{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
本文介绍了可以用于加速MATLAB的技术®算法和应用程序。主题包括:
评估代码性能
采用高效的串行编程实践
使用系统对象
在多核处理器和GPU上执行并行计算
生成C代码
每一节重点介绍一种特定的技术,描述底层的加速技术,并解释何时最适用。您的编程专业知识、希望加速的算法类型以及可用的硬件可以帮助指导您选择技术1.
评估代码的性能
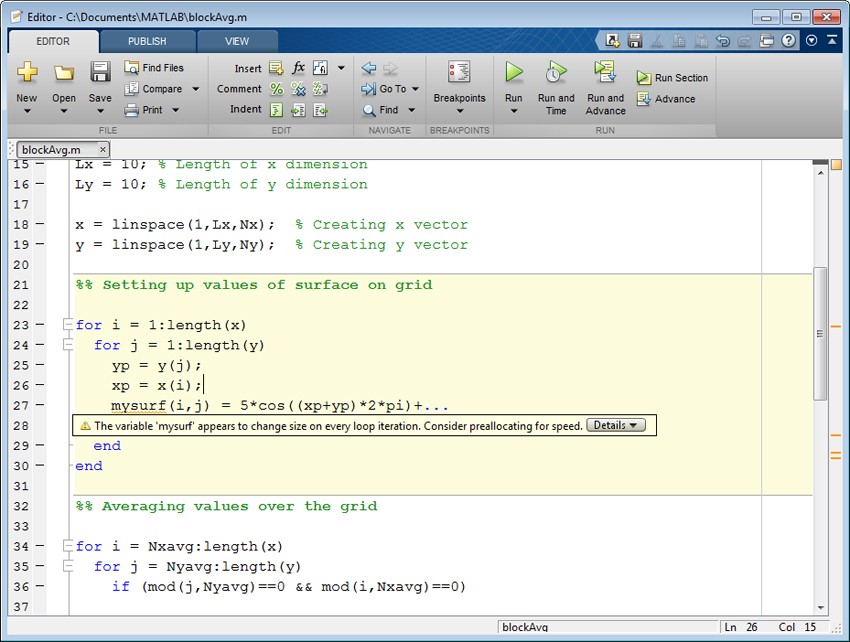
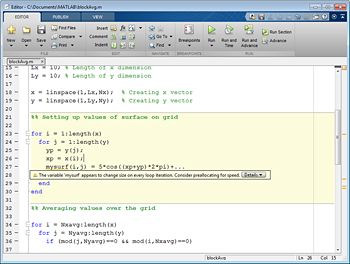
在修改代码之前,您需要确定您的工作重点。支持这一过程的两个关键工具是代码分析器和MA金宝appTLAB分析器。在编写代码时,MATLAB编辑器中的代码分析器会检查代码。代码分析器识别潜在的问题,并建议进行修改,以最大限度地提高性能和可维护性(图1)。代码分析器报告可以在整个文件夹上运行,使您能够在单个文档中查看针对一组文件的所有代码分析器建议。
Profiler显示您的代码在哪里度过它的时间。它提供了一份报告总结了代码的执行,包括调用所有函数的列表,调用每个函数的次数,以及每个函数内所花费的总时间(图2)。Profiler还提供有关每个功能的时序信息,例如哪条代码使用最多的处理时间。
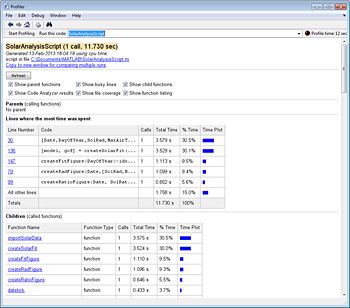
一旦确定了瓶颈,您可以专注于改善这些特定代码部分性能的方法。当您实施优化和技术来加速算法时,Profiler可以帮助您衡量改进。
采用高效的串行编程实践
在考虑并行计算、代码生成或其他方法之前,优化串行代码的性能通常是一个很好的实践。有两种有效的编程技术可以加速你的MATLAB代码预先分配和矢量化.
使用preLocation,使用该数组所需的最终大小初始化数组。prelocation帮助您避免动态调整阵列,特别是当代码包含时为了和尽管循环。由于MATLAB中的数组保存在连续的内存块中,重复调整数组大小通常需要MATLAB花费时间寻找更大的连续内存块,然后将数组移动到这些块中。通过预分配数组,可以避免这些不必要的内存操作,并提高总体执行时间。
矢量化是将代码转换为使用矩阵和矢量操作的代码。MATLAB使用处理器优化的库进行矩阵和矢量计算。因此,您通常可以通过将代码传染措施来提高性能。
使用更大阵列的矢量化MATLAB计算可能是使用GPU加速的好选择。在这种情况下,为了-loops不能被向量化,通常可以使用parallel为了-环形 (parfor)或C代码生成,以加速算法。有关这些技术的更多详细信息,请参阅并行计算和生成C代码的部分。
您可以使用系统对象™在很大程度上在信号处理和通信领域加速MATLAB代码。系统对象是MATLAB面向对象的算法实现系统工具箱,包括通信系统工具箱™和DSP系统工具箱™.通过使用System对象,可以将声明(System对象创建)与在System对象中找到的算法的执行解耦。这种解耦可以产生更有效的基于循环的计算,因为它只允许执行一次参数处理和初始化。您可以在循环外部创建和配置System对象的实例,然后在循环内部调用step方法来执行它。
DSP系统工具箱和通信系统工具箱中的大多数系统对象都以MATLAB可执行文件实现(mex files)。此实现可以加速模拟,因为许多算法优化包含在对象的MEX实现中。有关MATLAB生成C代码的部分,有关MEX文件的更多详细信息。
学习更多关于使用System对象进行流处理,创建自己的系统对象, 和模拟信号处理算法在MATLAB中使用System对象。
执行并行计算
到目前为止所描述的技术侧重于优化串行MATLAB代码的方法。您还可以通过使用额外的计算能力来获得性能改进。MATLAB并行计算产品提供计算技术,让您利用多核处下载188bet金宝搏理器,计算机集群和GPU。
使用Matlab Workers在多核处理器和集群上
并行计算工具箱™允许您在台式电机上运行多个MATLAB工人(MATLAB计算引擎)。您可以通过划分这些工人的计算来加速您的应用程序。这种方法使您可以更好地控制并行性,而不是在MATLAB中找到的内置多线程。它通常用于较粗糙的粒度问题,例如参数扫描和蒙特卡罗模拟。有关更高的加速,可以使用MATLAB并行服务器将使用MATLAB工作者的并行应用程序缩放到计算机群集或云™.
几个工具箱,包括优化工具箱™和统计和机器学习工具箱™,提供可以利用多工作方行的算法来加速您的计算2.在大多数情况下,您可以通过简单地打开一个选项来使用并行算法。例如,要运行fmincon并行优化工具箱中,您将“始终”的“使用指定”选项设置为“始终”。
并行计算工具箱提供高级编程构造,例如parfor.使用parfor你可以加速为了- 通过划分循环迭代来在多个MATLAB工人划分的循环迭代中划分MATLAB代码(图3)。
使用parfor,循环迭代必须是独立的,没有迭代依赖于任何其他迭代。为了加速依赖或基于状态的循环,您可以重新排序计算,以使循环变为顺序无关。或者,您可以将包含的外循环并行化为了-环形。如果这些选项不可行,可以优化身体为了-loop或考虑生成C代码。
通过在客户端和Matlab工人之间传输数据parfor循环,您会产生沟通成本。这意味着使用可能没有有利parfor当你只有少量的简单计算时。如果是这种情况,请将重点放在并行化外部为了-loop包含更简单的为了-环形。
的批命令可用于在Matlab Workers跨Matlab工人分发独立计算,以便脱机处理作为批处理作业。当这些计算需要很长时间运行时,这种方法特别有用,并且您需要释放您的桌面MATLAB以进行其他工作。
使用GPU.
图形处理单元(graphics progressive unit, gpu)最初用于加速图形渲染,也可应用于信号处理、计算金融、能源生产等领域的科学计算。
您可以直接从MATLAB执行NVIDIA GPU上的计算。FFT,IFFT和线性代数操作是100多个内置MATLAB函数,可以直接在GPU上执行。这些重载的功能在GPU或CPU上运行,具体取决于传递给它们的参数的数据类型。当给定GPUARRAY的输入参数(并行计算工具箱提供的特殊数组类型)时,这些功能将自动在GPU上运行(图4)。几个工具箱,包括通信系统工具箱和信号处理工具箱™,还提供GPU加速算法。
两个经验法则将确保您的计算密集型问题是一个很好的适合GPU。首先,当所有的内核都处于忙碌状态时,利用GPU固有的并行特性,你会看到GPU的最佳性能。在更大的数组和支持gpu的工具箱函数上使用向量化MATLAB计算的代码就属于这一类。其次,应用程序在GPU上运行所需的时间应该远远超过应用程序执行期间在CPU和GPU之间传输数据所需的时间。
为了更高级使用GPU,如果您熟悉CUDA编程,您可以直接从MATLAB运行基于CUDA的GPU内核。然后,您可以使用MATLAB中的数据分析和可视化功能,同时更直接控制GPU算法。
了解更多有关使用parfor和批,在Multicore和多处理器机器上运行MATLAB,GPU与Matlab计算, 和工具箱与内置并行和支持GPU的算法.
从MATLAB代码生成C代码
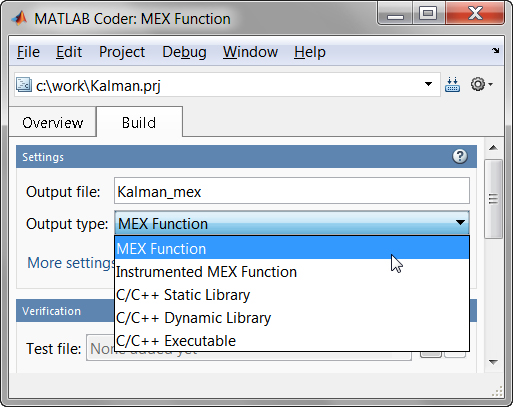
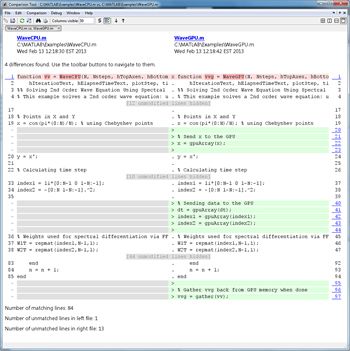
用自动生成的MATLAB可执行文件(MEX-function)替换部分MATLAB代码可以提高速度。使用MATLAB编码器™,您可以生成可读和便携式的C代码并将其编译为替换MATLAB算法的等效部分的MEX函数(图5)。您还可以通过生成MEX函数来利用多核处理器parfor结构体。
所实现的加速量取决于算法的性质。确定加速度的最佳方法是使用MATLAB编码器生成MEX函数并测试加速第一手。如果您的算法包含单精度数据类型,定点数据类型,带有状态的循环,或无法矢量的代码,您可能会看到加速。另一方面,如果您的算法包含MATLAB隐式多线程计算,例如FFT.和圣言会,调用IPP或BLAS库的功能,在PC上的MATLAB上执行的功能,如FFT,或者可以将代码保持一致,加速度不太可能。尝试matlab编码器,遵循最佳实践对于C代码生成,并咨询MATHWORKS技术专家以找到通过这种方法加速您的算法的最佳方法。
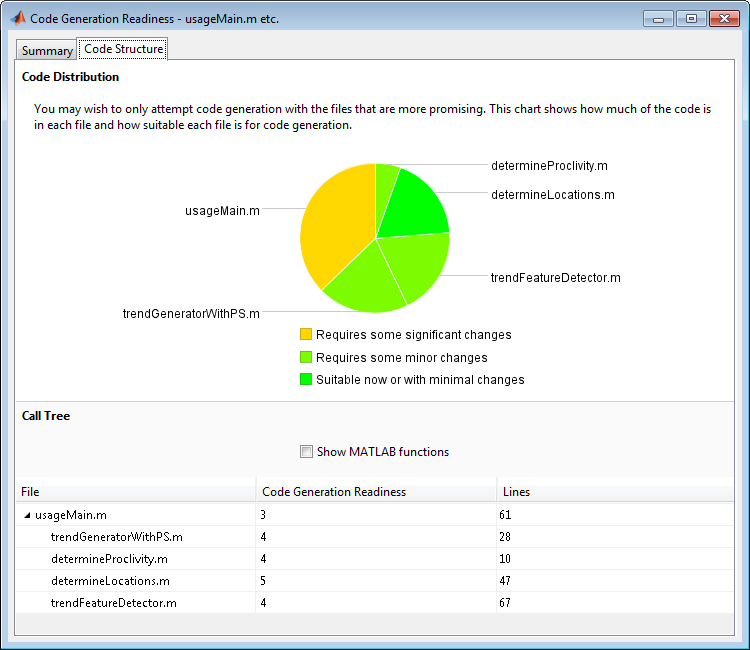
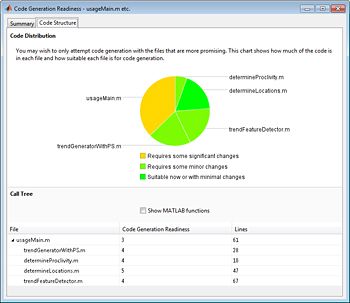
很多MATLAB语言和一些工具箱都支持代码生成。金宝appMATLAB Coder提供了自动工具来帮助您评估算法的代码生成准备情况,并指导您完成c代码生成的步骤(图6)。
学习更多关于从MATLAB到C代码以及如何Matlab编码器快速开始.
可能的性能提升
您可以通过编写高效的算法、并行处理和代码生成来加速MATLAB应用程序。每种方法都有一个可能的加速范围,这取决于问题和您使用的硬件。这里列出的基准和加速度示例给出了可能的加速度的大致概念。
学习更多关于性能获得使用parfor,支持不同类型的GPU功能金宝app,内置GPU支持系统对象金宝app, 和C代码生成.