이번역페이지는최신내용을담고있지않습니다。최신내용을영문으로보려면여기를클릭하십시오。
mvregress
다변량선형회귀
구문
설명
예제
서로다른절편을갖는패널데이터에대한다변량회귀모델
서로다른절편을가지면서동일한기울기를갖는다고가정하고다변량회귀모델을패널데이터에피팅합니다。
표본데이터를불러옵니다。
负载(“流感”)
数据集형배열流感는谷歌®쿼리데이터를기반으로하는CDC의전국독감추정값과9개개별지역의추정값을포함합니다。
응답변수와예측변수데이터를추출합니다。
Y =双(流感(:2:end-1));[n、d] = (Y)大小;x = flu.WtdILI;
Y9개의응답변수는지역의독감추정값입니다。1년동안의매주별관측값이존재하므로
= 52입니다。응답변수의차원은지역에대응되므로
= 9입니다。x의예측변수는주별전국독감추정값입니다。
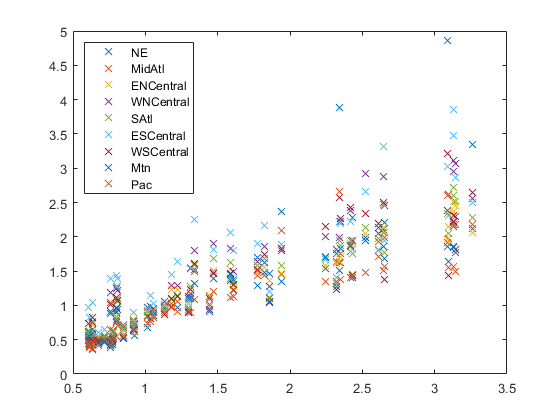
독감데이터를지역별로그룹화하여플로팅합니다。
图;区域= flu.Properties.VarNames (2: end-1);情节(x, Y,“x”)传说(地区,“位置”,“西北”)
다변량회귀모델 를피팅합니다。여기서 이고 이며지역간동시상관관계 를가집니다。
9개의절편항과1개의공통된기울기를가지므로추정할회귀계수의개수
= 10입니다。입력인수X는
×
크기의설계행렬로구성된요소를
개가진셀형배열이어야합니다。
X =细胞(n, 1);为i = 1:n X{i} = [eye(d) repmat(X (i),d,1)];结束(β,σ)= mvregress (X, Y);
β는
차원계수벡터
의추정값을다음과같이포함합니다。
σ는지역간동시상관관계에대한
×
분산——공분산행렬
(
)의추정값을포함합니다。
피팅된회귀모델을플로팅합니다。
B =[β(1:d); repmat(β(结束),1 d)];xx = linspace (5, 3.5);适合=[(大小(xx)), xx] * B;图;h =情节(x, Y,“x”xx,适合“- - -”);为I = 1:d集合(h(d+ I))“颜色”get (h(我),“颜色”));结束传奇(地区,“位置”,“西北”);
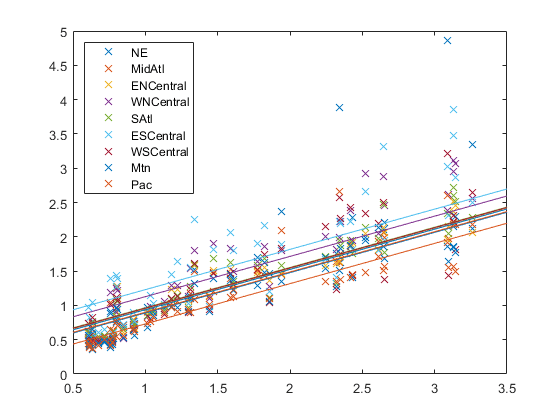
플롯을통해각회귀선이절편은서로다르지만기울기는동일함을알수있습니다。시각적으로검토해보면일부회귀선이다른회귀선보다데이터를더잘피팅하는것으로보입니다。
서로다른기울기를갖는패널데이터에대한다변량회귀
서로다른절편과기울기를갖는다고가정하고최소제곱을사용하여다변량회귀모델을패널데이터에피팅합니다。
표본데이터를불러옵니다。
负载(“流感”);
数据集형배열流感는谷歌®쿼리를기반으로하는CDC의전국독감추정값과9개개별지역의추정값을포함합니다。
응답변수와예측변수데이터를추출합니다。
Y =双(流感(:2:end-1));[n、d] = (Y)大小;x = flu.WtdILI;
Y9개의응답변수는지역의독감추정값입니다。1년동안의매주별관측값이존재하므로
= 52입니다。응답변수의차원은지역에대응되므로
= 9입니다。x의예측변수는주별전국독감추정값입니다。
다변량회귀모델 를피팅합니다。여기서 이고 이며지역간동시상관관계 를가집니다。
9개의절편항과9개의기울기항을가지므로추정할회귀계수의개수
= 18입니다。X는
×
설계행렬로구성된요소를
개가진셀형배열입니다。
X =细胞(n, 1);为i = 1:n X{i} = [eye(d) X (i)*eye(d)];结束(β,σ)= mvregress (X, Y,“算法”,“cwls”);
β는
차원계수벡터
의추정값을다음과같이포함합니다。
피팅된회귀모델을플로팅합니다。
B =[β(1:d);β(d + 1:结束)');xx = linspace (5, 3.5);适合=[(大小(xx)), xx] * B;图;h =情节(x, Y,“x”xx,适合“- - -”);为I = 1:d集合(h(d+ I))“颜色”get (h(我),“颜色”));结束区域= flu.Properties.VarNames (2: end-1);传奇(地区,“位置”,“西北”);
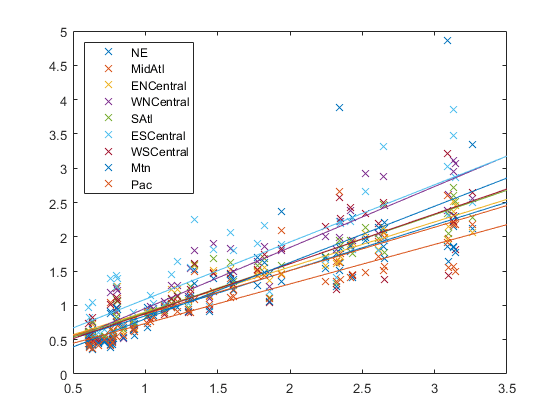
플롯을통해각회귀선이서로다른절편과기울기를가짐을알수있습니다。
단일설계행렬을갖는다변량회귀
모든응답변수차원에대해단일 × 설계행렬을사용하여다변량회귀모델을피팅합니다。
표본데이터를불러옵니다。
负载(“流感”)
数据集형배열流感는谷歌®쿼리를기반으로하는CDC의전국독감추정값과9개개별지역의추정값을포함합니다。
응답변수와예측변수데이터를추출합니다。
Y =双(流感(:2:end-1));[n、d] = (Y)大小;x = flu.WtdILI;
Y9개의응답변수는지역의독감추정값입니다。1년동안의매주별관측값이존재하므로
= 52입니다。응답변수의차원은지역에대응되므로
= 9입니다。x의예측변수는주별전국독감추정값입니다。
×
설계행렬X를만듭니다。회귀에상수항을포함시키기위해1로구성된열을추가합니다。
X =[(大小(X)), X);
다음과같은다변량회귀모델을피팅합니다。
여기서 이고 이며,다음과같은지역간동시상관관계가존재합니다。
9개의절편항과9개의기울기항을가지므로추정할회귀계수는18개입니다。
[β,σ,E, CovB logL] = mvregress (X, Y);
β는
×
계수행렬의추정값을포함합니다。σ는지역간동시상관관계에대한
×
분산——공분산행렬의추정값을포함합니다。E는잔차로구성된행렬입니다。CovB는회귀계수의추정된분산——공분산행렬입니다。logL은마지막반복후의로그가능도목적함수값입니다。
피팅된회귀모델을플로팅합니다。
B =β;xx = linspace (5, 3.5);适合=[(大小(xx)), xx] * B;图h = plot(x,Y,“x”xx,适合“- - -”);为I = 1:d集合(h(d+ I))“颜色”get (h(我),“颜色”))结束区域= flu.Properties.VarNames (2: end-1);传奇(地区,“位置”,“西北”)
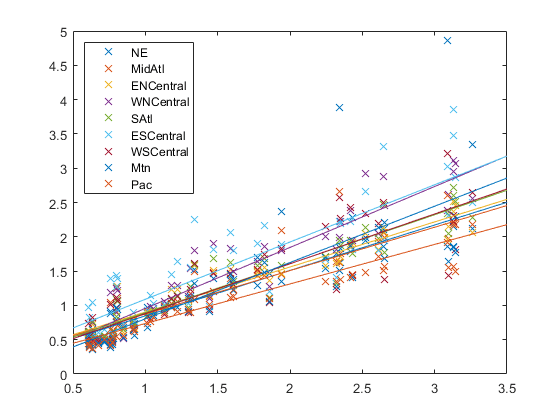
플롯을통해각회귀선이서로다른절편과기울기를가짐을알수있습니다。
입력인수
출력인수
세부정보
참고문헌
[1] Little, Roderick J. A.和Donald B. Rubin。《缺失数据的统计分析》,第2版,霍博肯:约翰·威利父子公司,2002。
[2]孟,小李,唐纳德·鲁宾。“通过ECM算法的最大似然估计。”生物统计学。第80卷,第2期,1993年,267-278页。
塞克斯顿,乔,斯文森。《以EM速度收敛的ECM算法》。第87卷第3期,2000年,第651-662页。
登普斯特,a.p., n.m.莱尔德,D. B.鲁宾。“通过EM算法从不完整数据得到的最大似然”。皇家统计学会杂志。B系列,第39卷,第1期,1977年,第1 - 37页。
你也可以从以下列表中选择一个网站:
