使用一维卷积的序列到序列分类GydF4y2Ba
这个例子展示了如何使用一个通用的时间卷积网络(TCN)对序列数据的每个时间步骤进行分类。GydF4y2Ba
虽然序列到序列的任务通常使用递归神经网络结构来解决,但Bai等人[1]表明卷积神经网络可以在典型的序列建模任务上与递归网络的性能相匹配,甚至优于它们。使用卷积网络的潜在好处是更好的并行性,更好地控制感受野大小,更好地控制训练期间网络的内存占用,以及更稳定的梯度。就像递归网络一样,卷积网络可以对可变长度的输入序列进行操作,并且可以用于对序列到序列或序列到一个任务进行建模。GydF4y2Ba
这个例子训练了一个TCN网络,在给定三个不同方向的加速度计读数的时间序列数据下,识别佩戴智能手机的人的活动。该示例将TCN定义为一个函数,并使用一个定制的训练循环来训练模型。GydF4y2Ba
要在输入数据的时间维度上进行卷积(也称为1-D卷积),请使用GydF4y2BadlconvGydF4y2Ba函数并使用指定权重的尺寸GydF4y2Ba“权重格式”GydF4y2Ba选项或将权重指定为已格式化的GydF4y2BadlarrayGydF4y2Ba.GydF4y2Ba
负荷训练数据GydF4y2Ba
加载人类活动识别数据。该数据包含从佩戴在身上的智能手机获得的7个时间序列传感器数据。每个序列有三个特征,长度不同。这三个特征对应于加速度计在三个不同方向的读数。6个序列用于训练,1个序列用于训练后的测试。GydF4y2Ba
s =负载(GydF4y2Ba“HumanActivityTrain.mat”GydF4y2Ba);GydF4y2Ba
创建GydF4y2BaarrayDatastoreGydF4y2Ba对象,并使用GydF4y2Ba结合GydF4y2Ba函数。GydF4y2Ba
dsXTrain=arrayDatastore(s.XTrain,GydF4y2Ba“OutputType”GydF4y2Ba,GydF4y2Ba“相同”GydF4y2Ba);dsYTrain = arrayDatastore (s。YTrain,GydF4y2Ba“OutputType”GydF4y2Ba,GydF4y2Ba“相同”GydF4y2Ba);dsTrain=联合收割机(dsXTrain,dsYTrain);GydF4y2Ba
查看培训数据中的观察次数。GydF4y2Ba
numObservations=numel(s.XTrain)GydF4y2Ba
numObservations = 6GydF4y2Ba
查看培训数据中的课程数。GydF4y2Ba
类=类别(s.YTrain {1});numClasses =元素个数(类)GydF4y2Ba
numclass=5GydF4y2Ba
在绘图中可视化其中一个训练序列。绘制第一个培训序列和相应活动的特征。GydF4y2Ba
数字GydF4y2Ba为GydF4y2Bai = 1:3 X = s.XTrain{1}(i,:);次要情节(4 1 i)情节(X) ylabel (GydF4y2Ba“功能”GydF4y2Ba+ I + newline +GydF4y2Ba“加速”GydF4y2Ba)GydF4y2Ba结束GydF4y2Ba次要情节(4,4)GydF4y2Ba在GydF4y2Ba情节(s.YTrain {1})GydF4y2Ba从GydF4y2Baxlabel(GydF4y2Ba“时间步”GydF4y2Ba) ylabel (GydF4y2Ba“活动”GydF4y2Ba次要情节(4 1 1)标题(GydF4y2Ba“训练序列1”GydF4y2Ba)GydF4y2Ba

定义深度学习模型GydF4y2Ba
时间卷积网络的主要组成部分是一个扩展的因果卷积层,它在每个序列的时间步骤上进行操作。在这种情况下,“因果”意味着为特定时间步计算的激活不能依赖于未来时间步的激活。GydF4y2Ba
为了从以前的时间步建立上下文,多个卷积层通常堆叠在彼此的顶部。为了获得较大的感受野大小,后续卷积层的膨胀因子按指数增加,如下图所示。假设第k个卷积层的膨胀因子为GydF4y2Ba 而步幅为1,则该网络的接受域大小可计算为GydF4y2Ba 哪里GydF4y2Ba 过滤器的大小和GydF4y2Ba 为卷积层的数量。改变过滤器的大小和层数,以方便地调整接收字段的大小和数量或可学习的参数为必要的数据和手头的任务。GydF4y2Ba
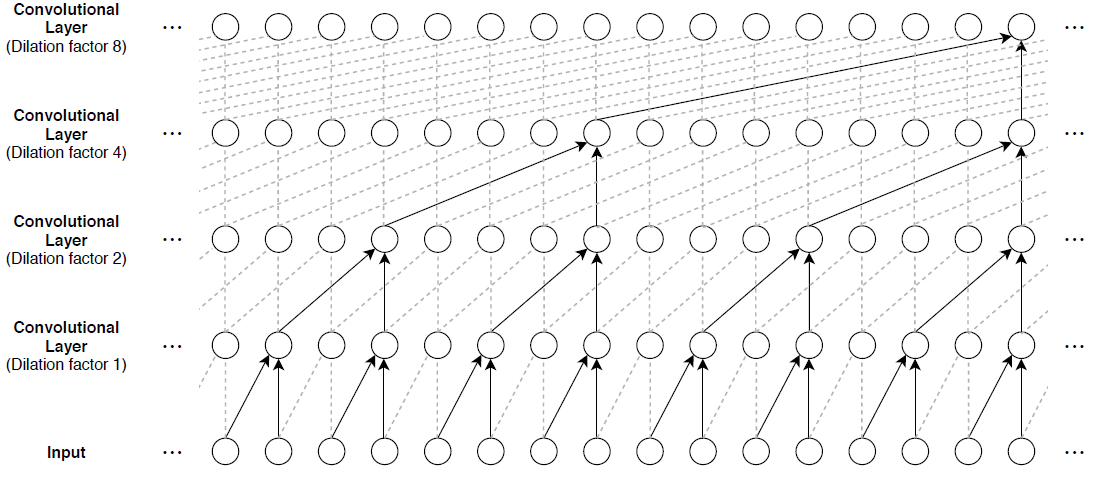
与rnn相比,tcn的缺点之一是推断时占用的内存更多。整个原始序列需要计算下一个时间步长。为了减少推理时间和记忆消耗,特别是对于超前预测,用最小的感觉接受域进行训练是有益的GydF4y2Ba 只对最后一个进行预测GydF4y2Ba 输入序列的时间步长。GydF4y2Ba
一般TCN体系结构(如[1]所述)由多个剩余块组成,每个剩余块包含两组具有相同扩展因子的扩展因果卷积层,然后是归一化、ReLU激活和空间丢失层。每个块的输入被添加到块的输出(包括当输入和输出之间的通道数不匹配时输入上的1×1卷积)和应用最终激活函数。GydF4y2Ba

定义和初始化模型参数GydF4y2Ba
为TCN架构指定参数,该架构有4个残余块,其中包含扩展的因果卷积层,每个层有175个大小为3的滤波器。GydF4y2Ba
numBlocks=4;numFilters=175;filterSize=3;dropoutFactor=0.05;GydF4y2Ba
要将模型超参数传递给模型函数(块的数量和退出因子),创建一个包含这些值的结构。GydF4y2Ba
hyperparameters=struct;hyperparameters.NumBlocks=NumBlocks;hyperparameters.DropOutActor=DropOutActor;GydF4y2Ba
创建一个包含GydF4y2BadlarrayGydF4y2Ba对象用于模型的所有可学习参数,这些参数基于输入通道的数量和定义模型体系结构的超参数。每个残差块都需要两个卷积运算的权值参数和偏差参数。第一个剩余块通常还需要一个滤波器大小为1的额外卷积操作的权重和偏差。最后的全连通操作也需要一个权值和偏置参数。初始化可学习层权重和偏差使用GydF4y2BainitializeGaussianGydF4y2Ba和GydF4y2Ba草签GydF4y2Ba函数,分别。这些函数作为支持文件附加到本示例中。金宝appGydF4y2Ba
numInputChannels = 3;参数=结构;numChannels = numInputChannels;μ= 0;σ= 0.01;GydF4y2Ba为GydF4y2Bak = 1:numBlocks parametersBlock = struct;blockName =GydF4y2Ba“块”GydF4y2Ba+ k;GydF4y2Ba%一维卷积。GydF4y2Basz = [filterSize numChannels numFilters];parametersBlock.Conv1。重量= initializeGaussian (sz、μ、σ);parametersBlock.Conv1。Bias = initializeZeros([numFilters 1]);GydF4y2Ba%一维卷积。GydF4y2Basz = [filterSize numFilters numFilters];parametersBlock.Conv2。重量= initializeGaussian (sz、μ、σ);parametersBlock.Conv2。Bias = initializeZeros([numFilters 1]);GydF4y2Ba%如果块的输入和输出有不同的数量GydF4y2Ba%通道,然后添加一个滤波大小为1的卷积。GydF4y2Ba如果GydF4y2BanumChannels~=numFiltersGydF4y2Ba%一维卷积。GydF4y2Basz = [1 numChannels numFilters];parametersBlock.Conv3。重量= initializeGaussian (sz、μ、σ);parametersBlock.Conv3。Bias = initializeZeros([numFilters 1]);GydF4y2Ba结束GydF4y2BanumChannels = numFilters;参数。(blockName) = parametersBlock;GydF4y2Ba结束GydF4y2Ba%完全连接。GydF4y2Basz=[numclass-numChannels];parameters.FC.Weights=initializeGaussian(sz,mu,sigma);parameters.FC.Bias=initializezezeros([numclass-1]);GydF4y2Ba
查看网络参数。GydF4y2Ba
参数GydF4y2Ba
参数=GydF4y2Ba结构体字段:GydF4y2BaBlock1: [1×1 struct] Block2: [1×1 struct] Block3: [1×1 struct] Block4: [1×1 struct] FC: [1×1 struct]GydF4y2Ba
查看第一个块的参数。GydF4y2Ba
参数。Block1GydF4y2Ba
ans =GydF4y2Ba结构体字段:GydF4y2BaConv1: [1×1 struct] Conv2: [1×1 struct] Conv3: [1×1 struct]GydF4y2Ba
查看第一个块的第一个卷积运算的参数。GydF4y2Ba
parameters.Block1.Conv1GydF4y2Ba
ans =GydF4y2Ba结构体字段:GydF4y2Ba权重:[3×3×175 dlarray]偏见:[175×1 dlarray]GydF4y2Ba
定义模型和模型渐变函数GydF4y2Ba
创建函数GydF4y2Ba模型GydF4y2Ba,列於GydF4y2Ba模型函数GydF4y2Ba部分,计算深度学习模型的输出。这个函数GydF4y2Ba模型GydF4y2Ba获取输入数据、可学习模型参数、模型超参数和一个标志,该标志指定模型是否应返回用于训练或预测的输出。网络在输入序列的每个时间步输出标签的预测。GydF4y2Ba
创建函数GydF4y2Ba模型梯度GydF4y2Ba,列於GydF4y2Ba模型梯度函数GydF4y2Ba部分,该部分取一小批输入数据、相应的目标序列和网络的参数,并返回相对于可学习参数和相应损失的梯度。GydF4y2Ba
指定培训选项GydF4y2Ba
指定自定义训练循环中使用的一组训练选项。GydF4y2Ba
训练30个时代的小批量1。GydF4y2Ba
以0.001的初始学习率开始GydF4y2Ba
每12个时代将学习率乘以0.1。GydF4y2Ba
剪贴渐变使用GydF4y2Ba 阈值为1的范数。GydF4y2Ba
maxEpochs = 30;miniBatchSize = 1;initialLearnRate = 0.001;learnRateDropFactor = 0.1;learnRateDropPeriod = 12;gradientThreshold = 1;GydF4y2Ba
为了监控培训进度,您可以在每次迭代之后绘制培训损失图。创建一个变量GydF4y2Ba情节GydF4y2Ba包含GydF4y2Ba“训练进步”GydF4y2Ba.如果不想绘制训练进度,则将此值设置为GydF4y2Ba“没有”GydF4y2Ba.GydF4y2Ba
阴谋=GydF4y2Ba“训练进步”GydF4y2Ba;GydF4y2Ba
火车模型GydF4y2Ba
通过在训练数据集中的序列上循环,计算参数梯度,并通过Adam更新规则更新网络参数,通过随机梯度下降训练网络。这个过程重复多次(称为GydF4y2Ba时代GydF4y2Ba)直到训练收敛并达到最大历元数。GydF4y2Ba
使用GydF4y2BaminibatchqueueGydF4y2Ba在培训期间处理和管理小批量图像。对于每个小批量:GydF4y2Ba
使用自定义的小批量预处理功能对数据进行预处理GydF4y2Ba
预处理小批量GydF4y2Ba(在本例的最后定义),它返回填充的预测器、填充的一次性编码目标和填充掩码。函数有三个输出,因此指定三个输出变量GydF4y2BaminibatchqueueGydF4y2Ba对象。GydF4y2Ba将输出转换为GydF4y2Ba
dlarrayGydF4y2Ba对象与格式GydF4y2Ba“施”GydF4y2Ba(频道、时间、批次)GydF4y2BaminibatchqueueGydF4y2Ba对象,默认情况下,输出具有底层类型的数据GydF4y2Ba单GydF4y2Ba.GydF4y2Ba如果GPU可用,则在GPU上进行训练GydF4y2Ba
minibatchqueueGydF4y2Ba对象,默认情况下,将每个输出转换为GydF4y2BagpuArrayGydF4y2Ba如果有可用的GPU。使用GPU需要并行计算工具箱™和支持CUDA®的NVIDIA®GPU。有关更多信息,请参见GydF4y2BaGPU版金宝app本支持GydF4y2Ba(并行计算工具箱)GydF4y2Ba.GydF4y2Ba
numDatastoreOutputs = 3;兆贝可= minibatchqueue (dsTrain numDatastoreOutputs,GydF4y2Ba...GydF4y2Ba“MiniBatchSize”GydF4y2Ba,小批量,GydF4y2Ba...GydF4y2Ba“MiniBatchFormat”GydF4y2Ba, {GydF4y2Ba“施”GydF4y2Ba,GydF4y2Ba“施”GydF4y2Ba,GydF4y2Ba“施”GydF4y2Ba},GydF4y2Ba...GydF4y2Ba“MiniBatchFcn”GydF4y2Ba, @preprocessMiniBatch);GydF4y2Ba
对于每个历元,洗牌训练数据。对于每个小批量:GydF4y2Ba
评估模型梯度和损失使用GydF4y2Ba
dlfevalGydF4y2Ba和GydF4y2Ba模型梯度GydF4y2Ba函数。GydF4y2Ba使用该函数剪裁任何较大的渐变GydF4y2Ba
thresholdL2NormGydF4y2Ba,列在示例的最后,以及GydF4y2Ba数据更新GydF4y2Ba函数。GydF4y2Ba使用GydF4y2Ba
阿达木酯GydF4y2Ba函数。GydF4y2Ba更新培训进度图。GydF4y2Ba
完成后GydF4y2BalearnRateDropPeriodGydF4y2Baepoch,通过将当前的学习速率乘以来降低学习速率GydF4y2BalearnRateDropFactorGydF4y2Ba.GydF4y2Ba
初始化学习速率,该速率将乘以GydF4y2BaLearnRateDropFactorGydF4y2Ba重视每一个GydF4y2BaLearnRateDropPeriodGydF4y2Ba时代。GydF4y2Ba
learnRate = initialLearnRate;GydF4y2Ba
初始化参数梯度的移动平均值和Adam优化器使用的梯度的元素平方。GydF4y2Ba
trailingAvg=[];trailingAvgSq=[];GydF4y2Ba
初始化显示培训进度的绘图。GydF4y2Ba
如果GydF4y2Ba情节= =GydF4y2Ba“训练进步”GydF4y2Bafigure lineosstrain = animatedline(GydF4y2Ba“颜色”GydF4y2Ba[0.85 0.325 0.098]);ylim([0正])包含(GydF4y2Ba“迭代”GydF4y2Ba) ylabel (GydF4y2Ba“损失”GydF4y2Ba)网格GydF4y2Ba在GydF4y2Ba结束GydF4y2Ba
训练模型。GydF4y2Ba
迭代=0;开始=tic;GydF4y2Ba%循环纪元。GydF4y2Ba为GydF4y2Ba历元=1:maxEpochsGydF4y2Ba%洗牌数据。GydF4y2Ba洗牌(兆贝可)GydF4y2Ba%循环小批。GydF4y2Ba而GydF4y2Bahasdata(mbq)iteration=iteration+1;[dlX,dlY,mask]=next(mbq);GydF4y2Ba%使用dlfeval评估模型梯度和损失。GydF4y2Ba[梯度,损失]=dlfeval(@modelGradients,parameters,hyperparameters,dlX,dlY,mask);GydF4y2Ba%剪辑渐变。GydF4y2Ba梯度=dlupdate(@(g)阈值L2norm(g,梯度阈值),梯度);GydF4y2Ba%使用Adam优化器更新网络参数。GydF4y2Ba[参数,trailingAvg,trailingAvgSq]=数据更新(参数,梯度,GydF4y2Ba...GydF4y2BatrailingAvg, trailingAvgSq, iteration, learnRate);GydF4y2Ba如果GydF4y2Ba情节= =GydF4y2Ba“训练进步”GydF4y2Ba%标出训练进度。GydF4y2BaD =持续时间(0,0,toc(开始),GydF4y2Ba“格式”GydF4y2Ba,GydF4y2Ba“hh: mm: ss”GydF4y2Ba);GydF4y2Ba将序列长度上的损失归一化GydF4y2BanumTimeSteps =总和(面具(1::),3);loss = mean(loss ./ numTimeSteps);损失=双(收集(extractdata(损失)));=意味着损失(损失);addpoints (lineLossTrain,迭代,损失);标题(GydF4y2Ba”时代:“GydF4y2Ba+时代+GydF4y2Ba,已过:GydF4y2Ba+ drawnow字符串(D))GydF4y2Ba结束GydF4y2Ba结束GydF4y2Ba%减少learnRateDropPeriod时代后的学习率GydF4y2Ba如果GydF4y2Bamod(历元,learnRateDropPeriod)=0 learnRate=learnRate*learnRateDropFactor;GydF4y2Ba结束GydF4y2Ba结束GydF4y2Ba

测试模型GydF4y2Ba
通过比较每个时间步的真实标签在保留测试集上的预测来检验模型的分类精度。GydF4y2Ba
创建一个包含测试预测器的数据存储。GydF4y2Ba
s =负载(GydF4y2Ba“HumanActivityTest.mat”GydF4y2Ba);dsXTest = arrayDatastore (s。XTest,GydF4y2Ba“OutputType”GydF4y2Ba,GydF4y2Ba“相同”GydF4y2Ba);GydF4y2Ba
培训后,对新数据进行预测不需要标签。创建GydF4y2BaminibatchqueueGydF4y2Ba对象,仅包含测试数据的预测器:GydF4y2Ba
要忽略测试标签,请将小批量队列的输出数设置为1。GydF4y2Ba
指定用于培训的相同小批量。GydF4y2Ba
的预处理预测器GydF4y2Ba
preprocessMiniBatchPredictorsGydF4y2Ba函数,列在示例末尾。GydF4y2Ba对于数据存储的单个输出,指定mini-batch格式GydF4y2Ba
“施”GydF4y2Ba(通道、时间、批次)。GydF4y2Ba
numDatastoreOutputs=1;mbqTest=minibatchqueue(dsXTest、numDatastoreOutputs、,GydF4y2Ba...GydF4y2Ba“MiniBatchSize”GydF4y2Ba,小批量,GydF4y2Ba...GydF4y2Ba“MiniBatchFormat”GydF4y2Ba,GydF4y2Ba“施”GydF4y2Ba,GydF4y2Ba...GydF4y2Ba“MiniBatchFcn”GydF4y2Ba,@预测因子);GydF4y2Ba
循环使用小批量并对序列进行分类GydF4y2Ba模型预测GydF4y2Ba函数,列在示例末尾。GydF4y2Ba
预测=模型预测(参数、超参数、mbqTest、类);GydF4y2Ba
通过将预测结果与测试标签进行比较来评估分类的准确性。GydF4y2Ba
欧美= s.YTest {1};精度=平均值(预测== YTest)GydF4y2Ba
精度= 0.9996GydF4y2Ba
将测试序列可视化,并将预测结果与相应的测试数据进行比较。GydF4y2Ba
数字GydF4y2Ba为GydF4y2Bai=1:3x=s.XTest{1}(i,:);子地块(4,1,i)绘图(X)ylabel(GydF4y2Ba“功能”GydF4y2Ba+ I + newline +GydF4y2Ba“加速”GydF4y2Ba)GydF4y2Ba结束GydF4y2BaSubplot (4,1,4) idx = 1;图(预测(idx:)GydF4y2Ba“。”GydF4y2Ba)举行GydF4y2Ba在GydF4y2Ba绘图(Y测试(idx,:))保持GydF4y2Ba从GydF4y2Baxlabel(GydF4y2Ba“时间步”GydF4y2Ba) ylabel (GydF4y2Ba“活动”GydF4y2Ba)传奇([GydF4y2Ba“预测”GydF4y2Ba“测试数据”GydF4y2Ba],GydF4y2Ba“位置”GydF4y2Ba,GydF4y2Ba“东北”GydF4y2Ba次要情节(4 1 1)标题(GydF4y2Ba“测试序列”GydF4y2Ba)GydF4y2Ba

模型函数GydF4y2Ba
这个函数GydF4y2Ba模型GydF4y2Ba,载于GydF4y2Ba定义模型和模型渐变函数GydF4y2Ba在示例部分,将模型参数和超参数作为输入,输入数据GydF4y2BadlXGydF4y2Ba,以及国旗GydF4y2BadoTrainingGydF4y2Ba它指定模型应该返回用于训练还是预测的输出。网络在输入序列的每个时间步长输出标签的预测。该模型由多个膨胀系数呈指数增长的残余块体组成。最后残块后,进行最后一次GydF4y2BafullyconnectGydF4y2Ba操作将输出映射到目标数据中的类数量。模型函数使用GydF4y2Ba剩余块GydF4y2Ba函数的GydF4y2Ba剩余块功能GydF4y2Ba示例的第三部分。GydF4y2Ba
函数GydF4y2Bad = model(参数,超参数,dlX,doTraining) numBlocks = hyperparameters. numBlocks;dropoutFactor = hyperparameters.DropoutFactor;dlY=dlX;GydF4y2Ba%残块。GydF4y2Ba为GydF4y2Bak = 1:numBlocks dilationFactor = 2^(k-1);parametersBlock =参数。(GydF4y2Ba“块”GydF4y2Ba+ k);海底= residualBlock(海底,dilationFactor、dropoutFactor parametersBlock, doTraining);GydF4y2Ba结束GydF4y2Ba%完全连接GydF4y2Ba权重=parameters.FC.weights;bias=parameters.FC.bias;dlY=完全连接(dlY,权重,bias);GydF4y2Ba% Softmax。GydF4y2Ba海底= softmax(海底);GydF4y2Ba结束GydF4y2Ba
剩余块功能GydF4y2Ba
这个函数GydF4y2Ba剩余块GydF4y2Ba实现了时间卷积网络的核心构件。GydF4y2Ba
要应用一维因果扩张卷积,请使用GydF4y2BadlconvGydF4y2Ba功能:GydF4y2Ba
若要在时间维度上进行卷积,请设置GydF4y2Ba
“权重格式”GydF4y2Ba选择GydF4y2Ba“TCU”GydF4y2Ba(时间、渠道不明),GydF4y2Ba设置GydF4y2Ba
“膨胀系数”GydF4y2Ba根据剩余块体的膨胀系数选择。GydF4y2Ba要确保只使用过去的时间步骤,只需在序列的开始处应用填充。GydF4y2Ba
函数GydF4y2Ba海底= residualBlock (dlX dilationFactor、dropoutFactor parametersBlock, doTraining)GydF4y2Ba%卷积选项。GydF4y2BafilterSize =大小(parametersBlock.Conv1.Weights, 1);paddingSize = (filterSize - 1) *膨胀因子;GydF4y2Ba%卷积。GydF4y2Ba权重=参数sblock.Conv1.weights;偏差=参数sblock.Conv1.bias;dlY=dlconv(dlX,权重,偏差,GydF4y2Ba...GydF4y2Ba“权重格式”GydF4y2Ba,GydF4y2Ba“TCU”GydF4y2Ba,GydF4y2Ba...GydF4y2Ba“膨胀系数”GydF4y2BadilationFactor,GydF4y2Ba...GydF4y2Ba“填充”GydF4y2Ba,[paddingSize;0]);GydF4y2Ba%正常化。GydF4y2Badim=查找(dims(dlY)==GydF4y2Ba“T”GydF4y2Ba);μ=意味着(海底、暗);sigmaSq = var(海底1暗);ε= 1 e-5;d = (d - mu) ./√(sigmaSq +);GydF4y2Ba%空间辍学。GydF4y2Ba海底= relu(海底);海底= spatialDropout(海底,dropoutFactor doTraining);GydF4y2Ba%卷积。GydF4y2Ba权重=参数block.Conv2.weights;偏差=参数block.Conv2.bias;dlY=dlconv(dlY,权重,偏差,GydF4y2Ba...GydF4y2Ba“权重格式”GydF4y2Ba,GydF4y2Ba“TCU”GydF4y2Ba,GydF4y2Ba...GydF4y2Ba“膨胀系数”GydF4y2BadilationFactor,GydF4y2Ba...GydF4y2Ba“填充”GydF4y2Ba, (paddingSize;0]);GydF4y2Ba%正常化。GydF4y2Badim=查找(dims(dlY)==GydF4y2Ba“T”GydF4y2Ba);μ=意味着(海底、暗);sigmaSq = var(海底1暗);ε= 1 e-5;d = (d - mu) ./√(sigmaSq +);GydF4y2Ba%空间辍学。GydF4y2Ba海底= relu(海底);海底= spatialDropout(海底,dropoutFactor doTraining);GydF4y2Ba%可选1 × 1卷积。GydF4y2Ba如果GydF4y2Ba~isequal(size(dlX),size(dlY)) weights = parametersBlock.Conv3.Weights;偏见= parametersBlock.Conv3.Bias;dlX = dlconv (dlX、权重、偏见,GydF4y2Ba“权重格式”GydF4y2Ba,GydF4y2Ba“TCU”GydF4y2Ba);GydF4y2Ba结束GydF4y2Ba%添加和ReLUGydF4y2BadlY = relu(dlX + dlY);GydF4y2Ba结束GydF4y2Ba
模型梯度函数GydF4y2Ba
这个GydF4y2Ba模型梯度GydF4y2Ba函数,在GydF4y2Ba定义模型和模型渐变函数GydF4y2Ba在示例的一节中,将模型参数和超参数作为输入,这是一小批输入数据GydF4y2BadlXGydF4y2Ba,对应的目标序列GydF4y2BadlTGydF4y2Ba,和序列填充掩码,并返回损耗相对于可学习参数和相应损耗的梯度。为了计算掩蔽交叉熵损失,使用GydF4y2Ba“面具”GydF4y2Ba选择的GydF4y2BacrossentropyGydF4y2Ba函数。要计算梯度,请计算GydF4y2Ba模型梯度GydF4y2Ba函数使用GydF4y2BadlfevalGydF4y2Ba在训练循环中起作用。GydF4y2Ba
函数GydF4y2Ba[gradient,loss] = modelGradients(parameters,hyperparameters,dlX,dlT,mask) doTraining = true;海底=模型(参数、hyperparameters dlX doTraining);掩码= stripdims(面具);损失= crossentropy (dlT海底,GydF4y2Ba...GydF4y2Ba“面具”GydF4y2Ba面具GydF4y2Ba...GydF4y2Ba“还原”GydF4y2Ba,GydF4y2Ba“没有”GydF4y2Ba);Loss = sum(Loss,[1 3]);=意味着损失(损失);梯度= dlgradient(损失、参数);GydF4y2Ba结束GydF4y2Ba
模型的预测函数GydF4y2Ba
这个GydF4y2Ba模型预测GydF4y2Ba函数将模型参数和超参数作为输入GydF4y2BaminibatchqueueGydF4y2Ba输入数据的处理GydF4y2Ba兆贝可GydF4y2Ba和网络类,并通过迭代所有数据来计算模型预测GydF4y2BaminibatchqueueGydF4y2Ba对象。函数使用GydF4y2BaonehotdecodeGydF4y2Ba函数查找预测得分最高的类。GydF4y2Ba
函数GydF4y2BadoTraining = false; doTraining = false;预测= [];GydF4y2Ba而GydF4y2Bahasdata(mbq) dlX = next(mbq);dlYPred =模型(参数、hyperparameters dlX doTraining);YPred = onehotdecode (dlYPred类1);预测=[预测;YPred];GydF4y2Ba结束GydF4y2BaPredictions = permute(Predictions,[2 3 1]);GydF4y2Ba结束GydF4y2Ba
空间衰减函数GydF4y2Ba
这个GydF4y2BaspatialDropoutGydF4y2Ba函数对输入执行空间dropout [3]GydF4y2BadlXGydF4y2Ba与尺寸的标签GydF4y2BafmtGydF4y2Ba当GydF4y2BadoTrainingGydF4y2Ba旗帜是GydF4y2Ba真正的GydF4y2Ba.空间丢失会丢失整个通道的输入数据。也就是说,某个通道的所有时间步长都会以GydF4y2Ba衰减因子GydF4y2Ba。通道在批次维度中独立退出。GydF4y2Ba
函数GydF4y2BadlY = spatialDropout(dlX,dropoutFactor,doTraining) fmt = dimms (dlX); / / dlX = dlXGydF4y2Ba如果GydF4y2BadoTraining maskSize=大小(dlX);伪装(ismember)(fmt,GydF4y2Ba“圣”GydF4y2Ba)) = 1;dropoutScaleFactor = single(1 - dropoutFactor);dropoutMask =(兰德(maskSizeGydF4y2Ba“喜欢”GydF4y2BadropoutFactor) / dropoutScaleFactor;dlY = dlX .* dropoutMask;GydF4y2Ba其他的GydF4y2BadlY=dlX;GydF4y2Ba结束GydF4y2Ba结束GydF4y2Ba
小批量预处理函数GydF4y2Ba
这个GydF4y2Ba预处理小批量GydF4y2Ba函数对训练数据进行预处理。函数将输入序列转换为左填充一维序列的数字数组,并返回填充掩码。GydF4y2Ba
这个GydF4y2Ba预处理小批量GydF4y2Ba函数使用以下步骤对数据进行预处理:GydF4y2Ba
的预处理预测器GydF4y2Ba
preprocessMiniBatchPredictorsGydF4y2Ba函数/。GydF4y2Ba一次性将每个时间步骤的分类标签编码到数字数组中。GydF4y2Ba
将序列填充到与小批量中最长序列相同的长度,使用GydF4y2Ba
焊盘序列GydF4y2Ba函数GydF4y2Ba
函数GydF4y2Ba[XTTransformed,Y Transformed,mask]=预处理小批量(XCell,YCell)XTTransformed=预处理小批量预测器(XCell);miniBatchSize=numel(XCell);响应=单元(1,miniBatchSize);GydF4y2Ba为GydF4y2Bai=1:miniBatchSize响应{i}=onehotcode(YCell{i},1);GydF4y2Ba结束GydF4y2Ba[YTransformed,面具]= padsequences(反应2GydF4y2Ba“方向”GydF4y2Ba,GydF4y2Ba“左”GydF4y2Ba);GydF4y2Ba结束GydF4y2Ba
小批量预测器预处理功能GydF4y2Ba
这个GydF4y2BapreprocessMiniBatchPredictorsGydF4y2Ba函数对一小批预测器进行预处理,方法是从输入单元格数组中提取序列数据,并将它们左填充以使其具有相同的长度。GydF4y2Ba
函数GydF4y2Baxtransform = preprocessMiniBatchPredictors(XCell)GydF4y2Ba“方向”GydF4y2Ba,GydF4y2Ba“左”GydF4y2Ba);GydF4y2Ba结束GydF4y2Ba
梯度剪切功能GydF4y2Ba
这个GydF4y2BathresholdL2NormGydF4y2Ba函数缩放梯度GydF4y2BaGGydF4y2Ba因此,其GydF4y2Ba
范数等于GydF4y2BagradientThresholdGydF4y2Ba当GydF4y2Ba
梯度的范数大于GydF4y2BagradientThresholdGydF4y2Ba.GydF4y2Ba
函数GydF4y2Bag = thresholdL2Norm(g,gradientThreshold)GydF4y2Ba“所有”GydF4y2Ba));GydF4y2Ba如果GydF4y2BagradientNorm > gradientThreshold g = g * (gradientThreshold / gradientNorm);GydF4y2Ba结束GydF4y2Ba结束GydF4y2Ba
工具书类GydF4y2Ba
[1] Bai,Shaojie,J.Zico Kolter和Vladlen Koltun.“用于序列建模的通用卷积和递归网络的经验评估。”GydF4y2BaarXiv预印本arXiv: 1803.01271GydF4y2Ba(2018)。GydF4y2Ba
[2] Van Den Oord, Aäron,等。WaveNet:原始音频的生成模型。GydF4y2Ba量GydF4y2Ba125(2016)。GydF4y2Ba
[3] thompson, Jonathan等。“利用卷积网络进行有效的目标定位。”GydF4y2BaIEEE计算机视觉和模式识别会议记录GydF4y2Ba. 2015.GydF4y2Ba
另见GydF4y2Ba
阿达木酯GydF4y2Ba|GydF4y2BacrossentropyGydF4y2Ba|GydF4y2BadlarrayGydF4y2Ba|GydF4y2BadlconvGydF4y2Ba|GydF4y2BadlfevalGydF4y2Ba|GydF4y2BadlgradientGydF4y2Ba|GydF4y2BafullyconnectGydF4y2Ba|GydF4y2BaminibatchqueueGydF4y2Ba|GydF4y2BaonehotdecodeGydF4y2Ba|GydF4y2BaonehotencodeGydF4y2Ba|GydF4y2Ba线性整流函数(Rectified Linear Unit)GydF4y2Ba|GydF4y2BasoftmaxGydF4y2Ba
相关的话题GydF4y2Ba
选择网站GydF4y2Ba
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:GydF4y2Ba.GydF4y2Ba
选择GydF4y2Ba网站GydF4y2Ba你也可以从以下列表中选择一个网站:GydF4y2Ba
美洲GydF4y2Ba
- 拉丁美洲美洲GydF4y2Ba(西班牙语)GydF4y2Ba
- 加拿大GydF4y2Ba(英文)GydF4y2Ba
- 美国GydF4y2Ba(英文)GydF4y2Ba
欧洲GydF4y2Ba
- 比利时GydF4y2Ba(英文)GydF4y2Ba
- 丹麦GydF4y2Ba(英文)GydF4y2Ba
- 德国GydF4y2Ba(德语)GydF4y2Ba
- 西班牙GydF4y2Ba(西班牙语)GydF4y2Ba
- 芬兰GydF4y2Ba(英文)GydF4y2Ba
- 法国GydF4y2Ba(法兰西)GydF4y2Ba
- 爱尔兰GydF4y2Ba(英文)GydF4y2Ba
- 意大利GydF4y2Ba(意大利语)GydF4y2Ba
- 卢森堡GydF4y2Ba(英文)GydF4y2Ba
- 荷兰GydF4y2Ba(英文)GydF4y2Ba
- 挪威GydF4y2Ba(英文)GydF4y2Ba
- ÖsterreichGydF4y2Ba(德语)GydF4y2Ba
- 葡萄牙GydF4y2Ba(英文)GydF4y2Ba
- 瑞典GydF4y2Ba(英文)GydF4y2Ba
- 瑞士GydF4y2Ba
- 大不列颠联合王国GydF4y2Ba(英文)GydF4y2Ba
亚太地区GydF4y2Ba
- 澳大利亚GydF4y2Ba(英文)GydF4y2Ba
- 印度GydF4y2Ba(英文)GydF4y2Ba
- 新西兰GydF4y2Ba(英文)GydF4y2Ba
- 中国GydF4y2Ba
- 日本GydF4y2Ba(日本語)GydF4y2Ba
- 한국GydF4y2Ba(한국어)GydF4y2Ba
