使用深度学习的序列到序列回归
这个例子展示了如何使用深度学习来预测发动机的剩余使用寿命(RUL)。
为了训练深度神经网络从时间序列或序列数据中预测数值,您可以使用长短期记忆(LSTM)网络。
本例使用[1]中描述的涡扇发动机退化模拟数据集。该示例训练LSTM网络来预测发动机的剩余使用寿命(预测性维护),以周期为单位,给定时间序列数据表示发动机中的各种传感器。训练数据包含100台发动机的模拟时间序列数据。每个序列的长度不同,对应于一个完整的运行到故障(RTF)实例。测试数据包含100个部分序列,以及每个序列末尾的剩余使用寿命对应值。
数据集包含100个训练观测值和100个测试观测值。
下载数据
从。下载并解压涡扇发动机退化仿真数据集https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/[2]。
涡扇发动机退化仿真数据集的每个时间序列代表一个不同的发动机。每台发动机的初始磨损程度和制造变化都是未知的。在每个时间序列开始时,引擎运行正常,但在该时间序列的某个时间点出现故障。在训练集中,故障的大小逐渐增大,直到系统失效。
数据包含一个zip压缩的文本文件,其中有26列数字,用空格分隔。每一行是在单个操作周期中所采集的数据的快照,每列是一个不同的变量。各列对应如下:
列1 -单元号
列2 -以周期为单位的时间
列3-5 -操作设置
列6-26 -传感器测量1-21
创建一个目录来存储涡扇发动机退化仿真数据集。
dataFolder = fullfile(tempdir,“涡扇”);如果~存在(dataFolder“dir”mkdir (dataFolder);结束
下载并提取涡扇发动机退化仿真数据集https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/.
从文件中解压缩数据CMAPSSData.zip.
文件名=“CMAPSSData.zip”;解压缩(文件名,dataFolder)
准备培训数据
使用函数加载数据processTurboFanDataTrain附在本例中。这个函数processTurboFanDataTrain从filenamePredictors并返回单元格数组XTrain而且YTrain,其中包含训练预测器和响应序列。
fileamepredictors = fullfile(数据文件夹,“train_FD001.txt”);[XTrain,YTrain] = processTurboFanDataTrain(filenamePredictors);
删除带有常量值的特性
在所有时间步骤中保持不变的特征会对训练产生负面影响。找出具有相同最小值和最大值的数据行,并删除这些行。
m = min([XTrain{:}],[],2);M = max([XTrain{:}],[],2);idxConstant = M == M;为i = 1: number (XTrain) XTrain{i}(idxConstant,:) = [];结束
查看序列中剩余特征的数量。
numFeatures = size(XTrain{1},1)
numFeatures = 17
规范化训练预测器
将训练预测器归一化,使其具有零均值和单位方差。要计算所有观测值的平均值和标准偏差,请水平连接序列数据。
mu = mean([XTrain{:}],2);sig = std([XTrain{:}],0,2);为i = 1: number (XTrain) XTrain{i} = (XTrain{i} - mu) ./ sig;结束
剪辑的反应
为了在引擎接近失效时从序列数据中了解更多信息,将响应剪辑到阈值150。这使得网络平等地对待具有更高RUL值的实例。
THR = 150;为i = 1:数字(YTrain) YTrain{i}(YTrain{i} > thr) = thr;结束
该图显示了第一次观测和相应的剪切响应。

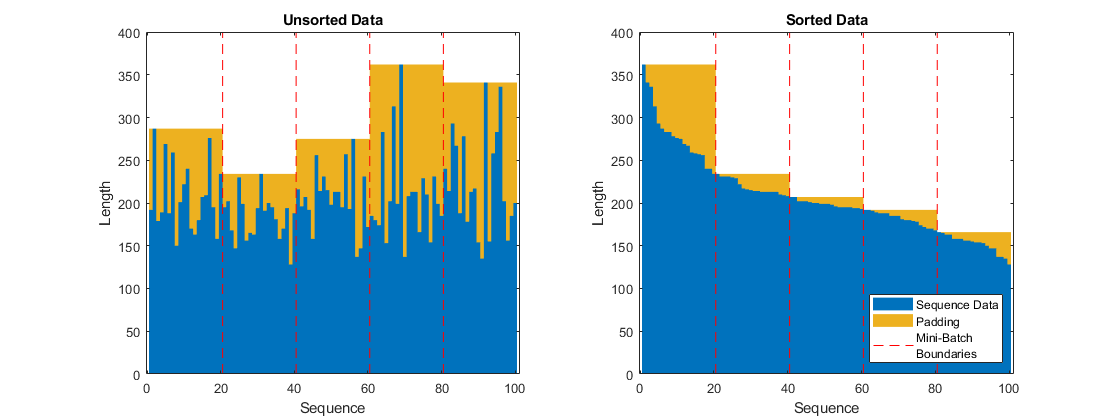
为填充准备数据
为了尽量减少添加到小批中的填充量,按照序列长度对训练数据进行排序。然后,选择一个小批量大小,它平均分配训练数据,并减少小批量中的填充量。
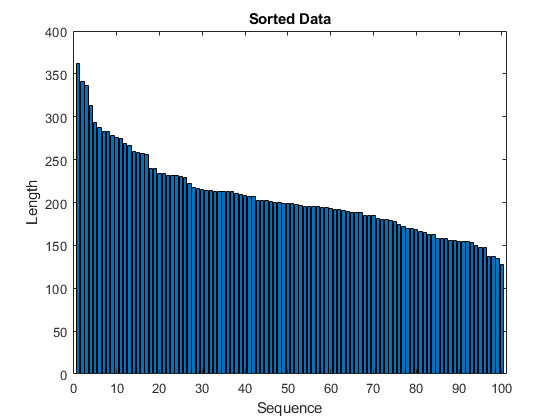
按序列长度对训练数据进行排序。
为i=1:数字(XTrain)序列= XTrain{i};sequenceLengths(i) = size(sequence,2);结束[sequenceLengths,idx] = sort(sequenceLengths, idx)“下”);XTrain = XTrain(idx);YTrain = YTrain(idx);
在条形图中查看排序的序列长度。
xlabel(“序列”) ylabel (“长度”)标题(“排序数据”)
选择一个小批量大小,均匀地划分训练数据,并减少小批量中的填充量。指定一个小批大小为20。该图说明了添加到未排序序列和已排序序列的填充。
miniBatchSize = 20;
定义网络架构
定义网络架构。创建一个LSTM网络,由一个包含200个隐藏单元的LSTM层,接着是一个大小为50的全连接层和一个退出概率为0.5的退出层组成。
numResponses = size(YTrain{1},1);numHiddenUnits = 200;层= [...sequenceInputLayer numFeatures lstmLayer (numHiddenUnits,“OutputMode”,“序列”) fullyConnectedLayer(50) dropoutLayer(0.5) fullyConnectedLayer(numResponses) regressionLayer];
指定培训选项。使用求解器训练60个小批次,大小为20“亚当”.指定学习率为0.01。为了防止梯度爆炸,将梯度阈值设置为1。若要保持序列按长度排序,请设置“洗牌”来“永远”.
maxEpochs = 60;miniBatchSize = 20;选项= trainingOptions(“亚当”,...“MaxEpochs”maxEpochs,...“MiniBatchSize”miniBatchSize,...“InitialLearnRate”, 0.01,...“GradientThreshold”, 1...“洗牌”,“永远”,...“阴谋”,“训练进步”,...“详细”, 0);
培训网络
使用trainNetwork.
net = trainNetwork(XTrain,YTrain,图层,选项);
测试网络
使用函数准备测试数据processTurboFanDataTest附在本例中。这个函数processTurboFanDataTest从filenamePredictors而且filenameResponses并返回单元格数组XTest而且欧美,分别包含测试预测器和响应序列。
fileamepredictors = fullfile(数据文件夹,“test_FD001.txt”);fileameresponses = fullfile(数据文件夹,“RUL_FD001.txt”);[XTest,YTest] = processTurboFanDataTest(filenamePredictors, filenamerresponses);
删除使用常量值的特性idxConstant由训练数据计算。使用与训练数据中相同的参数标准化测试预测器。在用于训练数据的相同阈值处剪辑测试响应。
为i = 1: number (XTest) XTest{i}(idxConstant,:) = [];XTest{i} = (XTest{i} - mu) ./ sig;YTest{i} > thr) = thr;结束
对测试数据进行预测预测.若要防止函数向数据添加填充,请指定迷你批处理大小为1。
YPred =预测(net,XTest,“MiniBatchSize”1);
LSTM网络对部分序列进行一次一步的预测。在每个时间步中,网络使用该时间步的值进行预测,并且仅使用从前一个时间步中计算的网络状态。网络在每次预测之间更新它的状态。的预测函数返回这些预测的序列。预测的最后一个元素对应于部分序列的预测RUL。
或者,您可以使用predictAndUpdateState.当您有到达流的时间步长的值时,这很有用。通常,与一次一步地进行预测相比,对完整序列进行预测更快。有关显示如何通过在单个时间步预测之间更新网络来预测未来时间步的示例,请参见利用深度学习进行时间序列预测.
把一些预测用图解的形式表现出来。
idx = randperm(数字(YPred),4);数字为i = 1:数字(idx) subplot(2,2,i) plot(YTest{idx(i)},“——”)举行在情节(YPred {idx (i)},“。”)举行从Ylim ([0 THR + 25])“试验观察”+ idx(i)) xlabel(“时间步”) ylabel (“原则”)结束传奇([“测试数据”“预测”],“位置”,“东南”)
对于给定的部分序列,预测的电流RUL是预测序列的最后一个元素。计算预测的均方根误差(RMSE),并在直方图中可视化预测误差。
为i = 1:numel(YTest) YTestLast(i) = YTest{i}(end);YPredLast(i) = YPred{i}(end);结束图rmse =√(mean(YPredLast - YTestLast).^2)直方图(YPredLast - YTestLast)" rmse = "+ rmse) ylabel(“频率”)包含(“错误”)
参考文献
Saxena, Abhinav, Kai Goebel, Don Simon和Neil Eklund。飞机发动机运行故障模拟的损伤传播模型。在《预测与健康管理》,2008年。2008年榜单。国际环境保护会议,第1-9页。IEEE 2008。
Saxena, Abhinav, Kai Goebel。涡扇发动机退化仿真数据集NASA艾姆斯预测数据仓库https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/美国宇航局艾姆斯研究中心,莫菲特场,加利福尼亚州
另请参阅
trainNetwork|trainingOptions|lstmLayer|sequenceInputLayer|predictAndUpdateState
相关的话题
您也可以从以下列表中选择一个网站:
