 克利夫角:克利夫莫勒的数学和计算
克利夫角:克利夫莫勒的数学和计算 MATLAB博客
MATLAB博客 用MATLAB进行图像处理
用MATLAB进行图像处理 Simulin金宝appk上的Guy
Simulin金宝appk上的Guy 人工智能
人工智能 开发区域
开发区域 Stuart的MATLAB视频
Stuart的MATLAB视频 头条新闻背后
头条新闻背后 本周文件交换选择
本周文件交换选择 汉斯谈物联网
汉斯谈物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 Matlabユザコミュニティ
Matlabユザコミュニティ 创业公司、加速器和企业家
创业公司、加速器和企业家 自治系统
自治系统使用强化学习玩Pong
在20世纪70年代,Pong是一款非常流行的电子街机游戏。这是一款模拟乒乓球的2D电子游戏,即你有一个球棒(一个矩形),你可以垂直移动并尝试击打一个“球”(一个移动的正方形)。如果球击中了游戏的边界框,它就会像台球一样反弹回来。如果你没抓到球,对手就得分。

后来出现了一款单人游戏《Breakout》,即球能够摧毁屏幕上方的一些方块,并且球棒能够移动到屏幕底部。因此,球棒现在是水平移动而不是垂直移动。
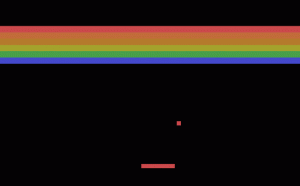
在这篇文章中,我想描述如何教AI玩《Pong》的变体,只是在球反弹时设置一个上限。
正如标题所示,我们将使用强化学习来完成这项任务。在我们的场景中,这绝对是多余的,但谁在乎呢!对于强化学习的第一步来说,简单的街机游戏是一个美丽的游乐场。如果你不熟悉RL,看一下这个简短的指南或这个系列视频这解释了基本概念。
粗略地说,实施强化学习通常包括以下四个步骤:
- 环境建模
- 确定培训方法
- 提出了一个奖励函数
- 培训代理人
对于实现,我们将使用强化学习工具箱在MATLAB的R2019a版本中首次发布。完整的源代码可以在这里找到:https://github.com/matlab-deep-learning/playing-Pong-with-deep-reinforcement-learning.让我们开始吧。
模拟环境
这实际上是所有4个步骤中需要做的最多的工作:你必须执行底层物理,即如果球击中游戏边界或球棒或只是在屏幕上移动会发生什么。此外,你想要可视化当前状态(好吧,这在MATLAB中非常简单)。强化学习工具箱提供了一种基于MATLAB代码或Simulink模型定义自定义环境的方法,我们可以利用它来建模Pong环境。金宝app为此,我们继承了rl.env.MATLABEnvironment并实现了系统的行为。
classdef Environment < rl.env.MATLABEnvironment%属性(相应设置属性的属性)属性指定并初始化环境的必要属性% X球移动的限制XLim = [-1 1]% Y球移动的极限YLim = [-1.5 1.5]%球半径BallRadius = 0.04恒球速度球速= [2 2]
整个源代码可以在这篇文章的末尾找到。虽然我们可以很容易地将环境可视化,但我们并没有使用游戏截图作为强化学习的信息。这样做是另一种选择,更接近人类玩家仅依靠视觉信息。但这也需要需要更多训练的卷积神经网络。相反,我们将游戏的当前状态编码为7个元素的向量,我们称之为观察结果:
| 1 | 2 | 3. | 4 | 5 | 6 | 7 |
| 球的当前x位置 | 球的当前y方向位置 | 改变球的x轴位置 | 球y轴位置的变化 | 球棒的x位置 | 改变球棒的x位置 | 施加在球棒上的力 |
很容易看出这是如何捕捉有关游戏当前状态的所有相关信息。第七个元素(“力”)可能需要更详细的解释:
力基本上是动作的缩放版本,即向右或向左移动球棒。这意味着我们反馈智能体的最后一个动作作为观察的一部分,引入一些记忆的概念,因为智能体可以通过这种方式访问之前的决定。
我们可以从一个随机的球的初始方向开始模拟,直到球击中地板。如果球落在地上,比赛就结束了。
确定培训方法
一般来说,训练算法的选择受到动作空间和观察空间的影响。在我们的例子中,观测值(有七个元素的向量)和操作空间(标量值)都是连续的,这意味着它们可以假设特定范围内的任何浮点数的值。例如,我们将动作限制在范围[-1,1]内。同样,球的x和y位置不允许超过一定的阈值,因为球必须停留在游戏的边界内。
对于本例,我们使用DDPG (深度确定性政策梯度)代理。这个名字指的是一种特定的训练方法,会有其他的选择也对于培训本身,我们需要两个组成部分演员和一个评论家.
这个演员
行为人决定在任何给定的情况下采取何种行动。在每个时间步骤中,它接收来自环境的7个观察结果(如上表所示),并输出一个动作,一个介于-1和1之间的数字。这个动作对应于快速向左移动球棒(-1),向右移动球棒(+1),或者根本不移动球棒(0),所有中间级别都是可能的。actor是一个具有三层全连接和重新激活的神经网络,该网络初始化是由正态分布中的随机值采样。输出的值在-1到1之间。
评论家
评论家是基于最后的行动和最后的观察,计算行动者长期行动的预期回报的实例。结果,评论家接受了两个输入参数。与演员类似,评论家由几个完全连接的层组成,然后是reLu层。现在,我们还没有谈到任何奖励,但很明显,演员的表演(没有双关语)可能非常好(没有错过一个球)或很差(没有成功击中一个球)。评论家应该预测演员的决定的长期结果会是什么。
我们可以用deepNetworkDesigner应用程序定义演员和评论家网络通过拖拽和连接层从一个库。在截图中,你可以看到演员网络(左)和评论家网络(右,注意这两个输入路径)。您还可以从应用程序中导出代码,以编程方式构建网络。

提出了一个奖励函数
一般来说,找到合适的奖励函数(这个过程称为奖励塑造)可能相当棘手。我个人的经验是,这很容易成为一个时间消耗。最近的一些研究结果提出了将这一过程自动化的方法。原则上,这都是关于推动代理按照您希望的方式进行行为:您奖励“好”行为(例如击球),并惩罚“坏”行为(例如错过球)。
从本质上讲,智能体试图积累尽可能多的奖励,而底层神经网络的参数也会相应地不断更新,只要游戏没有达到最终状态(球掉下来)。
为了加强“击球”行为,当球拍击中球时,我们奖励代理一个大的正值。另一方面,我们通过提供负面奖励来惩罚“失手”行为。我们还通过使它与球和球拍之间的距离成比例来塑造这个负值,这激励代理在球即将失球时靠近球(并最终击中它)!
培训代理人
最后一步非常简单,因为它可以归结为MATLAB中的一个函数trainNetwork。然而,训练本身可能需要一些时间,这取决于您的终止条件和可用的硬件(在许多情况下,训练可以在GPU的帮助下加速)。所以,喝杯咖啡,坐下来放松一下,MATLAB会显示一个进度显示,包括最后一个完成章节的奖励总和(即玩游戏,直到球砸到地板上)。您可以在任何时候中断并使用中间结果或让它运行直到完成。训练将在满足终止条件时停止,例如最大集数或特定奖励值。

如果我们在早期阶段手动终止训练,代理仍然表现得非常笨拙:
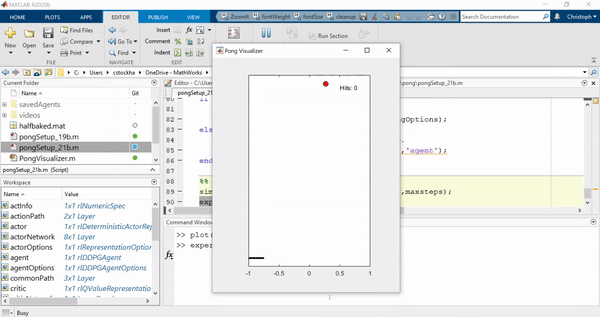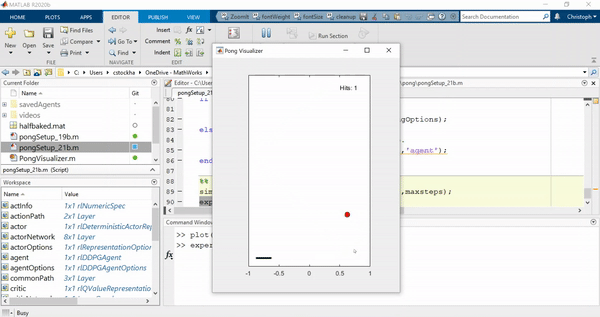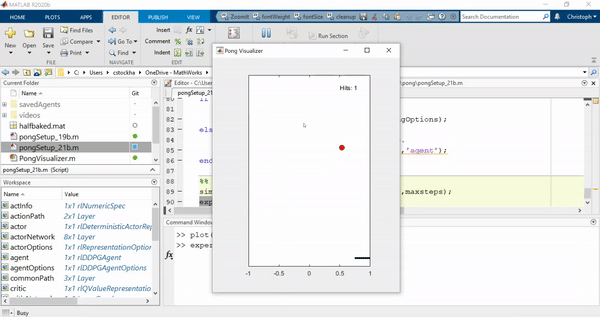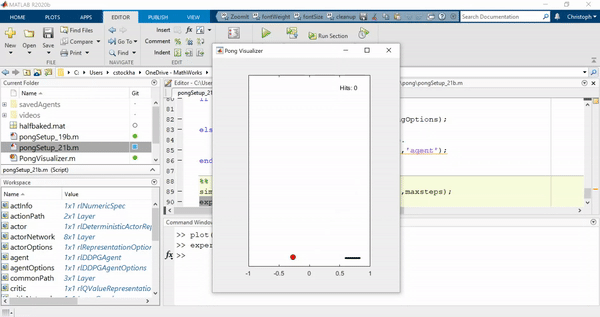
最后,这是训练有素的代理在行动:

结论
显然,你可以在没有强化学习的情况下轻松设计算法发出难闻的气味有效地说,这就像用大锤敲坚果一样——这很有趣。然而,现在人们正在用强化学习来解决真正的问题,这些问题很难或根本无法用传统方法处理。
此外,许多人都有现有的Simulink模型,这些模型非常精确地描金宝app述了复杂的环境,可以很容易地重新用于第一步——对环境建模。可以找到一个使用强化学习的客户应用程序的视频在这里.当然,这些问题要复杂得多,通常在上述工作流中的每一步都需要更多的时间。
然而,好消息是,原则保持不变,您仍然可以利用我们上面使用的相同技术!
那么现在轮到你了:你有没有考虑应用强化学习的领域?请在评论中告诉我。
- 类别:
- 深度学习








评论
如欲留言,请点击在这里登录您的MathWorks帐户或创建一个新帐户。