 克里夫的角落:克里夫硅藻土在数学和计算
克里夫的角落:克里夫硅藻土在数学和计算 罗兰在MATLAB的艺术
罗兰在MATLAB的艺术 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 文件交换的选择
文件交换的选择 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 创业、加速器,和企业家
创业、加速器,和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー
深Chimpact:深度基准评估野生动物保护——MATLAB代码
在我们的承诺上一篇博文,我们与MATLAB基准代码深Chimpact:深度估计野生动物保护的挑战。
詹姆斯·德拉蒙德,从MathWorks工程开发集团,也尝试着挑战和准备这个起动器代码。他将讨论光学流+ CNN的方式他用于解决这个问题。他还将把一些提示和技巧之间如何改善这段代码和提高你的分数。
检查下面的链接注册挑战,收到你免费MATLAB许可证和访问论坛的支持。金宝app

的数据
这一挑战的目标是估计距离动物单眼相机镜头。视频是在颜色和灰度的夜视和包含一系列不同的动物主题。
数据集包含超过3500个视频(近200 gb的数据)分成一组训练和测试。这些都是托管在公共S3 bucket。指令来访问这可以发现竞争Data选项卡。
每个视频都是给予一个唯一的4个字母的名称和mp4或.avi格式。(“提供的标签train_labels.csv“&”test_labels.csv”)的距离重心在每个视频动物在特定时间戳。帮助促进更快的数据处理down-sampled每个文件的版本。
另外,你提供的“train_metadata.csv”和“test_metadata.csv”文件。这些文件包含信息,如文件名、相机位于细节,model-generated估计边界框的动物在每个时间戳。
详情查看的数据集问题描述在网页上的竞争。
开始使用MATLAB
我提供一个基本的示例代码在MATLAB作为发展的起点。在这段代码中,我使用光流将视频帧和饲料这些图像预处理到一个基本的回归模型,使用pre-trained CNN。然后,我将使用这个模型来进行深度估计测试数据并保存一个CSV文件的格式所需的挑战。你也可以下载这个MATLAB起动器代码这GitHub回购。这可以作为基本的代码,你可以开始分析数据并努力开发更高效,优化,和准确的模型。另外,我提供了一些技巧和建议下一步进行调查。
所以,让我们开始使用这一挑战!
加载标签和元数据
第一步是加载您将使用的数据集的信息。访问文件的变量值train_metadata.csv和train_labels.csv,我将它们导入MATLAB使用再保险adtable功能:
标签= readtable (“train_labels.csv”);(标签)

元数据= readtable (“train_metadata.csv”);(元数据)
 访问和处理视频文件
访问和处理视频文件
 访问和处理视频文件
访问和处理视频文件MATLAB数据存储在一个方便的工作方式和代表太大的数据集合的一次装入内存。它是一个对象用于读取一个文件或一组文件或数据。数据存储作为存储库相同的结构和格式的数据。了解更多关于不同的数据存储,看看下面的文件:
在这个博客中,我将使用一个imageDatastore加载视频从S3 bucket。每个视频处理使用readVideo helper函数下面一节中列出。我保存的数据存储在一个MAT-file tempdir或当前文件夹之前下一个部分。如果垫文件已经存在,然后从MAT-file加载数据存储没有重新评估他们。
在这里,我使用了采样视频节省带宽和处理时间。每个视频都减少到一个单帧每秒满足我的需求。访问完整的视频,您将需要在S3 bucket替换文件的URL。
tempimds = fullfile (tempdir imds.mat);如果存在(tempimds,“文件”)负载(tempimds, imd)其他imd = imageDatastore (s3: / / drivendata-competition-depth-estimation-public / train_videos_downsampled /”,…“ReadFcn”, @(文件名)readVideo(文件名、元数据“TrainingData”),…FileExtensions, {‘mp4’,‘.avi});保存(tempimds, imd);= imds.Files结束文件;
提示(可选):为了减少处理时间,你可以选择使用子集imageDatastore的初步调查:
rng (0);%种子的随机数字生成器可重复性idx = randperm(元素个数(文件);imd = imds.subset (idx (1:10 0));%随机子集进行测试
提取视频帧&光流
一旦我有imageDatastore,我提取视频帧通过定义一个自定义函数读取readVideo(最后这个文件的代码),它首先加载所需的视频使用VideoReader对象。随着downsampled视频一帧每秒,视频可以被索引提取必要的框架。
光流
光流速度的分布明显的对象在一个图像。通过估算光学视频帧之间流动,可以测量物体的速度的视频。
对于每一个标记的框架,我计算光流相比前一帧/秒。如果我们假设这些动物移动主要是静止的背景,光流强调,他们并提供一些背景运动。提高信噪比,所提供的边界框估计是用于生成一个二进制的面具感兴趣的地区。这是用来代替简单的裁剪图像保留任何空间上下文。
技术的更多信息可以在以下链接:
帮助处理以后,每个图像与视频命名它来自和时间戳。下面是一个示例输出为0的视频帧aany.mp4:

这清楚地显示了猴子的位置和大小相对于其它图像,但面具避免背景噪音。
为了生成完整的数据集,我读了所有的视频使用以下命令。在这里,我使用并行计算工具箱来加快处理每一个视频都可以独立阅读。
洛桑国际管理发展学院。再保险adall("UseParallel", true);
设计神经网络
在这个例子中,我将使用pre-trained执行转移学习网络,ResNet-18。然而,在实际学习进展之前,网络需要适应我们的需求相匹配。特别是,输入和输出层需要被取代。ResNet-18需要224 x224x3输入图像和输出图像分类与1000类别。然而,我将输入图像和输出一个480×640退化距离估计。
在MATLAB这些变化可以以两种方式实现,编程方式或图形使用深层网络设计师应用。
这两种方法从安装开始深度学习工具箱ResNet-18网络模型从扩展浏览器。

方法1:使用深层网络设计师
这个应用程序可以在应用丝带或通过运行命令:
deepNetworkDesigner
从启动页面,导入pre-trained ResNet-18网络:
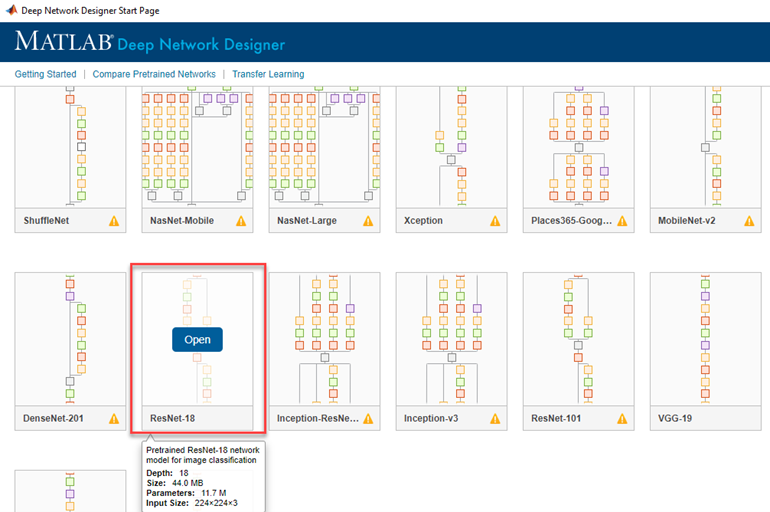
在输入端,我替换224 x224x3imageInputLayer用自己的480×640 imageInputLayer。为了连接到其他的网络,图像将需要调整大小以3 d使用resize3dLayer与OutputSize 480 x640x3层。

下一个在输出端,我走过去几层,换上了我自己。特别是,我取代fullyConnectedLayer softmaxLayer和classificationLayer决赛fullyConnectedLayer只给一个输出值——距离估计——这将融入到一个输出regressionLayer。

这个网络做了这些变更之后,您可以导出您的工作空间中使用的训练。网络是导出为LayerGraph称为“lgraph_1”。
方法2:通过编程方式创建网络
另外,您可以通过编程方式应用这些更改。后安装ResNet-18插件,您可以导入培训网络。
lgraph_1 = layerGraph (resnet18);
在输入端,我替换224 x224x3imageInputLayer命名为“数据”——用自己的480×640 imageInputLayer。为了连接到其他的网络,我缩放图像3 d使用resize3dLayer与OutputSize 480 x640x3层。
inputLayers = [imageInputLayer([480 - 640],“名字”,“imageinput”),…resize3dLayer (OutputSize, 480 640 3, '名称',' resize3D-output-size '))

lgraph_1 = replaceLayer (lgraph_1‘数据’,inputLayers);
下一个在输出端,我走过去几层,换上了我自己。特别是,fullyConnectedLayer fc1000, softmaxLayer“概率”和classificationLayer ClassificationLayer_predictions最后的fullyConnectedLayer只给一个输出值——距离估计——这将融入到一个输出regressionLayer。
lgraph_1 = removeLayers (lgraph_1 {‘fc1000’,‘问题’,‘ClassificationLayer_predictions}) outputLayers = [fullyConnectedLayer(1,“名字”,“俱乐部”),regressionLayer(“名字”,“regressionoutput”)]

现在我添加输出层的层图。然后我把“pool5”和“俱乐部”层图。
lgraph_1 = addLayers (lgraph_1 outputLayers);lgraph_1 = connectLayers (lgraph_1 pool5, fc);
更多信息层图形和上面的对象使用的功能,可以在这里找到:layerGraph
分析网络
然后,您可以运行网络分析仪确认我们的新层符合正确。结果应该显示一个480×640输入新480 x640x3,贯穿pre-trained网络然后输出作为一个单一的回归值。
analyzeNetwork (lgraph_1)


准备训练数据
现在,我已经完成了我们的预处理和设计网络,下一步是准备训练的数据。
首先,我创建的数据集。这包括一个CombinedDatastore,由一个imageDatastore输入图像和一个arrayDatastore他们的标签。的generateLabelDS helper函数是必要的,以确保正确的图片和标签匹配。从combinedDatastore阅读。”fullDataset”,返回图像和相应的标签。
成像= imageDatastore (“TrainingData”);labelDS = generateLabelDS(成像、标签);fullDataset =结合(成像,labelDS);
在这里,我准备培训的数据分区的数据为训练和验证的分区。我将80%的数据分配给培训验证分区分区和20%。
n_images =元素个数(imageDS.Files);n_training =圆(0.8 * n_images);idx = randperm (n_images);trainingIdx = idx (1: n_training);validationIdx = idx (n_training + 1:结束);trainingDS =子集(fullDataset trainingIdx);validationDS =子集(fullDataset validationIdx);
指定培训选项
下一步,使用指定的培训选项trainingOptions功能:
- 设置一个mini-batch大小8。
- 设置一个初始学习速率为0.01。
- 混乱的数据每一时代。
- 验证每个时代网络一次。
- 显示在一块训练进展和抑制详细输出。
miniBatchSize = 8;validationFrequency =地板(n_training / miniBatchSize);选择= trainingOptions(“个”,…MiniBatchSize, MiniBatchSize,……“MaxEpochs”, 50岁,…“InitialLearnRate”, 0.01,…“洗牌”、“every-epoch’,……ValidationData, validationDS,……ValidationFrequency, ValidationFrequency,……“阴谋”、“训练进步”,… 'Verbose',true, ... 'ExecutionEnvironment',"auto");
培训网络
我现在火车网络使用trainNetwork函数,并将输出保存到文件。注意,这个函数可以花很长时间运行,depnding类型的计算(GPU、CPU)。
(网络,信息)= trainNetwork (trainingDS、lgraph_1选项);保存(trainedNetwork.mat,净)

使用一个泰坦Xp GPU,培训的完整数据集50时代花了近5个小时。然而,这种训练可以结束之前考虑到下半年业绩停滞不前。同样,初步调查是进行数据的一个子集,因此训练得更快。
准备测试数据
正如我的训练数据,我将阅读测试文件imageDatastore和提取光流的必要的框架。
test_metadata = readtable (“test_metadata.csv”);imd = imageDatastore (s3: / / drivendata-competition-depth-estimation-public / test_videos_downsampled /”,…“ReadFcn”, @(文件名)readVideo(文件名、test_metadata TestData),…FileExtensions, {‘mp4’,‘.avi});imds.readall (“UseParallel”,真正的);
使用测试数据深度估计
使用上面的训练网络,我现在在测试集上执行预测。为此,我使用了预测训练网络的方法。预测方法接受一个480×640的图像并返回深度估计。通过循环测试集我生成一个表中的所有图片的结果。这里,我创建一个11933(测试帧的数量)行表列:video_id,时间和距离。
= %预置输出表结果表(“大小”,高度(test_metadata) 3, VariableTypes,{“字符串”,“弦”,“单一”},…VariableNames, {‘video_id’,‘时间’,‘距离’});i = 1:高度(test_metadata) id = test_metadata.video_id {};t = test_metadata.time(我);文件名= [id (1:4) num2str (t)“中将”);%找到对应的图像名称文件= fullfile (TestData,文件名);如果isfile(文件)%帧没有边框不会输入图像I = imread(文件);预测=预测(净,我,“ExecutionEnvironment”,“汽车”);其他预测= 0; end results.video_id(i) = id; results.time(i) = t; results.distance(i) = prediction; end head(results)

保存提交文件
上面的表产生的结果的匹配所需的格式提交现在你所需要做的是将其保存到一个CSV文件。这是您提交的文件的挑战。
writetable(结果,“Submission.csv”);
辅助函数
视频预处理——光流
这个helper函数提取和预处理标记帧的采样视频。然后保存这些提供的文件夹,/ TrainingData在这个例子中。
这是我们的光流计算必要的框架,然后利用边界框应用二进制面具。
函数输出=readVideo(文件名、元数据文件夹)%加载视频vr = VideoReader(文件名);H = vr.Height;W = vr.Width;[~、名称]= fileparts(文件名);idx =包含(metadata.video_id、名称);videoMetadata = rmmissing(元数据(idx:));%忽略帧没有边界框n_Frames =身高(videoMetadata);% Preallocate输出图像阵列输出= 0(480640年,n_Frames);i = 1: n_Frames opticFlow = opticalFlowLK (NoiseThreshold, 0.009);%定义光学流t = videoMetadata.time(我); %Extract timestamp try if t == 0 %If first frame compare with second f1 = vr.read(1); f2 = vr.read(2); else %Otherwise take current frame (t+1) and previous (t) f1 = vr.read(t); f2 = vr.read(t+1); end catch continue %Ignore videos where timings do not match with frames end %Convert to grayscale f1Gray = im2gray(f1); f2Gray = im2gray(f2); %Calculate optical flow estimateFlow(opticFlow,f1Gray); flow = estimateFlow(opticFlow,f2Gray); %Extract corners of bounding box x1 = videoMetadata.x1(i); x2 = videoMetadata.x2(i); y1 = videoMetadata.y1(i); y2 = videoMetadata.y2(i); %Apply mask for bounding box mask = poly2mask([x1 x2 x2 x1]*W,[y1 y1 y2 y2]*H,H,W); maskedFlow = bsxfun(@times, flow.Magnitude, cast(mask, 'like', flow.Magnitude)); maskedFlow = imresize(maskedFlow,'OutputSize',[480 640]); file = fullfile(folder, [name num2str(t) '.png']); %Generate file name %Save image to file if isfolder(folder) imwrite(maskedFlow,file) else mkdir(folder) imwrite(maskedFlow,file) end output(:,:,i) = maskedFlow; end end
为响应创建arrayDatastore
这个函数接受一个数据存储图片和表格的标签。然后构建一个arrayDatastore标签确保对应的图像文件。
函数labelDS= generateLabelDS (imd、标签)文件= imds.Files;n_files =长度(文件);dataLabels = 0 (n_files, 1);i = 1: n_files [~, id] = fileparts(文件{我});视频= id (1:4);时间= str2double (id(5:结束);idx =(包含(labels.video_id、视频))&(标签。时间= =);dataLabels (i) = labels.distance (idx);结束labelDS = arrayDatastore (dataLabels);结束
下一步需要改进
在这个例子中有许多我调查的设计选择,可用于提高分数:
光流
- 算法——MATLAB提供4计算的技术光流。我选择Lucas-Kanade方法基于视觉外观。
- 参数——噪声阈值信号和背景噪声之间的权衡。
- 感兴趣的区域——我选择了应用二元掩模强调该地区感兴趣的,但可能会有一个更好的方法。此外,在这个例子中我忽略了帧边界框。相反,你可以尝试包括整个图像光流。
训练数据分区
- 比例- - - - - -改变你的训练和验证的比例数据可以帮助控制性能和过度拟合。
- 方法——在这个例子中,随机图像分割。然而,你也可以分割基于视频或相机的网站。请注意,测试数据正在从不同的网站比训练集。
转移学习
- 转移学习——这里,我从一个pretrained开始神经网络和执行额外的训练数据——这一过程被称为基于竞争转移学习。我们允许所有层pretrained模型的改变在培训过程中(所有的重量都解冻)。然而,这意味着我们可能失去了一些模型的现有的知识。相反,转移学习的第一步通常是火车只有最后一层pretrained模型的新数据,将所有层早些时候不变。一旦新层是训练有素的,早些时候层可以更好地从模型的pretraining调整而不失去洞察力。这也可以早些时候由冻结权重的初始层。
- 冻结的重量——通过设置学习的初始层率为0,我们可以防止权重更新后续学习。可以找到更多的信息在这里。
- Pre-trained网络——MATLAB提供了大量的选项pretrained网络对你进行调查。
- 培训方案——调整参数训练可以有一个显著的最终结果。例如:学习速率、迷你批量大小、动量,梯度阈值,损失函数
这段代码可以下载这GitHub回购。我们提供这段代码作为起点,很兴奋地看到你能想出什么创新。好运!
- 类别:
- 数据科学






评论
留下你的评论,请点击在这里MathWorks账户登录或创建一个新的。