GPU编码器
为NVIDIA图形处理器生成CUDA代码
GPU Coder™生成优化的CUDA®从MATLAB代码®代码和仿真软件金宝app®模型。生成的代码包括CUDA内核,用于深度学习、嵌入式视觉和信号处理算法的可并行部分。为了获得高性能,生成的代码调用优化的NVIDIA®CUDA库,包括TensorRT™,cuDNN, cuFFT, cuSolver和cuBLAS。这些代码可以作为源代码、静态库或动态库集成到项目中,并且可以为NVIDIA Jetson™、NVIDIA DRIVE™和其他平台上的台式机、服务器和gpu编译。您可以使用MATLAB中生成的CUDA来加速深度学习网络和算法的其他计算密集型部分。GPU编码器允许您将手写CUDA代码合并到您的算法和生成的代码。
当与嵌入式编码器使用®, GPU编码器让您验证的数字行为生成的代码通过软件在环(SIL)和处理器在环(PIL)测试。
开始:


免费白皮书
用MATLAB生成CUDA代码
部署算法免版税
在流行的NVIDIA GPU上编译并运行生成的代码,从桌面系统到数据中心到嵌入式硬件。生成的代码无需在商业应用程序中为您的客户提供免版税部署。

探索画廊(2张图片)
GPU编码器的成功故事
了解各种行业的工程师和科学家如何使用GPU编码器为他们的应用程序生成CUDA代码。

空客原型机在NVIDIA Jetson TX2上自动检测缺陷。
从支持的工具箱和函数生成代码金宝app
GPU编码器从广泛的MATLAB语言功能生成代码,该功能设计设计工程师用于开发算法作为较大系统的组件。这包括来自Matlab和Companion工具箱的数百个运营商和函数。

MATLAB语言和工具箱支持代码生成。金宝app
将遗留代码
使用遗留代码集成功能,将可信或高度优化的CUDA代码合并到MATLAB算法中,以便在MATLAB中进行测试。然后从生成的代码中调用相同的CUDA代码。

将现有的CUDA代码合并到生成的代码中。
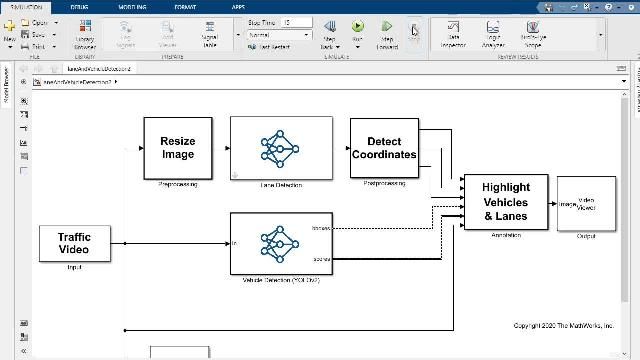
运行模拟和生成优化的NVIDIA图形处理器代码
与Simulink Coder金宝app™一起使用时,GPU编码器在NVIDIA GPU上的Simulink模型中加速了MATLAB功能块的计算密集部分。然后,您可以从Simulink模型生成优化的CUDA代码,并将其部署到您的NVIDIA GPU目标。金宝app

金宝app在GPU上运行的Sobel边缘检测器的Simulink模型。
部署端到端深度学习算法
在Simulink模型中使用深度学习工具箱™中的各种经过训练的深度学习网络(包括ResNet-50、SegNet和LSTM),并将其部署到NVIDIA gpu上。金宝app生成用于预处理和后处理的代码,以及经过训练的深度学习网络,以部署完整的算法。
日志信号,调谐参数和数字验证代码行为
当与Simulink Code金宝appr一起使用时,GPU Coder使您能够使用外部模式模拟实时记录信号和调整参数。使用嵌入式编码器与GPU编码器运行软件在环和处理器在环测试,以数字验证生成的代码符合模拟的行为。

使用外部模式在Simulink中记录信号和调谐参数。金宝app
部署端到端深度学习算法
将各种培训的深度学习网络(包括Reset-50,SEGNET和LSTM)从深度学习工具箱到NVIDIA GPU。使用预定义的深度学习层或定义特定应用程序的自定义图层。生成用于预处理和后处理的代码,以及经过训练的深度学习网络,以部署完整的算法。
为推理生成优化代码
GPU编码器与其他深度学习解决方案相比,GPU编码器产生具有较小占用的代码,因为它只生成使用特定算法运行推断所需的代码。金宝搏官方网站生成的代码调用优化的库,包括TensorRT和CUDNN。

在Titan V GPU上使用cuDNN的VGG-16单图像推理。
使用张力进一步优化
生成与NVIDIA TensorRT(高性能深度学习推理优化器和运行时)集成的代码。使用INT8或FP16数据类型可以在标准FP32数据类型之上获得额外的性能提升。

使用TensorRT和INT8数据类型提高执行速度。
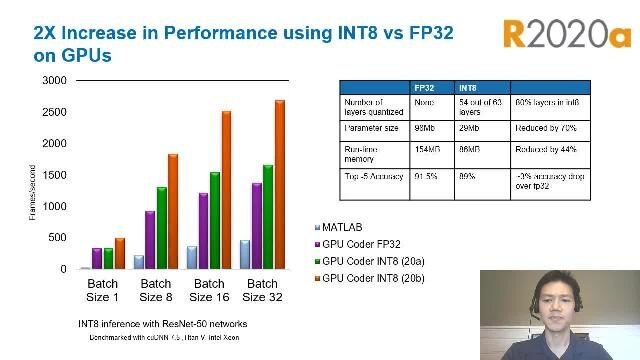
深度学习量化
量化您的深度学习网络以降低内存使用率并提高推理性能。使用Deep Network Standizer应用程序分析和可视化性能和推理准确性之间的折衷。
最小化CPU-GPU存储器传输并优化内存使用情况
GPU编码器自动分析,识别和划分MATLAB代码段运行在CPU或GPU上。它还最小化了CPU和GPU之间的数据副本数量。使用分析工具来识别其他潜在的瓶颈。

概要报告识别潜在的瓶颈。
调用优化的库
使用GPU Coder生成的代码调用优化的NVIDIA CUDA库,包括TensorRT, cuDNN, cuSolver, cuFFT, cuBLAS和Thrust。从MATLAB工具箱函数生成的代码尽可能地映射到优化的库。

在优化cuFFT CUDA库中生成代码调用函数。

原型在NVIDIA Jetson和DRIVE平台上
使用NVIDIA GPU的GPU编码器支持包,自动交叉编译和部署生成的代码到NVIDIA Jetson和DRIVE平台上。金宝app

在NVIDIA Jetson平台上进行原型设计。
访问外设和传感器从MATLAB和生成的代码
远程与Matlab的NVIDIA目标通信,从网络摄像头和其他支持的外围设备获取早期原型的数据。金宝app将算法与外设接口代码一起部署到主板以进行独立执行。

从MATLAB和生成的代码访问外设和传感器。
从原型化到生产
使用GPU编码器与嵌入式编码器交互跟踪您的MATLAB代码与生成的CUDA代码并排。使用软件在环(SIL)和处理器在环(PIL)测试,验证所生成代码在硬件上运行的数值行为。

使用GPU编码器具有嵌入式编码器的交互式可追溯性报告。
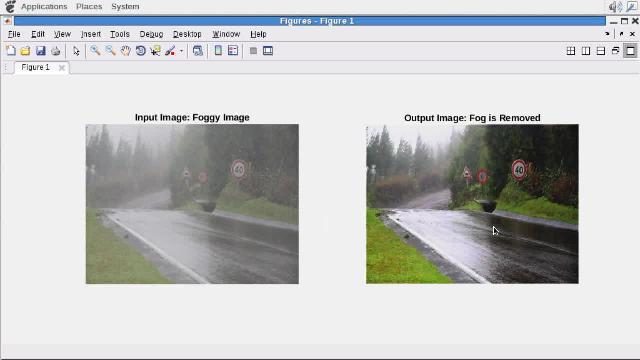
在MATLAB中使用gpu加速算法
从您的MATLAB代码中调用生成的CUDA代码作为一个MEX函数来加速执行,尽管性能将根据您的MATLAB代码的性质而有所不同。概要文件生成的MEX函数来识别瓶颈并集中您的优化工作。
使用NVIDIA GP金宝appU加速Simulink模拟
与Simulink编码器一起使金宝app用时,GPU编码器在NVIDIA GPU上的Simulink模型中加速了MATLAB功能块的计算密集部分。
