2Ba

大型残差似乎与拟合值的尺寸有很大关系。GydF4y2Ba
也许概率图能提供更多信息。GydF4y2Ba
plotResiduals (mdlGydF4y2Ba“概率”GydF4y2Ba)GydF4y2Ba

现在很清楚。残差不遵循正态分布。相反,它们具有胖的尾部,就像潜在的泊松分布一样。GydF4y2Ba
绘制以了解预测因素效果以及如何修改模型GydF4y2Ba
此示例显示了如何理解每个预测器对回归模型的效果,以及如何修改模型以删除不必要的术语。GydF4y2Ba
用人工数据建立一个预测模型。中的数据不使用第二列和第三列GydF4y2Ba
XGydF4y2Ba.所以你期望这个模型不会显示出对这些预测的依赖。GydF4y2BaRNG(GydF4y2Ba“默认”GydF4y2Ba)GydF4y2Ba重复性的%GydF4y2BaX = randn (100 5);mu = exp(X(:,[1 4 5])*[2;1;.5]);y = poissrnd(μ);mdl = fitglm(x,y,GydF4y2Ba...GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分布”GydF4y2Ba那GydF4y2Ba“泊松”GydF4y2Ba);GydF4y2Ba
检查响应的切片图。这分别显示了每个预测器的效果。GydF4y2Ba
plotslice(mdl)GydF4y2Ba

第一个预测者的规模超过了情节。使用GydF4y2Ba预测因子GydF4y2Ba菜单。GydF4y2Ba

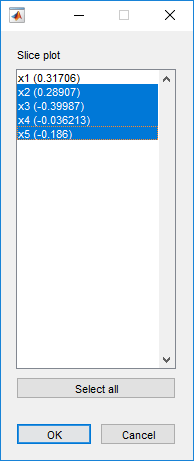

现在很清楚,预测因子2和3几乎没有影响。GydF4y2Ba
您可以拖动单个预测值值,该值由虚线蓝垂直线表示。您还可以选择同时和非同时的置信度界限,这些束缚由虚线的红色曲线表示。拖动预测线确认预测器2和3几乎没有任何影响。GydF4y2Ba
使用任何一个删除不必要的预测器GydF4y2Ba
removeTermsGydF4y2Ba或GydF4y2Ba一步GydF4y2Ba.使用GydF4y2Ba一步GydF4y2Ba可以更安全,以防有意外的重要性,一个术语变得明显后,删除另一个术语。然而,有时GydF4y2BaremoveTermsGydF4y2Ba当GydF4y2Ba一步GydF4y2Ba不继续。在这种情况下,两者给出了相同的结果。GydF4y2Bamdl1 = removeTerms (mdl,GydF4y2Ba“x2 + x3”GydF4y2Ba)GydF4y2Bamdl1 =广义线性回归模型:日志(y) ~ 1 + x1 + x4 + x5 =泊松分布估计系数:估计SE tStat pValue x1(拦截)0.17604 0.062215 2.8295 0.004662 0.98521 0.026393 37.328 5.6696 1.9122 0.024638 77.614 0 x4 e - 305 x5 0.61321 0.038435 15.955 2.6473 e-57 100观察,96错误自由度分散:1 Chi^2-statistic vs. constant model: 4.97e+04, p-value = 0GydF4y2Ba
mdl1 =步骤(mdl,GydF4y2Ba'nsteps'GydF4y2Ba,5,GydF4y2Ba'上'GydF4y2Ba那GydF4y2Ba“线性”GydF4y2Ba)GydF4y2Ba
1.去除x3, Deviance = 93.856, Chi2Stat = 0.00075551, PValue = 0.97807去除x2, Deviance = 96.333, Chi2Stat = 2.4769, PValue = 0.11553 mdl1 =广义线性回归模型:log(y) ~ 1 + x1 + x4 + x5估计SE tStat pValue (Intercept) 0.17604 0.062215 2.8295 0.004662 x1 1.9122 0.024638 77.614 0 x4 0.98521 0.026393 37.328 5.6696e-305 x5 0.61321 0.038435 15.955 2.647e -57 100个观测值,96个误差自由度GydF4y2Ba




预测或模拟对新数据的响应GydF4y2Ba
有三种方法可以使用线性模型来预测对新数据的响应:GydF4y2Ba
预测GydF4y2Ba
这GydF4y2Ba预测GydF4y2Ba方法给出了对平均响应的预测,并且如果要求,则置信界限。GydF4y2Ba
此示例显示了如何使用该示例如何预测和获得预测的置信区间GydF4y2Ba预测GydF4y2Ba方法。GydF4y2Ba
用人工数据建立一个预测模型。中的数据不使用第二列和第三列GydF4y2Ba
XGydF4y2Ba.因此,您希望该模型不会对这些预测器展示很大依赖。逐步构建模型以自动包含相关预测器。GydF4y2BaRNG(GydF4y2Ba“默认”GydF4y2Ba)GydF4y2Ba重复性的%GydF4y2BaX = randn (100 5);mu = exp(X(:,[1 4 5])*[2;1;.5]);y = poissrnd(μ);mdl = stepwiseglm (X, y,GydF4y2Ba...GydF4y2Ba“不变”GydF4y2Ba那GydF4y2Ba'上'GydF4y2Ba那GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分布”GydF4y2Ba那GydF4y2Ba“泊松”GydF4y2Ba);GydF4y2Ba
1.添加x1,偏差= 2515.02869,pvalue = 0 2.添加x4,偏差= 328.39679,chi2stat = 2186.6319,pvalue = 0 3.添加x5,偏差= 96.3326,chi2stat = 232.0642,pvalue = 2.114384e-52.GydF4y2Ba
生成一些新数据,并评估数据的预测。GydF4y2Ba
Xnew = randn(3,5) + repmat([1 2 3 4 5],[3,1]); / /重新定义GydF4y2Ba%的新数据GydF4y2Ba[ynew, ynewci] =预测(mdl Xnew)GydF4y2Baynewci = 1.0e+04 * 0.0821 0.1555 1.2167 2.4811 2.8419 4.9407GydF4y2Ba
Feval.GydF4y2Ba
当您从表或数据集数组构造模型时,GydF4y2BaFeval.GydF4y2Ba通常比预测平均响应更方便GydF4y2Ba预测GydF4y2Ba.然而,GydF4y2BaFeval.GydF4y2Ba不提供置信范围。GydF4y2Ba
这个例子展示了如何使用GydF4y2BaFeval.GydF4y2Ba方法。GydF4y2Ba
用人工数据建立一个预测模型。中的数据不使用第二列和第三列GydF4y2Ba
XGydF4y2Ba.因此,您希望该模型不会对这些预测器展示很大依赖。逐步构建模型以自动包含相关预测器。GydF4y2BaRNG(GydF4y2Ba“默认”GydF4y2Ba)GydF4y2Ba重复性的%GydF4y2BaX = randn (100 5);mu = exp(X(:,[1 4 5])*[2;1;.5]);y = poissrnd(μ);X = array2table (X);GydF4y2Ba创建数据表GydF4y2Bay = array2table (y);tbl = [X y];mdl = stepwiseglm(资源描述,GydF4y2Ba...GydF4y2Ba“不变”GydF4y2Ba那GydF4y2Ba'上'GydF4y2Ba那GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分布”GydF4y2Ba那GydF4y2Ba“泊松”GydF4y2Ba);GydF4y2Ba
1.添加x1,偏差= 2515.02869,pvalue = 0 2.添加x4,偏差= 328.39679,chi2stat = 2186.6319,pvalue = 0 3.添加x5,偏差= 96.3326,chi2stat = 232.0642,pvalue = 2.114384e-52.GydF4y2Ba
生成一些新数据,并评估数据的预测。GydF4y2Ba
Xnew = randn(3,5) + repmat([1 2 3 4 5],[3,1]); / /重新定义GydF4y2Ba%的新数据GydF4y2Baynew =函数宏指令(mdl Xnew (: 1), Xnew (:, 4), Xnew (:, 5))GydF4y2Ba%只需要预测因子1,4,5GydF4y2Ba
Ynew = 1.0e + 04 * 0.1130 1.7375 3.7471GydF4y2Ba
同样,GydF4y2Ba
Ynew = Feval(MDL,Xnew(:,[1 4 5]))GydF4y2Ba%只需要预测因子1,4,5GydF4y2BaYnew = 1.0e + 04 * 0.1130 1.7375 3.7471GydF4y2Ba
随机GydF4y2Ba
这GydF4y2Ba随机GydF4y2Ba方法为指定的预测值值生成新的随机响应值。响应值的分布是模型中使用的分布。GydF4y2Ba随机GydF4y2Ba计算从预测器,估计系数和链接功能的分布的平均值。对于诸如正常的分布,该模型还提供了对响应方差的估计。对于二项式和泊松分布,响应的方差由平均值决定;GydF4y2Ba随机GydF4y2Ba不使用单独的“色散”估计。GydF4y2Ba
此示例显示了如何使用该示例模拟响应GydF4y2Ba随机GydF4y2Ba方法。GydF4y2Ba
用人工数据建立一个预测模型。中的数据不使用第二列和第三列GydF4y2Ba
XGydF4y2Ba.因此,您希望该模型不会对这些预测器展示很大依赖。逐步构建模型以自动包含相关预测器。GydF4y2BaRNG(GydF4y2Ba“默认”GydF4y2Ba)GydF4y2Ba重复性的%GydF4y2BaX = randn (100 5);mu = exp(X(:,[1 4 5])*[2;1;.5]);y = poissrnd(μ);mdl = stepwiseglm (X, y,GydF4y2Ba...GydF4y2Ba“不变”GydF4y2Ba那GydF4y2Ba'上'GydF4y2Ba那GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分布”GydF4y2Ba那GydF4y2Ba“泊松”GydF4y2Ba);GydF4y2Ba
1.添加x1,偏差= 2515.02869,pvalue = 0 2.添加x4,偏差= 328.39679,chi2stat = 2186.6319,pvalue = 0 3.添加x5,偏差= 96.3326,chi2stat = 232.0642,pvalue = 2.114384e-52.GydF4y2Ba
生成一些新数据,并评估数据的预测。GydF4y2Ba
Xnew = randn(3,5) + repmat([1 2 3 4 5],[3,1]); / /重新定义GydF4y2Ba%的新数据GydF4y2BaXnew ysim =随机(mdl)GydF4y2BaYsim = 1111 17121 37457GydF4y2Ba
的预测GydF4y2Ba
随机GydF4y2Ba是泊松样本,所以是整数。GydF4y2Ba评估GydF4y2Ba
随机GydF4y2Ba方法再次,结果变化。GydF4y2BaXnew ysim =随机(mdl)GydF4y2Ba
YSIM = 1175 17320 37126GydF4y2Ba
共享拟合模型GydF4y2Ba
模型显示包含足够的信息,使其他人能够在理论上重新创建模型。例如,GydF4y2Ba
RNG(GydF4y2Ba“默认”GydF4y2Ba)GydF4y2Ba重复性的%GydF4y2BaX = randn (100 5);mu = exp(X(:,[1 4 5])*[2;1;.5]);y = poissrnd(μ);mdl = stepwiseglm (X, y,GydF4y2Ba...GydF4y2Ba“不变”GydF4y2Ba那GydF4y2Ba'上'GydF4y2Ba那GydF4y2Ba“线性”GydF4y2Ba那GydF4y2Ba“分布”GydF4y2Ba那GydF4y2Ba“泊松”GydF4y2Ba)GydF4y2Ba
1.添加x1,偏差= 2515.02869,pvalue = 0 2.添加x4,偏差= 328.39679,chi2stat = 2186.6319,pvalue = 0 3.添加x5,偏差= 96.3326,chi2stat = 232.0642,pvalue = 2.114384e-52.mdl = Generalized Linear regression model: log(y) ~ 1 + x1 + x4 + x5 Distribution = Poisson Estimated Coefficients: Estimate SE tStat pValue (Intercept) 0.17604 0.062215 2.8295 0.004662 x1 1.9122 0.024638 77.614 0 x4 0.98521 0.026393 37.328 5.6696e-305 x5 0.61321 0.038435 15.955 2.6473e-57 100 observations, 96 error degrees of freedom Dispersion: 1 Chi^2-statistic vs. constant model: 4.97e+04, p-value = 0
您也可以通过编程方式访问模型描述。例如,GydF4y2Ba
mdl.cofficients.EstimateGydF4y2Ba
Ans = 0.1760 1.9122 0.9852 0.6132GydF4y2Ba
mdl。公式GydF4y2Ba
ans = log(y)〜1 + x1 + x4 + x5GydF4y2Ba
参考GydF4y2Ba
[1] Collett,D。GydF4y2Ba二进制数据建模GydF4y2Ba.纽约:2002年Chapman&Hall。GydF4y2Ba
多布森GydF4y2Ba广义线性模型导论GydF4y2Ba.纽约:1990年Chapman&Hall。GydF4y2Ba
P. McCullagh和J. A. Nelder。GydF4y2Ba广义线性模型GydF4y2Ba.纽约:1990年Chapman&Hall。GydF4y2Ba
Neter, J., M. H. Kutner, C. J. Nachtsheim, W. Wasserman。GydF4y2Ba应用线性统计模型GydF4y2Ba,第四版。欧文,芝加哥,1996年。GydF4y2Ba
选择网站GydF4y2Ba
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:GydF4y2Ba.GydF4y2Ba
选择GydF4y2Ba网站GydF4y2Ba你也可以从以下列表中选择一个网站:GydF4y2Ba
美洲GydF4y2Ba
- América拉丁GydF4y2Ba(西班牙语)GydF4y2Ba
- 加拿大GydF4y2Ba(英语)GydF4y2Ba
- 美国GydF4y2Ba(英语)GydF4y2Ba
欧洲GydF4y2Ba
- 比利时GydF4y2Ba(英语)GydF4y2Ba
- 丹麦GydF4y2Ba(英语)GydF4y2Ba
- 德国GydF4y2Ba(德语)GydF4y2Ba
- 西班牙GydF4y2Ba(西班牙语)GydF4y2Ba
- 芬兰GydF4y2Ba(英语)GydF4y2Ba
- 法国GydF4y2Ba(Français)GydF4y2Ba
- 爱尔兰GydF4y2Ba(英语)GydF4y2Ba
- 意大利GydF4y2Ba(意大利语)GydF4y2Ba
- 卢森堡GydF4y2Ba(英语)GydF4y2Ba
- 荷兰GydF4y2Ba(英语)GydF4y2Ba
- 挪威GydF4y2Ba(英语)GydF4y2Ba
- Österreich.GydF4y2Ba(德语)GydF4y2Ba
- 葡萄牙GydF4y2Ba(英语)GydF4y2Ba
- 瑞典GydF4y2Ba(英语)GydF4y2Ba
- 瑞士GydF4y2Ba
- 英国GydF4y2Ba(英语)GydF4y2Ba
亚太地区GydF4y2Ba
- 澳大利亚GydF4y2Ba(英语)GydF4y2Ba
- 印度GydF4y2Ba(英语)GydF4y2Ba
- 新西兰GydF4y2Ba(英语)GydF4y2Ba
- 中国GydF4y2Ba
- 日本GydF4y2Ba(日本语)GydF4y2Ba
- 한국GydF4y2Ba(한국어)GydF4y2Ba
