模拟
蒙特卡洛仿真条件方差模型
描述
例子
模拟GARCH模型条件差异和响应
模拟来自GARCH(1,1)模型的条件方差和响应路径。
使用已知参数指定GARCH(1,1)模型。
mdl = garch('持续的',0.01,'GARCH',0.7,'拱',0.2);
模拟500个样品路径,每个样品路径为100个观察结果。
RNG.默认;重复性的%[v,y] =模拟(MDL,100,'numpaths',500);图形子图(2,1,1)绘制(v)标题('模拟条件差异')子图(2,1,2)绘图(Y)标题('模拟响应')
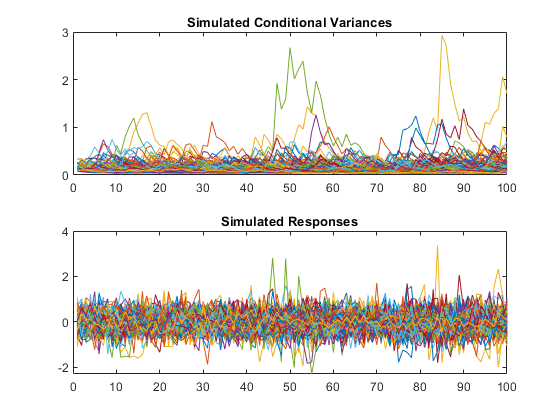
模拟响应看起来像静止随机过程中的绘制。
绘制模拟条件方差的2.5,50(中位数)和97.5百分位数。
较低=分子(V,2.5,2);中间=中位数(v,2);upper = proctile(v,97.5,2);图绘图(1:100,较低,'r:',1:100,中间,'K'那......1:100,上部,'r:'那'行宽',2)传奇('95%的间隔'那'中位') 标题('近似95%的间隔')

由于对条件方差的积极约束,间隔是不对称的。
模拟eGARCH模型条件差异和响应
模拟来自Egarch(1,1)模型的条件方差和响应路径。
使用已知参数指定EGARCH(1,1)模型。
mdl = egarch('持续的',0.001,'GARCH',0.7,'拱',0.2,......'杠杆作用',-0.3);
模拟500个样品路径,每个样品路径为100个观察结果。
RNG.默认;重复性的%[v,y] =模拟(MDL,100,'numpaths',500);图形子图(2,1,1)绘制(v)标题('模拟条件差异')子图(2,1,2)绘图(Y)标题('模拟响应(创新)')
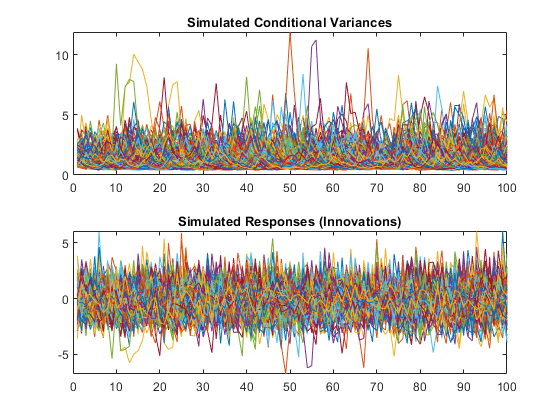
模拟响应看起来像静止随机过程中的绘制。
绘制模拟条件方差的2.5,50(中位数)和97.5百分位数。
较低=分子(V,2.5,2);中间=中位数(v,2);upper = proctile(v,97.5,2);图绘图(1:100,较低,'r:',1:100,中间,'K'那......1:100,上部,'r:'那'行宽',2)传奇('95%的间隔'那'中位') 标题('近似95%的间隔')
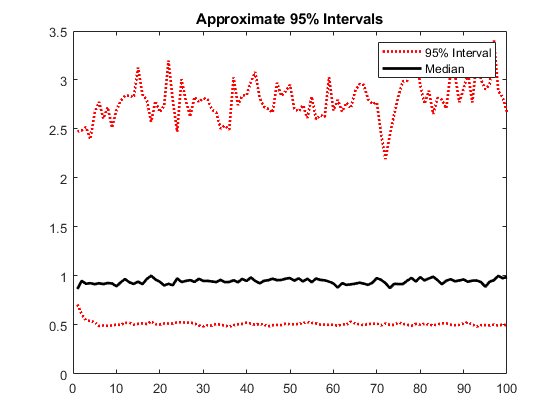
由于对条件方差的积极约束,间隔是不对称的。
模拟GJR模型条件差异和响应
模拟来自GJR(1,1)模型的条件方差和响应路径。
使用已知参数指定GJR(1,1)模型。
mdl = gjr('持续的',0.001,'GARCH',0.7,'拱',0.2,......'杠杆作用',0.1);
模拟500个样品路径,每个样品路径为100个观察结果。
RNG.默认;重复性的%[v,y] =模拟(MDL,100,'numpaths',500);图形子图(2,1,1)绘制(v)标题('模拟条件差异')子图(2,1,2)绘图(Y)标题('模拟响应(创新)')

模拟响应看起来像静止随机过程中的绘制。
绘制模拟条件方差的2.5,50(中位数)和97.5百分位数。
较低=分子(V,2.5,2);中间=中位数(v,2);upper = proctile(v,97.5,2);图绘图(1:100,较低,'r:',1:100,中间,'K'那......1:100,上部,'r:'那'行宽',2)传奇('95%的间隔'那'中位') 标题('近似95%的间隔')

由于对条件方差的积极约束,间隔是不对称的。
Monte-Carlo仿真预测有条件差异
模拟每日纳斯达克综合指数的条件差异返回500天。使用模拟进行预测,并近似95%的预测间隔。比较GARCH(1,1),EGARCH(1,1)和GJR(1,1)的预测。
加载工具箱中包含的NASDAQ数据。将索引转换为返回。
加载data_equityidx.纳斯达克= DataTable.nasdaq;r = price2ret(纳斯达克);t =长度(r);
适合GARCH(1,1),EGARCH(1,1)和GJR(1,1)模型到整个数据集。推断有条件的差异用作预测模拟的预先条件差异。
mdl = cell(3,1);%preallocation.MDL {1} = GARCH(1,1);mdl {2} = egarch(1,1);MDL {3} = GJR(1,1);estmdl = cellfun(@(x)estmate(x,r,'展示'那'离开'),MDL,......'统一输出',错误的);v0 = Cellfun(@(x)推断(x,r),estmdl,'统一输出',错误的);
estmdl.是3×1细胞矢量。每个单元是一种不同类型的估计条件方差模型,例如,estmdl {1}是估计的GARCH(1,1)模型。v0.是一个3×1个细胞矢量,每个细胞包含来自相应的估计模型的推断条件差异。
模拟1000个样本路径,每个样本都有500个观察结果。使用观察到的返回并将条件差异推断为预先数据。
VSIM = CELL(3,1);%preallocation.为了J = 1:3 RNG默认;重复性的%vsim {j} =模拟(estmdl {j},500,'numpaths',1000,'e0',r,'v0',v0 {j});结尾
VSIM是一个3×1个细胞矢量,每个单元包含从相应的估计模型产生的500×1000矩阵的模拟条件差异。
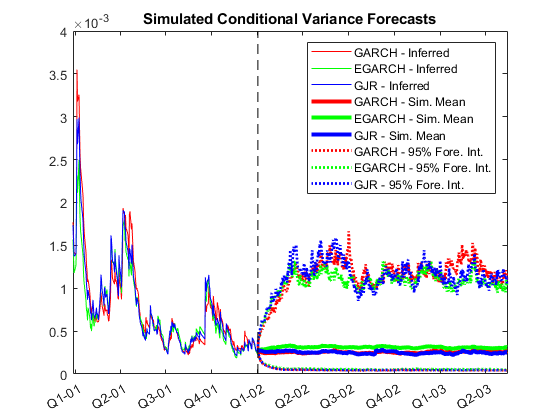
绘制模拟平均预测和近似95%的预测间隔,以及从数据推断的条件方差。
较低= Cellfun(@(x)分色(x,2.5,2),VSIM,'统一输出',错误的);Upper = Cellfun(@(x)prctile(x,97.5,2),VSIM,'统一输出',错误的);Mn = Cellfun(@(x)均值(x,2),vsim,'统一输出',错误的);Datesplot =日期(结束 - 250:结束);datesfh =日期(结束)+(1:500)';h =零(3,4);数字为了j = 1:3 col =零(1,3);Col(j)= 1;h(j,1)= plot(datesplot,v0 {j}(ex-250:结束),'颜色',col);抓住在h(j,2)= plot(datesfh,mn {j},'颜色',col,'行宽',3);h(j,3:4)= plot([datesfh datesfh],[下{j} upper {j}],':'那......'颜色',col,'行宽',2);结尾HGCA = GCA;绘图(DatesFH(1)* [1 1],HGCA.YLIM,'k-');dateTick;轴紧的;H = H(:,1:3);传奇(H(:),'GARCH - 推断'那'egarch-推断'那'GJR - 推断'那......'garch - sim。意思'那'egarch - sim。意思'那'gjr - sim。意思'那......'GARCH - 95%。int。'那'egarch - 95%。int。'那......'GJR - 95%。int。'那'地点'那'东北') 标题('模拟条件方差预测') 抓住离开
输入参数
输出参数
参考文献
[1] Bollerslev,T。“广义归类疾病性瘢痕糕点”。中国经济学杂志。卷。31,1986,第307-327页。
[2] Bollerslev,T。“一个有条件的异源性时间序列模型,用于投机价格和回报率。”经济学与统计审查。卷。69,1987,第542-547页。
[3]盒子,G.E.P.,G.M. Jenkins和G. C. Reinsel。时间序列分析:预测和控制。3 ed。Englewood Cliffs,NJ:Prentice Hall,1994年。
[4]内酯,W。应用计量计量时间序列。霍博肯,NJ:John Wiley&Sons,1995。
[5] Engle,R. F.“归类化条件异性瘢痕贴膜,估计联合王国通胀差异。”Moveryetrica.。卷。50,1982,pp。987-1007。
[6] Grosten,L. R.,R.Jagannathan和D. E. Runkle。“关于预期价值与标称超额股票的波动性关系。”财务杂志。卷。48,第5,1993,第5,199,PP。1779-1801。
[7]汉密尔顿,J.D。时间序列分析。普林斯顿,新泽:普林斯顿大学出版社,1994年。
[8]纳尔逊,D.B。“资产中的条件异质娱乐性回报:一种新方法。”Moveryetrica.。卷。59,1991,第347-370页。
也可以看看
对象
职能
您还可以从以下列表中选择一个网站:
