使用音高和MFCC的扬声器识别
此示例演示了一种基于从录制的语音中提取的功能来识别人员的机器学习方法。用于训练分类器的特征是语音和MEL频率谱系数(MFCC)的浊音段的间距。这是一个封闭式扬声器标识:将被测扬声器的音频与所有可用的扬声器型号(有限组)进行比较,并返回最接近的匹配。
介绍
该示例用于扬声器识别示例中使用的方法在图中示出。
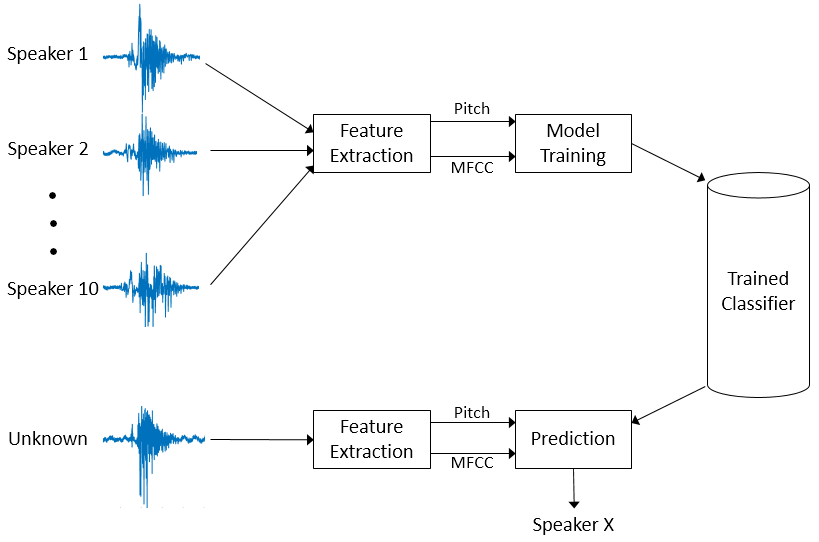
音高和MFCC是从10个扬声器记录的语音信号中提取的。这些特征被用来训练k -最近邻(KNN)分类器。然后,对新的需要分类的语音信号进行相同的特征提取。经过训练的KNN分类器预测10个扬声器中哪一个最接近匹配。
用于分类的特征
本节讨论音高和MFCC,这两个特性是用来对扬声器进行分类的。
球场
语音可以大致分类为浊音和无声的.在浊音语音的情况下,来自肺的空气被声带调节,并导致准周期性激发。得到的声音由相对低频振荡的主导地位,称为球场.在语音不清的情况下,来自肺部的空气通过声道的收缩,成为紊流,噪声样的兴奋。在语音的源-滤波模型中,激励称为源,声道称为滤波器。语音源的特征提取是语音系统特征提取的重要组成部分。
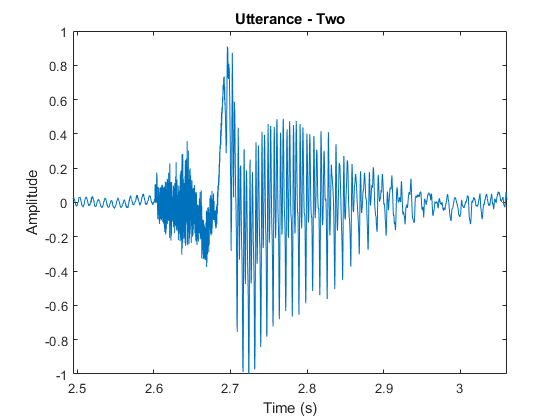
作为浊音和清晰的语音的示例,考虑“两个”单词(/ t uw /)的时域表示。辅音/ T /(无声语音)看起来像噪音,而元音/ UW /(浊音)的特点是强大的基础频率。
[audioIn, fs] = audioread('Counting-16-44p1-mono-15secs.wav');twostart = 110e3;twostop = 135e3;AudioIn = AudioIn(TwoStart:TwoStop);timevector = linspace((twostart / fs),(twostop / fs),numel(audioin));Sound(AudioIn,FS)图绘图(TimeVector,AudioIn)轴([(TwoStart / FS)(TwoStop / FS)-1 1])Ylabel(“振幅”)包含(“时间(s)”)标题(的话语——两个)
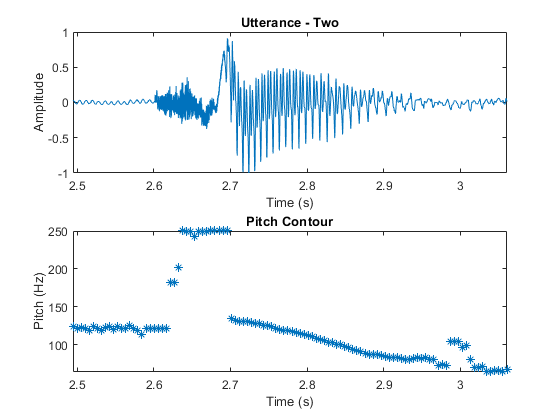
语音信号在性质中是动态的,随时间变化。假设语音信号在短时间比例上静止,并且它们的处理在20-40毫秒的窗口中完成。此示例使用30毫秒的窗口,25毫秒重叠。使用球场函数查看音高如何随时间变化。
windowLength =圆(0.03 * fs);overlapLength =圆(0.025 * fs);F0 =音高(AudioIn,FS,“WindowLength”windowLength,'overlaplencth',overtaplength,“范围”,[50,250]);图形子图(2,1,1)绘图(TimeVector,AudioIn)轴([(110E3 / FS)(135E3 / FS)-1 1])Ylabel(“振幅”)包含(“时间(s)”)标题(的话语——两个) subplot(2,1,2) timeVectorPitch = linspace((twoStart/fs),(twoStop/fs),numel(f0));情节(timeVectorPitch f0,‘*’) axis([(110e3/fs) (135e3/fs) min(f0) max(f0)]) ylabel(“音高(Hz)”)包含(“时间(s)”)标题(“基音轮廓”)
这球场函数估计每一帧的音调值。然而,音高仅在浊音区域是音源的特征。区分沉默和说话最简单的方法是分析短期力量。如果一个帧的能量高于给定的阈值,则声明该帧为speech。
pwrThreshold = -20;(段,~)=缓冲区(audioIn、windowLength overlapLength,'nodelay');压水式反应堆= pow2db (var(段));IssPeepeeP =(PWR> PWRTHESHOLD);
区分浊音和浊音最简单的方法是分析过零率。大量的零交叉意味着低频振荡不占主导地位。如果一帧的过零率低于一个给定的阈值,则宣布它为浊音。
Zcrheshold = 300;zeroloc =(audioin == 0);CrossEdzero =逻辑([0;差异(符号(isaivin))]);CROSSEDZERO(ZEROLOC)= FALSE;[十字击败,〜] =缓冲区(Crossedzero,WindowLength,overlaplength,'nodelay');zcr = (sum (crossedZeroBuffered 1) * fs) / (2 * windowLength);is浊= (zcr < zcrThreshold);
结合发行和发了思考确定一个帧是否包含语音。
voicedSpeech = isSpeech & is浊;
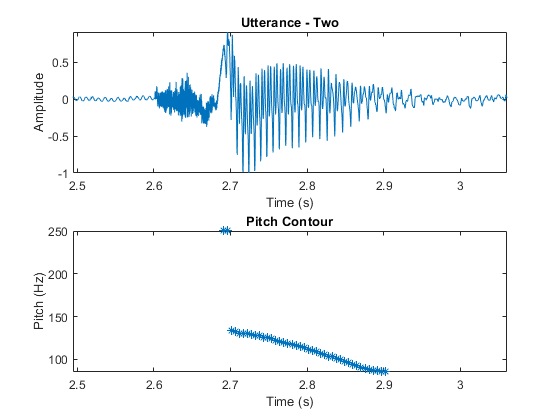
从音高估计和绘图中删除不对应于声音语音的区域。
F0(〜voicepeech)= nan;图形子图(2,1,1)绘图(TimeVector,AudioIn)轴([(110e3 / fs)(135e3 / fs)-1 1])轴紧ylabel (“振幅”)包含(“时间(s)”)标题(的话语——两个次要情节(2,1,2)情节(timeVectorPitch f0,‘*’) axis([(110e3/fs) (135e3/fs) min(f0) max(f0)]) ylabel(“音高(Hz)”)包含(“时间(s)”)标题(“基音轮廓”)
熔融频率Cepstrum系数(MFCC)
MFCC是从语音信号中提取的流行功能,以用于识别任务。在语音源过滤器模型中,MFCC应理解为代表过滤器(声道)。声道的频率响应相对平滑,而浊音语音源可以被建模为脉冲列车。结果是声道可以通过语音段的光谱包络估计。
基于对耳蜗的理解,MFCC的激励思想是将关于声乐道(平滑光谱)的信息压缩成少数系数。
虽然没有用于计算MFCC的硬标准,但图表概述了基本步骤。
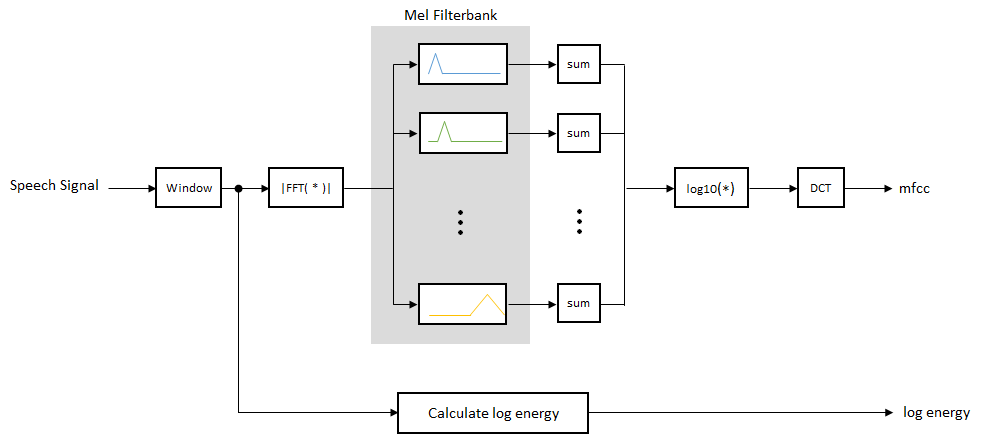
mel滤波器组线性空间前10个三角形滤波器和对数空间的其余滤波器。单个波段的能量是均匀的。该图代表了一个典型的mel滤波器组。
这个例子用途mfcc计算每个文件的MFCC。
数据集
本例使用CMU鲁棒语音识别组的普查数据库(亦称AN4数据库)[1].数据集包含讲话和数字的男性和女性受试者的录制。本节中的帮助程序功能为您下载并将原始文件转换为FLAC。语音文件基于对应于扬声器的标签将语音文件分成子目录。如果您无法下载它,则可以加载来自的功能表Helperan4trainingFeatures.mat然后直接进入训练一个分类器部分。这些特征是从同一数据集中提取出来的。
使用该临时目录下载并提取10个扬声器(5个女性和5名男性)的语音文件Helperan4download.功能。
datadir = helperan4download;
创建一个audiodatastore.对象来管理此数据库以进行培训。数据存储允许您收集文件格式的必要文件并读取它们。
广告= audiodataStore(Datadir,“IncludeSubfolders”,真的,......“FileExtensions”那'.flac'那......“LabelSource”那'foldernames')
广告=带有属性的auidataStore:文件:{'... \ scrawfor \ appdata \ local \ temp \ an4 \ wav \ flacdata \ fejs \ an36-fejs-b.flac';’……当地\ Temp \ scrawfor \ AppData \ \ an4 \ wav \ flacData \ fejs \ an37-fejs-b.flac”;'... \ scrawfor \ appdata \ local \ temp \ an4 \ wav \ flacdata \ fejs \ an38-fejs-b.flac'a和122更多}文件夹:{'c:\ users \ scrawfor \ appdata \ local\ temp \ An4 \ Wav \ Flacdata'}标签:[FEJS;fejs;FEJS ...和122更多分类] rectratefilesystemroots:{} OutputDatatype:'Double'SupportedOutputFormat金宝apps:[“WAV”“FLAC”“OGG”“MP4”“M4A”] DefaultOutputFormat:“WAV”
这spliteachlabel.功能audiodatastore.将数据存储分割为两个或多个数据存储。结果数据存储具有来自每个标签的指定比例的音频文件。在本例中,数据存储被分成两部分。每个标签80%的数据用于训练,剩下的20%用于测试。这countEachLabel的方法audiodatastore.用于计算每个标签的音频文件数量。在本例中,标签标识说话者。
[adsTrain, adsTest] = splitachlabel (ads,0.8);
显示列车数据存储中的数据存储和扬声器数量。
坦白
adsTrain = audioDatastore with properties: Files:{'…\ \涂鸦\AppData\Local\Temp\an4\wav\flacData\fejs\an36-fejs-b.flac';’……当地\ Temp \ scrawfor \ AppData \ \ an4 \ wav \ flacData \ fejs \ an37-fejs-b.flac”;“…当地\ Temp \ scrawfor \ AppData \ \ an4 \ wav \ flacData \ fejs \ an38-fejs-b。flac的……{'C:\Users\ scrifor \AppData\Local\Temp\an4\wav\flacData'}标签:[fejs;fejs;fejs……alteratefilesystemroots: {} OutputDataType: 'double' SupportedOutputFormats: ["金宝appwav" "flac" "ogg" "mp4" "m4a"] DefaultOutputFormat: "wav"
TrainDataStoreCount = CounteChentLabel(adstrain)
trainDatastoreCount =10×2表标签计数_____ _____ fejs 10 fmjd 10 fsrb 10 ftmj 10 fwxs 10 mcen 10 mrcb 10 msjm 10 msjr 10 msmn 7
显示数据存储和测试数据存储中的扬声器数量。
adsTest
adsTest = audioDatastore与属性:文件:{'…\ \涂鸦\AppData\本地\Temp\an4\wav\flacData\fejs\cen6-fejs- b.l ac';’……当地\ Temp \ scrawfor \ AppData \ \ an4 \ wav \ flacData \ fejs \ cen7-fejs-b.flac”;“…当地\ Temp \ scrawfor \ AppData \ \ an4 \ wav \ flacData \ fejs \ cen8-fejs-b。flac的……{'C:\Users\ scrifor \AppData\Local\Temp\an4\wav\flacData'}标签:[fejs;fejs;fejs……alteratefilesystemroots: {} OutputDataType: 'double' SupportedOutputFormats: ["金宝appwav" "flac" "ogg" "mp4" "m4a"] DefaultOutputFormat: "wav"
testdataStoreCount = CountAckeLabel(adstest)
testDatastoreCount =10×2表标签数___________ FEJS 3 FMJD 3 FSRB 3 FTMJ 3 FWXS 2 MCEN 3 MRCB 3 MSJM 3 MSJR 3 MSMN 2
要预览数据存储的内容,请阅读示例文件并使用默认音频设备播放。
[sampleTrain, dsInfo] = read(adsTrain);声音(sampleTrain dsInfo.SampleRate)
从列车数据存储中读取数据会推入读取指针,以便您可以遍历数据库。重新设置列车数据存储,将读取指针返回到下面特征提取的起点。
重置(adstrain)
特征提取
从训练数据存储中对应于发声语音的每一帧中提取基音和MFCC特征。支持函数金宝app,isVoicedSpeech,执行中概述的语音检测基音特征提取的描述.
FS = DSINFO.SAMPLEDE;windowLength =圆(0.03 * fs);overlapLength =圆(0.025 * fs);功能= [];标签= [];而hasdata(adsTrain) [audioIn,dsInfo] = read(adsTrain);melC = mfcc (audioIn fs,'窗户',汉明(WindowLength,'定期'),'overlaplencth', overlapLength);F0 =音高(AudioIn,FS,“WindowLength”windowLength,'overlaplencth', overlapLength);壮举= (melC, f0);voicedSpeech = isVoicedSpeech (audioIn fs, windowLength overlapLength);壮举(~ voicedSpeech,:) = [];label = repelem(dsinfo.label,size(feat,1));特点=(功能;壮举);标签= [标签,标签];结尾
音高和MFCC不在相同的范围内。这将偏置分类器。通过减去平均值并除去标准偏差来归一化特征。
m =均值(特征,1);s = std(特征,[],1);特征=(特点-m)./ s;
训练一个分类器
现在您已经收集了所有10个扬声器的功能,您可以根据它们培训分类器。在此示例中,您可以使用K-Collect邻居(KNN)分类器。KNN是一种自然适用于多字母分类的分类技术。最近邻分类的超参数包括最近邻居的数量,用于计算到邻居的距离的距离度量以及距离度量的权重。选择超参数以优化测试集上的验证精度和性能。在该示例中,邻居的数量被设置为5,所选择的距离的度量是平方 - 反向加权欧几里德距离。有关分类器的更多信息,请参阅Fitcknn.(统计和机器学习工具箱).
训练分类器并打印交叉验证的准确性。横梁(统计和机器学习工具箱)和Kfoldloss.(统计和机器学习工具箱)用于计算KNN分类器的交叉验证精度。
指定所有分类器选项并训练分类器。
troughtclassifier = fitcknn(......的特性,......标签,......“距离”那“欧几里得”那......“NumNeighbors”5,......'远程重量'那'squaredinverse'那......“标准化”假的,......“类名”,独特(标签));
执行交叉验证。
k = 5;组=标签;c = cvpartition(组,'kfold'、k);%5折叠分层交叉验证partitionedmodel = crossval(TroughtClassifier,“CVPartition”c);
计算验证准确性。
ValidationAccuracy = 1 - Kfoldloss(PartitionedModel,'lockfun'那'classiferror');fprintf('\nValidation accuracy = %.2f%%\n',验证成分* 100);
验证精度= 97.64%
可视化混乱图表。
validationPredictions = kfoldPredict (partitionedModel);figure cm = confusionchart(标签,验证,预测,'标题'那“验证准确性”);厘米。ColumnSummary ='列 - 归一化';cm.rowsummary =“row-normalized”;
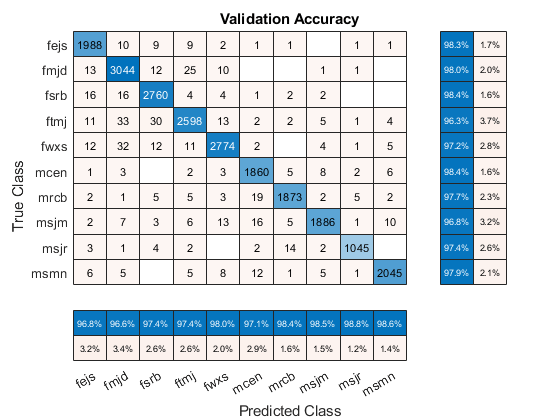
你也可以使用分类学习者(统计和机器学习工具箱)应用程序尝试和比较各种分类器与你的功能表。
测试分类器
在本节中,您将训练的KNN分类器与来自10个扬声器中的每一个的语音信号测试,看看它的表现与不用于训练它的信号。
读取文件,从测试集中提取特性,并将它们规范化。
功能= [];标签= [];numvectorsperfile = [];而hasdata(adsTest) [audioIn,dsInfo] = read(adsTest);melC = mfcc (audioIn fs,'窗户',汉明(WindowLength,'定期'),'overlaplencth', overlapLength);F0 =音高(AudioIn,FS,“WindowLength”windowLength,'overlaplencth', overlapLength);壮举= (melC, f0);voicedSpeech = isVoicedSpeech (audioIn fs, windowLength overlapLength);壮举(~ voicedSpeech,:) = [];numVec =大小(功绩,1);标签= repelem (dsInfo.Label numVec);numVectorsPerFile = [numVectorsPerFile, numVec];特点=(功能;壮举);标签= [标签,标签];结尾特征=(特点-m)./ s;
通过呼叫预测每个帧的标签(扬声器)预测在TrousoIrclassifier.
预测=预测(TroughtClassifier,特征);预测=分类(字符串(预测));
可视化混乱图表。
图(“单位”那'标准化'那“位置”,[0.4 0.4 0.4]) cm = confusionchart(标签,预测,'标题'那“测试准确度(每帧)”);厘米。ColumnSummary ='列 - 归一化';cm.rowsummary =“row-normalized”;
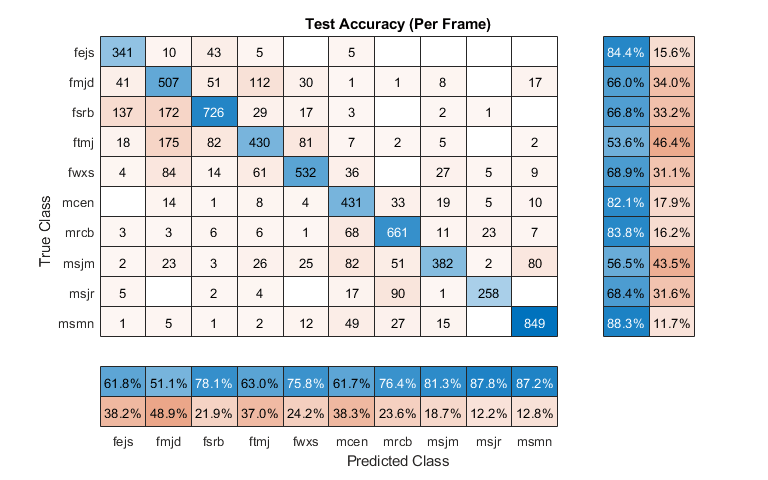
对于给定的文件,将对每一帧进行预测。确定每个文件的预测模式,然后绘制混淆图。
r2 =预测(1:numel(adstest.files));Idx = 1;为了II = 1:numel(adstest.files)r2(ii)= mode(预测(idx:idx + numvectors perfile(ii)-1));idx = idx + numvectors perfile(ii);结尾图(“单位”那'标准化'那“位置”,[0.4 0.4 0.4 0.4]) cm = confusionchart(adsTest。标签,r2,'标题'那“测试准确度(每个档案)”);厘米。ColumnSummary ='列 - 归一化';cm.rowsummary =“row-normalized”;
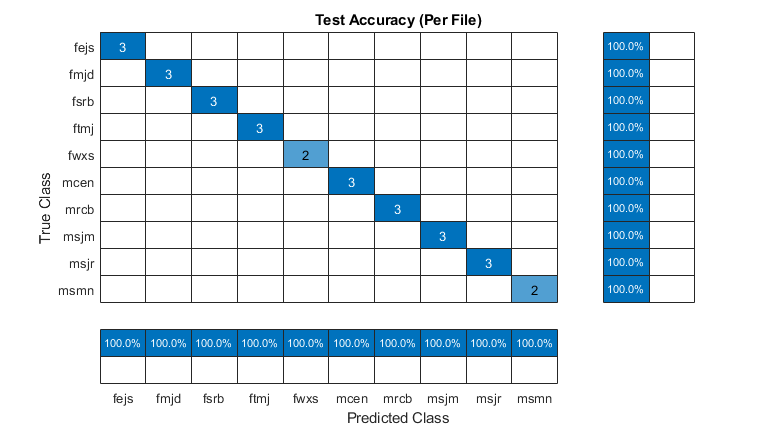
预测的扬声器与预期的扬声器与正在测试的所有文件匹配。
使用内部开发的数据集重复该实验。DataSet由20个扬声器组成,每个扬声器从哈佛句子列表中讲多个句子[2].对于20位演讲者,验证准确率为89%。
金宝app支持功能
函数VoiceSpeech = IsvoiceCeech(x,fs,windowlength,voloraplength)pwrthreshold = -40;[段,〜] =缓冲区(x,windowlength,overlaplength,'nodelay');压水式反应堆= pow2db (var(段));IssPeepeeP =(PWR> PWRTHESHOLD);zcrheshold = 1000;zeroloc =(x == 0);CrossEdzero =逻辑([0;差异(符号(x))]);CROSSEDZERO(ZEROLOC)= FALSE;[十字击败,〜] =缓冲区(Crossedzero,WindowLength,overlaplength,'nodelay');zcr = (sum (crossedZeroBuffered 1) * fs) / (2 * windowLength);is浊= (zcr < zcrThreshold);voicedSpeech = isSpeech & is浊;结尾
参考文献
CMU Sphinx集团音频数据库。已于2019年12月19日生效。http://www.speech.cs.cmu.edu/databases/an4/.
[2]“哈佛的句子。”维基百科,2019年8月27日。维基百科那https://en.wikipedia.org/w/index.php?title=harvard_sentences &oldid=912785385.
你也可以从以下列表中选择一个网站: