dlupdate
使用自定义功能更新参数
语法
描述
[___) = dlupdate (另外,还指定了附加的输入参数,除了先前语法中的输入参数,何时乐趣,___A1,......,一个)乐趣是需要的函数的函数句柄n + 1输入值。
例子
L1正规化dlupdate
在参数梯度的结构上执行L1正则化。
创建示例输入数据。
dlx = dlarray(rand(100,100,3),SSC的);
初始化卷积操作的可读参数。
Params.weights = Dlarray(Rand(10,10,3,50));params.bias = dlarray(rand(50,1));
使用辅助功能计算卷积操作的梯度成本成员,在本例的末尾定义。
梯度= dlfeval (@convGradients、dlX params);
定义正则化因子。
l1factor = 0.001;
创建一个匿名函数,该函数正规化渐变。通过使用匿名功能将标量常量传递给函数,可以避免必须将常量值扩展到与参数变量相同的大小和结构。
L1Regularizer = @(grad,param) grad + L1Factor.*sign(param);
用dlupdate将正则化函数应用于每个渐变。
梯度= dlupdate(l1regularizer,梯度,params);
梯度毕业生现在根据该功能进行正常化L1Regularizer.
成本成员功能
的成本成员辅助功能采用卷积操作的可读参数和迷你批次输入数据dlX,并返回相对于可学习参数的梯度。
功能渐变= Concrigadients(DLX,Params)DLY = DLCONV(DLX,PARAMS.WEIGHTS,PARAMS.BIAS);dly = sum(dly,“所有”);梯度= dlgradient(dly,params);结束
用dlupdate使用自定义更新功能培训网络
用dlupdate使用实现随机梯度下降算法(无动量)的自定义更新函数训练网络。
负载培训数据
加载数字训练数据。
[XTrain, YTrain] = digitTrain4DArrayData;类=类别(YTrain);numClasses =元素个数(类);
定义网络
定义网络体系结构,并使用'吝啬的'选项在图像输入层中。
图层= [imageInputLayer([28 28 1],“名字”,“输入”,'吝啬的',平均值(xtrain,4))卷积2dlayer(5,20,“名字”,'conv1') reluLayer (“名字”,'relu1')卷积2dlayer(3,20,'填充',1,“名字”,“conv2”) reluLayer (“名字”,'relu2')卷积2dlayer(3,20,'填充',1,“名字”,“conv3”) reluLayer (“名字”,'relu3')全连接列(numcrasses,“名字”,'fc') softmaxLayer (“名字”,'softmax')];Lgraph = LayerGraph(层);
创建一个dlnetwork.来自图层图的对象。
dlnet = dlnetwork (lgraph);
定义模型渐变功能
创建辅助功能MapicalGRADENTERS.,列在本例的末尾。函数接受dlnetwork.对象DLNET.和迷你批次输入数据dlX具有相应的标签Y,返回损失和损失相对于可学习参数的梯度DLNET..
定义随机梯度下降功能
创建辅助功能sgdfunction.,列在本例的末尾。该功能需要帕纳和参数,一个可学习参数和损失相对于该参数的梯度,并使用随机梯度下降算法返回更新后的参数,表示为
在哪里 是迭代次数, 是学习率, 参数是向量,和 是损失功能。
指定培训选项
指定在培训期间使用的选项。
minibatchsize = 128;numepochs = 30;numobservations = numel(ytrain);numiterationsperepoch = bloor(numobservation./minibatchsize);
指定学习率。
学习= 0.01;
在GPU上的火车,如果有的话。使用GPU需要并行计算工具箱™和支持的GPU设备。金宝app有关支持设备的信息,请参阅金宝appGPU通金宝app过发布支持(并行计算工具箱).
executionEnvironment =“汽车”;
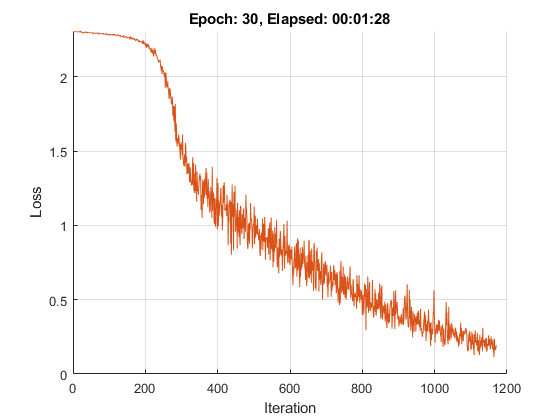
在一个情节中可视化训练进程。
情节=“培训 - 进展”;
列车网络的
使用自定义训练循环训练模型。对于每个epoch,将数据和循环扫描迷你批次数据。通过调用更新网络参数dlupdate与函数sgdfunction.在此示例结束时定义。在每个时代结束时,显示培训进度。
初始化培训进度情节。
如果plots ==.“培训 - 进展”图lineloSstrain =动画线('颜色'[0.85 0.325 0.098]);ylim([0正])包含(“迭代”)ylabel(“损失”) 网格上结束
培训网络。
迭代= 0;start = tic;为epoch = 1:numepochs%Shuffle数据。IDX = RANDPERM(NUMER(YTrain));XTrain = XTrain(:,:,idx);YTrain = Ytrain(IDX);为i = 1:numiterationsPerepoch迭代=迭代+ 1;%读取小批数据并将标签转换为假标签%变量。idx =(张)* miniBatchSize + 1:我* miniBatchSize;X = XTrain (:,:,:, idx);Y = 0 (numClasses, miniBatchSize,'单身的');为Y(c,YTrain(idx)==classes(c)) = 1;结束%将mini批次数据转换为dlarray。dlX = dlarray(单(X),'SSCB');%如果训练在GPU上,然后转换数据到一个gpuArray。如果(execultenvironment ==.“汽车”&& canUseGPU) || executionEnvironment ==“GPU”DLX = GPUARRAY(DLX);结束%使用dlfeval和dlfeval评估模型渐变和损失% modelGradients帮助函数。[渐变,损失] = DLFeval(@ Maposgradients,Dlnet,DLX,Y);%使用定义的SGD算法更新网络参数% sgdFunction辅助函数。updatefcn = @(dlnet,渐变)sgdfunction(dlnet,渐变,学习);dlnet = dlupdate(updatefcn,dlnet,渐变);%显示培训进度。如果plots ==.“培训 - 进展”d =持续时间(0,0,toc(start),'格式','hh:mm:ss');Addpoints(LineLoStrain,迭代,Double(收集(提取数据(丢失))))标题(“时代:”+时代+”,过去:“+字符串(d))绘制结束结束结束
测试网络
通过比较真实标签的测试集上的预测来测试模型的分类准确性。
[xtest,ytest] = digittest4darraydata;
将数据转换为adlarray使用维度格式'SSCB'.对于GPU预测,也将数据转换为GPUArray..
dlXTest = dlarray (XTest,'SSCB');如果(execultenvironment ==.“汽车”&& canUseGPU) || executionEnvironment ==“GPU”dlxtest = gpuarray(dlxtest);结束
用一个dlnetwork.对象,使用预测函数并找到最高分数的类。
dlYPred =预测(dlnet dlXTest);[~, idx] = max (extractdata (dlYPred), [], 1);YPred =类(idx);
评估分类准确性。
精度=意味着(YPred = =次)
精度= 0.9386.
模型梯度函数
辅助功能MapicalGRADENTERS.需要一个dlnetwork.对象DLNET.和迷你批次输入数据dlX具有相应的标签Y,返回损失和损失相对于可学习参数的梯度DLNET..若要自动计算梯度,请使用Dlgradient.函数。
功能[梯度,损失] = MaposGRADENTERS(DLNET,DLX,Y)DLYPRED =前进(DLNET,DLX);损失=联肾上腺素(Dlypred,Y);梯度= DLGRADIET(损失,DLNET.LEALNABLE);结束
随机梯度下降函数
辅助功能sgdfunction.采取学习参数范围,即该参数相对于损耗的梯度坡度,以及学习速率学习,并使用随机梯度下降算法返回更新的参数,表示为
在哪里 是迭代次数, 是学习率, 参数是向量,和 是损失功能。
功能参数= SGDFunction(参数,渐变,学习)参数=参数 - 学习。*渐变;结束
输入参数
输出参数
扩展能力
您还可以从以下列表中选择一个网站:
