probplot.
概率情节
语法
描述
probplot (创建一个正态概率图,比较中数据的分布y)y正常分布。
probplot.绘制每个数据点y使用标记符号并画出代表理论分布的参考线。如果样本数据为正态分布,则数据点沿参考线出现。参考线连接数据的第一和第三四分位数,并延伸到数据的末端。非正态分布会在数据图中引入曲率。
probplot (将概率绘图添加到所指定的现有概率绘图轴中斧头,___)斧头,使用先前语法中的任何输入参数。
probplot (___, ' noref ')从情节中省略参考线。
例子
创建威布尔概率图
生成样本数据并创建概率图。
生成样本数据。样例x1包含500个带有尺度参数的威布尔分布的随机数一个= 3和形状参数B = 3.样例x2包含具有比例参数的瑞利分布的500个随机数B = 3.
rng (“默认”);%的再现性x1 = wblrnd(3 3[1] 500年);x2 = raylrnd(3[1] 500年);
创建一个概率图来评估数据是否x1和x2来自威布尔分布。
图probplot(“威布尔”, (x1, x2)))传说(“威布尔样本”,'瑞利样品','地点',“最佳”)
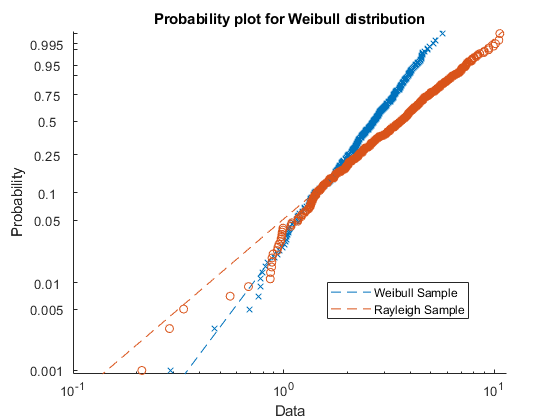
概率图显示数据x1来自威布尔分布,而数据中的数据x2没有。
或者,您可以使用wblplot来绘制威布尔概率图
在概率图中添加拟合线
在同一个图形上创建一个概率图和一条附加的拟合线。
生成尾部中包含约20%异常值的示例数据。样本数据的左尾部包含从具有参数的指数分布中随机生成的10个值mu = 1.右尾包含10个由带参数的指数分布随机生成的值穆= 5.样本数据的中心包含80个由标准正态分布随机生成的值。
rng (“默认”)%的再现性left_tail = -exprnd(1,10,1);Right_tail = Exprnd(5,10,1);中心= Randn(80,1);data = [left_tail;中心; right_tail];
创建一个概率图来评估样本数据是否来自正态分布。
probplot(数据)
画一个t位置-比例尺曲线上同图进行比较数据.
大中型企业的(p =数据,'分配','tlocationscale');t = @(数据,mu,sig,df)cdf('tlocationscale',数据,mu,sig,df);h = probplot(gca,t,p);H.Color =.“r”;h.LineStyle =“- - -”;标题(“{\ bf概率图}”)传说(“正常”,“数据”,“t”,'地点','nw')

绘图表明既不是普通线也不是t由于离群值的存在,位置-比例曲线与尾部吻合得很好。
用半正态概率图确定显著效应
创建半正态概率分布图,以识别实验中的显著影响,以研究可能影响化学制造过程中流量的因素。这四个因子是反应物一个,B,C, 和D.每个因素都有两个水平(高浓度和低浓度)。这个实验在每个因子水平上只包含一个复制。
加载样本数据。
负载流量
表的前四列流量包含因素及其相互作用的设计矩阵。设计矩阵被编码使用1对于高因素水平和-1对于低因素水平。第五纵队流量包含测量的流量。
拟合线性回归模型使用率作为响应变量。使用预测变量一个,B,C,D,以及它们所有的相互作用项。
mdl = fitlm(流量,'率〜a * b * c * d');
计算和存储因子效应估计的绝对值。将模型拟合得到的系数估计值乘以2,得到因子效应估计值。这一步是必要的,因为回归系数测量的影响,一个单位的变化x平均y.但是,效果估计测量两个单位变化x由于设计矩阵编码为-1和1。排除基线测量。注意因子的顺序MDL.可能与原始设计矩阵中的顺序不同。
影响= abs (mdl.Coefficients{2:最终,1}* 2);
使用效果估计的绝对值创建半正常概率图,不包括基线。
图H = probplot('halfnormal',效果);

标记点并格式化图。首先,返回排序后的效果估计的索引值(从最低到最高)。然后使用这些索引值对存储在图形句柄中的概率值进行排序(H(1).ydata).
[b,我]=排序(影响);概率(i) = h (1) .YData;
将文本标签添加到每个点的绘图中。对于每个点,X值是效应估计,Y值是相应的概率。
文本(效果,prob,mdl.coeffitynames(2:结束),“字形大小”8......“VerticalAlignment”,“高级”) h(1)。颜色=“r”;

远离基准线的点代表显著的效果。
使用频率数据创建正常概率曲线
生成模拟频率数据。
Y = 1:10;频率= [2 4 6 7 9 8 7 7 6 5];
使用频率数据创建一个正态概率图。
probplot (y,[],频率)

正常概率图表明数据没有正态分布。
输入参数
输出参数
算法
probplot.将样本数据的量级与给定概率分布的量级匹配。样本数据被排序,根据选择缩放dist,并绘制在x轴上。当dist是'lognormal',“loglogistic”, 或者“威布尔”,缩放是对数。否则,缩放是线性的。y轴表示指定的分配量dist,转换为概率值。比例取决于给定的分布,并不是线性的。
x轴值是我排序值从一个大小的样本N, y轴值为数据经验累积分布函数评价点之间的中点。在未经审查的数据中,中点等于 .
probplot.叠加一条参考线以评估绘图的线性度。如果数据是未经审查的,那么这条线将穿过数据的第一和第三个四分之一。如果数据遭到了审查,那么这条线就会相应移动。如果数据未经审查dist是“正常”的一半,然后probplot.使用Zeroth和第二个四分位数。
您还可以从以下列表中选择一个网站:
