用浅神经网络分类模式
例如,假设您想根据细胞大小的均匀性、团块厚度、有丝分裂等将肿瘤分类为良性或恶性。你有699个案例你有9个特征和正确的良性或恶性分类。
与函数拟合一样,有两种方法来解决这个问题:
使用神经网络模式识别应用程序,如使用神经网络模式识别应用程序分类模式.
使用命令行函数,如使用命令行函数分类模式.
通常最好从应用程序开始,然后使用应用程序自动生成命令行脚本。在使用任何一种方法之前,首先通过选择一个数据集来定义问题。每个神经网络应用程序都可以访问许多示例数据集,您可以使用这些数据集来实验工具箱(参见浅层神经网络样本数据集).如果您有一个想要解决的特定问题,您可以将自己的数据加载到工作区中。下一节描述数据格式。
提示
为了交互式地建立和训练深度网络,使用深度网络设计器.
定义问题
来定义一个模式识别问题,将一组输入向量(预测器)排列为矩阵中的列。然后排列另一组响应向量,指示分配观察值的类别。
当只有两个类时,每个响应都有两个元素,0和1,表示对应的观察属于哪个类。例如,你可以这样定义一个两类分类问题:
预测因子= [7 10 3 1 6;5 8 1 1 6;6 7 1 1 6];响应= [0 0 1 1 0;1 1 0 0 1];
当预测因子被分类时N不同的班级,有不同的反应N元素。对于每个响应,一个元素为1,其他元素为0。例如,下面几行显示了如何定义一个分类问题,该问题将一个5 × 5 × 5立方体的角分为三个类:
一个类中的原点(第一个输入向量)
在第二类中离原点(最后一个输入向量)最远的角
所有在第三类中的点
预测因子= [0 0 0 0 5 5 5 5;0 0 5 5 0 0 5 5;0 5 0 5 0 5 0 5];响应= [1 0 0 0 0 0 0 0 0;0 1 1 1 1 1 1 10 0;0 0 0 0 0 0 1];
下一节将展示如何训练网络以识别模式,使用神经网络模式识别本例使用工具箱提供的示例数据集。
使用神经网络模式识别应用程序分类模式
这个例子展示了如何训练一个浅神经网络来分类模式使用神经网络模式识别应用程序。
打开神经网络模式识别应用程序使用nprtool.
nprtool

选择数据
的神经网络模式识别App有示例数据来帮助你开始训练神经网络。
要导入示例玻璃分类数据,请选择进口>导入玻璃数据集.你可以使用这个数据集来训练神经网络,根据玻璃化学的性质将玻璃分类为窗户或非窗户。如果从文件或工作区导入自己的数据,则必须指定预测器和响应,以及观察结果是行还是列。

控件中显示有关导入数据的信息模型的总结.该数据集包含214个观测值,每个观测值有9个特征。每个观测结果都被分为两类:窗口或非窗口。

将数据分成训练集、验证集和测试集。保持默认设置。数据分为:
70%用于培训。
15%用于验证网络是泛化的,并在过拟合之前停止训练。
15%独立测试网络泛化。
有关数据划分的详细信息,请参见最佳神经网络训练的数据划分.
创建网络
该网络为两层前馈网络,隐层为sigmoid传递函数,输出层为softmax传递函数。隐藏层的大小对应于隐藏神经元的数量。默认图层大小为10.的网络结构中可以看到网络窗格。输出神经元的数量设置为2,这等于响应数据指定的类的数量。

列车网络的
需要训练网络时,单击火车.
在培训窗格,可以看到训练进度。训练继续进行,直到满足其中一个停止标准。在这个例子中,训练继续进行,直到验证错误连续增加6次迭代(“满足验证标准”)。
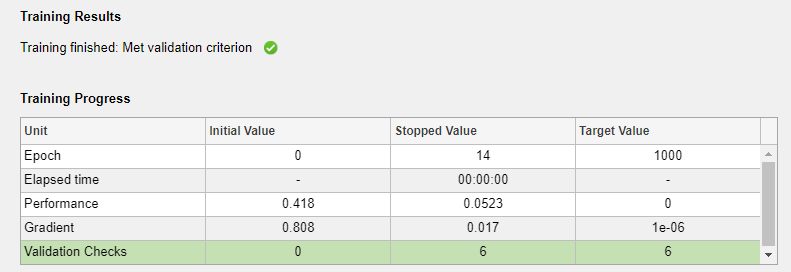
分析结果
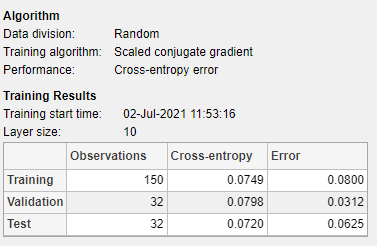
的模型的总结包含关于每个数据集的训练算法和训练结果的信息。
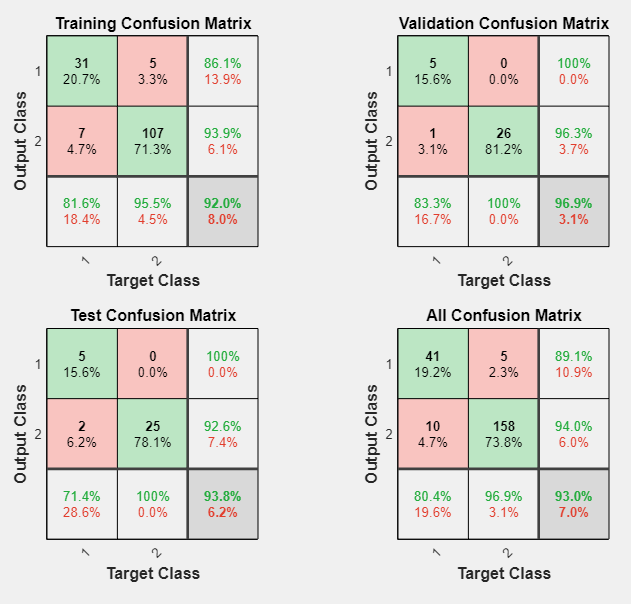
您可以通过生成图表进一步分析结果。要绘制混淆矩阵,请在情节部分中,点击混淆矩阵.网络输出非常准确,正如您可以看到的那样,绿色方格(对角线)中正确分类的数量很高,而红色方格(非对角线)中错误分类的数量很少。
查看ROC曲线以获得网络性能的额外验证。在情节部分中,点击ROC曲线.

每个轴上的彩色线代表ROC曲线。ROC曲线是真阳性率(敏感性)与假阳性率(1 -特异性)随阈值变化的曲线。一个完美的测试应该在左上角显示点,具有100%的灵敏度和100%的特异性。对于这个问题,该网络的性能非常好。
如果您对网络性能不满意,您可以执行以下操作之一:
再次训练网络。
增加隐藏神经元的数量。
使用更大的训练数据集。
如果训练集的性能很好,但测试集的性能很差,这可能表明模型过拟合。减少神经元数量可以减少过拟合。
您还可以在附加的测试集上评估网络性能。中加载附加测试数据以评估网络测试部分中,点击测试.的模型的总结显示额外的测试结果。您还可以生成图来分析额外的测试结果。
生成代码
选择生成代码>生成简单的培训脚本创建MATLAB代码,从命令行复制前面的步骤。如果您想学习如何使用工具箱的命令行功能来定制训练过程,那么创建MATLAB代码可能会很有帮助。在使用命令行函数分类模式,您将更详细地研究生成的脚本。

出口网络
您可以将训练过的网络导出到工作区或Simulink®。金宝app您还可以使用MATLAB编译器™和其他MATLAB代码生成工具部署网络。若要导出经过训练的网络和结果,请选择出口模式>导出到工作区.

使用命令行函数分类模式
学习如何使用工具箱的命令行功能的最简单方法是从应用程序生成脚本,然后修改它们以定制网络训练。方法创建的简单脚本作为示例神经网络模式识别应用程序。
用神经网络解决一个模式识别问题%由神经模式识别应用程序生成的脚本%创建于2021年3月22日16:50:20%这个脚本假设这些变量已经定义:%% glassInputs -输入数据。glassTargets -目标数据。x = glassInputs;t = glassTargets;选择一个训练功能对于所有训练功能的列表,键入:help nntrain火车通常是最快的。'trainbr'花的时间较长,但可能更适合解决具有挑战性的问题。'trainscg'使用较少内存。适用于内存不足的情况。trainFcn =“trainscg”;%缩放共轭梯度反向传播。创建一个模式识别网络hiddenLayerSize = 10;net = patternnet(hiddenLayerSize, trainFcn);为培训、验证、测试设置数据部门net.divideParam.trainRatio = 70/100;net.divideParam.valRatio = 15/100;net.divideParam.testRatio = 15/100;%培训网络[net,tr] = train(net,x,t);%测试网络Y = net(x);E = gsubtract(t,y);性能=执行(net,t,y) tind = vec2ind(t);Yind = vec2ind(y);percentterrors = sum(tind ~= yind)/numel(tind);%查看网络视图(净)%的情节取消注释这些行以启用各种图。%, plotperform (tr)%, plottrainstate (tr)%, ploterrhist (e)%, plotconfusion (t, y)%, plotroc (t, y)
您可以保存脚本,然后从命令行运行它,以重现上一个训练会话的结果。您还可以编辑脚本以自定义培训过程。在本例中,遵循脚本中的每个步骤。
选择数据
脚本假设预测器和响应向量已经加载到工作区中。如果数据未加载,可按如下方式加载:
负载glass_dataset
glassInputs以及他们的反应glassTargets进入工作区。
此数据集是工具箱中的示例数据集之一。有关可用数据集的信息,请参见浅层神经网络样本数据集.输入该命令还可以查看所有可用数据集的列表帮助nndatasets.您可以使用自己的变量名从这些数据集中加载变量。例如,命令
[x,t] = glass_dataset;
x玻璃响应到数组中t.
选择训练算法
定义训练算法。
trainFcn =“trainscg”;%缩放共轭梯度反向传播。
创建网络
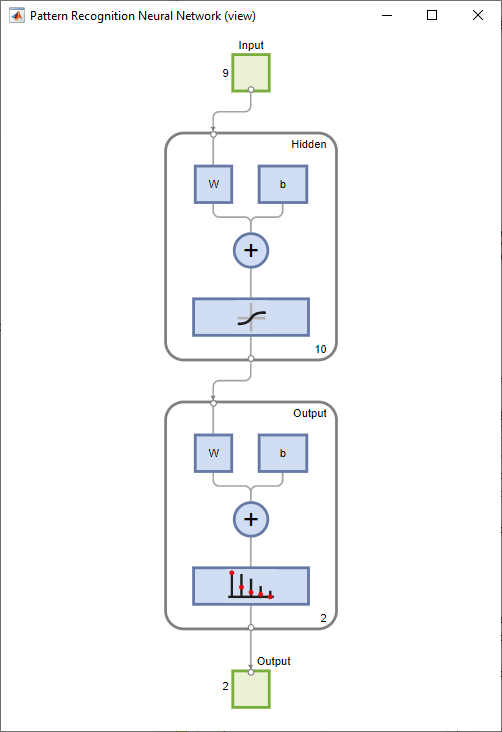
创建网络。模式识别(分类)问题的默认网络,patternnet,为前馈网络,隐含层默认sigmoid传递函数,输出层默认softmax传递函数。网络有一个包含十个神经元(默认)的单一隐藏层。
网络有两个输出神经元,因为每个输入向量有两个响应值(类)。每个输出神经元代表一个类。当适当类别的输入向量应用于网络时,对应的神经元应该产生一个1,其他神经元应该输出一个0。
hiddenLayerSize = 10;net = patternnet(hiddenLayerSize, trainFcn);
请注意
更多的神经元需要更多的计算,当数量设置过高时,它们有过度拟合数据的倾向,但它们允许网络解决更复杂的问题。更多的层需要更多的计算,但它们的使用可能会导致网络更有效地解决复杂的问题。中数组的元素输入隐藏层大小,即可使用多个隐藏层patternnet命令。
把数据
设置数据的划分。
net.divideParam.trainRatio = 70/100;net.divideParam.valRatio = 15/100;net.divideParam.testRatio = 15/100;
通过这些设置,预测向量和响应向量被随机划分,其中70%用于训练,15%用于验证,15%用于测试。有关数据划分过程的详细信息,请参见最佳神经网络训练的数据划分.
列车网络的
培训网络。
[net,tr] = train(net,x,t);
在训练过程中,会打开训练进度窗口。你可以在任何时候通过点击停止按钮来中断训练![]() .
.
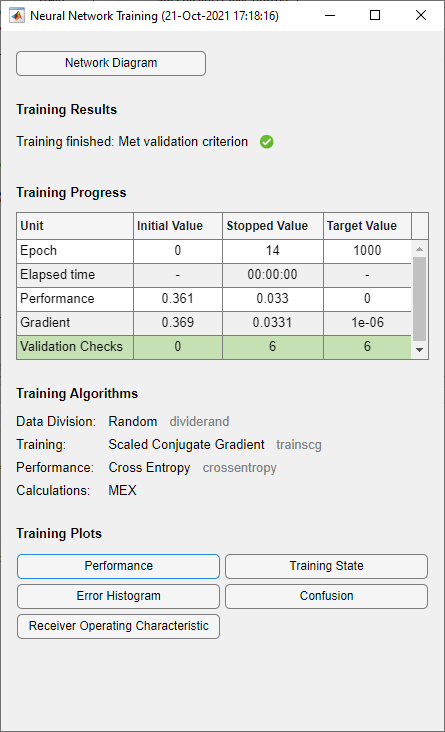
当验证错误连续增加6个迭代(发生在迭代14)时,训练结束。
如果你点击性能在训练窗口中,会出现训练误差、验证误差和测试误差的图表,如下图所示。
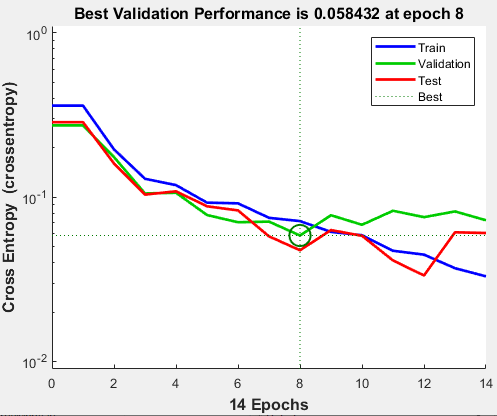
在本例中,由于最终交叉熵误差较小,结果是合理的。
测试网络
测试网络。在网络训练完成后,您可以使用它来计算网络输出。下面的代码计算网络输出、错误和总体性能。
Y = net(x);E = gsubtract(t,y);性能=执行(净,t,y)
Performance = 0.0659
你也可以计算错误分类的观测值的比例。在这个例子中,模型的误分类率非常低。
Tind = vec2ind(t);Yind = vec2ind(y);percentterrors = sum(tind ~= yind)/numel(tind)
percentterrors = 0.0514
通过使用位于训练记录中的测试指标,也可以仅在测试集上计算网络性能。
tInd = tr.testInd;tstOutputs = net(x(:,tInd));tstPerform = execute (net,t(tInd),tstOutputs)
tstPerform = 2.0163
查看网络
查看组网图。
视图(净)
分析结果
使用plotconfusion函数绘制混淆矩阵.您还可以通过单击来绘制每个数据集的混淆矩阵混乱在训练窗口。
图,plotconfusion (t, y)
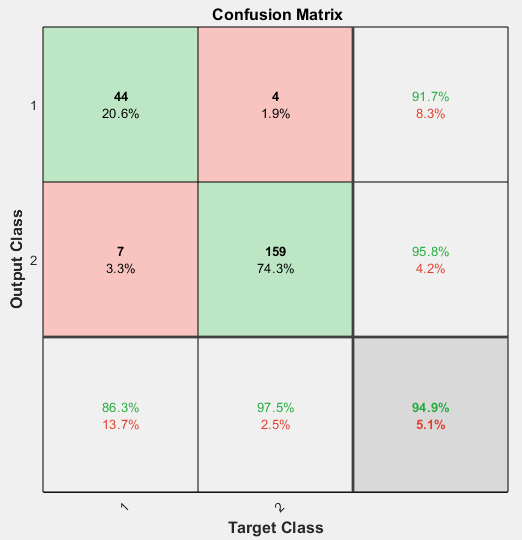
对角线的绿色单元格表示正确分类的病例数,非对角线的红色单元格表示错误分类的病例数。结果表明,识别效果良好。如果你需要更精确的结果,你可以尝试以下任何一种方法:
在本例中,网络结果令人满意,现在可以将网络用于新的输入数据。
下一个步骤
为了获得更多的命令行操作经验,您可以尝试以下任务:
在训练过程中,打开一个情节窗口(如混乱情节),并观看其动画。
等函数从命令行绘制
plotroc而且plottrainstate.
每次训练神经网络都会产生不同的解决方案,这是由于随机的初始权重和偏差值,以及数据分为训练集、验证集和测试集的不同划分。因此,针对同一问题训练的不同神经网络可以对相同的输入给出不同的输出。为了确保找到一个具有良好准确性的神经网络,需要重新训练几次。
如果需要更高的精度,还有其他几种技术可以改进初始解。金宝搏官方网站有关更多信息,请参见改进浅神经网络泛化,避免过拟合.
另请参阅
神经网络拟合|神经网络时间序列|神经网络模式识别|神经网络聚类|trainscg
相关的话题
您也可以从以下列表中选择一个网站: