基于深度学习的语音指令识别
这个例子显示了如何培养检测音频语音命令的存在深刻的学习模式。该示例使用语音命令数据集[1]来训练卷积神经网络识别一组给定的命令。
要从头开始训练网络,必须首先下载数据集。如果您不想下载数据集或训练网络,那么您可以加载本示例提供的预先训练的网络,并执行示例的下两个部分:通过预先训练的网络识别命令和使用麦克风中的流音频检测命令.
通过预先训练的网络识别命令
在进入详细的训练过程之前,您将使用预先训练过的语音识别网络来识别语音命令。
加载预先训练的网络。
加载(“commandNet.mat”)
训练网络识别以下语音命令:
“是的”
“不”
“向上”
“向下”
“左”
“正确”
“上”
“离开”
“停止”
“走”
在有人说“停止”的地方加载一个简短的语音信号。
[X,FS] = audioread(“stop_command.flac”);
听命令。
声音(x, fs)
预先训练的网络以基于听觉的谱图作为输入。首先将语音波形转换为基于听觉的声谱图。
使用功能extractAuditoryFeature来计算听觉谱图。在稍后的示例中,您将了解特征提取的细节。
auditorySpect = helperExtractAuditoryFeatures(X,FS);
根据命令的声谱图对其进行分类。
命令=分类(trainedNet auditorySpect)
命令=绝对停止
该网络进行训练不属于该组为“未知”分类的话。
现在您将对命令列表中没有包含的单词(“play”)进行分类以识别。
加载语音信号并收听它。
X = audioread(“play_command.flac”);声音(x, fs)
计算听觉谱图。
auditorySpect = helperExtractAuditoryFeatures(X,FS);
分类的信号。
命令=分类(trainedNet auditorySpect)
命令=分类未知
该网络进行训练分类背景噪音“背景”。
创建由随机噪声的一第二信号。
x = pinknoise (16 e3);
计算听觉谱图。
auditorySpect = helperExtractAuditoryFeatures(X,FS);
对背景噪声进行分类。
命令=分类(trainedNet auditorySpect)
命令=分类背景
使用麦克风中的流音频检测命令
在麦克风的流音频上测试预先训练的命令检测网络。例如,试着说出其中一条命令,是的,不,或停止.然后,试着说出其中一个不认识的单词,比如马文,希拉,床上,房子,猫,鸟,或者从0到9的任何数字。
以Hz为单位指定分类速率,并创建一个音频设备阅读器,该阅读器可以从麦克风读取音频。
classificationRate = 20;adr = audioDeviceReader (“SampleRate”fs,“SamplesPerFrame”、地板(fs / classificationRate));
初始化音频缓冲区。提取网络的分类标签。为流音频的标签和分类概率初始化半秒的缓冲区。使用这些缓冲区来比较较长一段时间内的分类结果,并在检测到命令时构建“一致”。为决策逻辑指定阈值。
audioBuffer = dsp.AsyncBuffer (fs);. class标签= trainedNet.Layers(结束);YBuffer (1: classificationRate / 2) =分类(“背景”);probBuffer =零([numel(标签),classificationRate / 2]);countThreshold =小区(classificationRate * 0.2);probThreshold = 0.7;
只要创建的图形存在,就创建一个图形并检测命令。要无限期地运行循环,请设置时限来正.要停止活检测,只需关闭图形。
h =图(“单位”,“归一化”,“位置”,[0.2 0.1 0.6 0.8]);期限= 20;抽搐尽管句柄(h) && toc < timeLimit%从音频设备中提取音频样本并将样本添加到%的缓冲。x = adr ();写(audioBuffer x);fs, y =阅读(audioBuffer fs-adr.SamplesPerFrame);规范= helperExtractAuditoryFeatures (y, fs);%对当前光谱图进行分类,将标签保存到标签缓冲区,%并保存预测概率的概率缓冲器。[YPredicted,聚合氯化铝]=分类(trainedNet,规范,“ExecutionEnvironment”,“cpu”);YBuffer = [YBuffer(2:结束),YPredicted);probBuffer = [probBuffer(:, 2:结束)、聚合氯化铝(:));%绘制的电流波形和频谱。次要情节(2,1,1)情节(y)轴紧Ylim ([-1,1]) subplot(2,1,2) pcolor(spec') caxis([-4 2.6445])底纹平现在通过执行一个非常简单的命令来进行实际的命令检测%的阈值操作。声明一个检测并将其显示在%数字标题,如果所有以下持有:1)最常见的标签%不是背景。2)至少countThreshold的最新帧%标签一致。3)预测标签的最大概率为at% probThreshold最少。否则,不要声明检测。[YMode,计数] =模式(YBuffer);maxProb = MAX(probBuffer(标签== YMode,:));副区(2,1,1)如果YMode = =“背景”|| count < count threshold || maxprobb < probThreshold title(”“)其他的标题(字符串(YMode)“字形大小”,20)结束drawnow结束
加载语音命令数据集
这个例子使用谷歌语音命令数据集[1]。下载数据集并解压下载的文件。将PathToDatabase设置为数据的位置。
url =“https://ssd.mathworks.com/金宝appsupportfiles/audio/google_speech.zip”;downloadFolder = tempdir;dataFolder = fullfile (downloadFolder,“google_speech”);如果~存在(dataFolder“dir”) disp (“下载数据集(1.4 GB)......”解压缩(url, downloadFolder)结束
创建培训数据存储
创建一个audioDatastore(音频工具箱)指向训练数据集。
广告= audioDatastore (fullfile (dataFolder,'火车'),...'IncludeSubfolders',真的,...“FileExtensions”,“wav”,...'LABELSOURCE',“foldernames”)
ads = audioDatastore与属性:文件:{'…\AppData\Local\Temp\google_speech\train\bed\00176480_nohash_0.wav';’……\ AppData \当地\ Temp \床google_speech \培训\ \ 004 ae714_nohash_0.wav;’……\ AppData \当地\ Temp \床google_speech \培训\ \ 004 ae714_nohash_1.wav……{'C:\Users\jibrahim\AppData\Local\Temp\google_speech\train'}标签:[bed;床上;床上……alteratefilesystemroots: {} OutputDataType: 'double' SupportedOutputFormats: ["wav金宝app" "flac" "ogg" "mp4" "m4a"] DefaultOutputFormat: "wav"
选择要识别的单词
指定您希望模型识别为命令的单词。将所有非命令的单词标记为未知的.未命令,标签字未知的创建一组单词,它近似于除命令之外的所有单词的分布。网络使用这个组来学习命令和所有其他单词之间的区别。
为了减少已知和未知单词之间的类不平衡,加快处理速度,在训练集中只包含一部分未知单词。
使用子集(音频工具箱)创建只包含命令和未知单词子集的数据存储。计算属于每个类别的例子的数量。
命令=分类([“是的”,“不”,“向上”,“向下”,“左”,“正确”,“上”,“离开”,“停止”,“走”]);isCommand = ismember(ads.Labels,命令);isUnknown = ~ isCommand;includeFraction = 0.2;mask = rand(numel(ads.Labels),1) < includeFraction;isUnknown = isUnknown & mask;ads.Labels(isUnknown)=分类(“未知”);adsTrain =子集(广告,isCommand | isUnknown);countEachLabel(adsTrain)
ANS = 11×2表标签数量_______ _____下降1842转到1861年1864年1852年权1885年停止未知的6483离开1839年没有1853年关闭1839年可达1843个是1860
创建验证数据存储
创建一个audioDatastore(音频工具箱)指向验证数据集。按照用于创建数据存储训练相同的步骤。
广告= audioDatastore (fullfile (dataFolder,“验证”),...'IncludeSubfolders',真的,...“FileExtensions”,“wav”,...'LABELSOURCE',“foldernames”) isCommand = ismember(ads.Labels,commands);isUnknown = ~ isCommand;includeFraction = 0.2;mask = rand(numel(ads.Labels),1) < includeFraction;isUnknown = isUnknown & mask;ads.Labels(isUnknown)=分类(“未知”);adsValidation =子集(广告,isCommand | isUnknown);countEachLabel (adsValidation)
广告= audioDatastore与性能:文件:{ '... \应用程序数据\本地的\ Temp \ google_speech \确认\床\ 026290a7_nohash_0.wav';'... \应用程序数据\本地的\ Temp \ google_speech \确认\床\ 060cd039_nohash_0.wav';'... \应用程序数据\本地的\ Temp \ google_speech \确认\床\ 060cd039_nohash_1.wav' ......和6795多}文件夹:{ 'C:\用户\ jibrahim \应用程序数据\本地的\ Temp \ google_speech \验证'}标签:床;床上;床...和6795多个分类] AlternateFileSystemRoots:{} OutputDataType: '双' SupportedOutputFormats:[ “金宝appWAV” “后手” “奥格” “MP4” “M4A”] DefaultOutputFormat: “WAV” ANS = 11×2表标签计数_______ _____下跌264转到260左247没有关闭270 256 257 256右246停止850未知高达260是261
要用整个数据集训练网络,并达到尽可能高的精度,集合reduceDataset来假.要快速运行此示例,请设置reduceDataset来真的.
reduceDataset = false;如果reduceDataset numUniqueLabels = nummel (unique(adsTrain.Labels));%的20倍减少的数据集adsTrain = splitEachLabel(adsTrain,round(numel(adsTrain. files) / numUniqueLabels / 20));adsValidation = splitEachLabel(adsValidation,round(numel(adsValidation. files) / numUniqueLabels / 20));结束
计算听觉谱图
为了准备有效训练卷积神经网络的数据,将语音波形转换为基于听觉的谱图。
定义特征提取的参数。segmentDuration是每个语音剪辑的持续时间(以秒计)。frameDuration是每帧频谱计算的持续时间。hopDuration为每个频谱之间的时间步长。numBands为听觉声谱图中过滤器的数量。
创建一个audioFeatureExtractor(音频工具箱)对象进行特征提取。
fs = 16 e3;%数据集的已知抽样率。segmentDuration = 1;frameDuration = 0.025;hopDuration = 0.010;segmentSamples =圆(segmentDuration * fs);frameSamples =圆(frameDuration * fs);hopSamples =圆(hopDuration * fs);overlapSamples = framessamples - hopSamples;FFTLength = 512;numBands = 50;afe = audioFeatureExtractor (...“SampleRate”fs,...“FFTLength”,FFTLength,...“窗口”损害(frameSamples“周期”),...“OverlapLength”overlapSamples,...“barkSpectrum”,真的);setExtractorParams(AFE,“barkSpectrum”,“NumBands”numBands,“WindowNormalization”,错误的);
从数据集读取文件。训练卷积神经网络需要输入大小一致。数据集中的一些文件长度小于1秒。在音频信号的前面和后面应用零填充,使其具有长度segmentSamples.
x =阅读(adsTrain);numSamples =大小(x, 1);numToPadFront = floor((segmentSamples - numSamples)/2);numToPadBack = cell ((segmentSamples - numSamples)/2);xPadded = 0 (numToPadFront 1“喜欢”, x); x; 0 (numToPadBack 1“喜欢”, x));
要提取音频特征,调用提取.输出是跨行带有时间的Bark谱。
特点=提取(afe xPadded);[numHops, numFeatures] =大小(特性)
numHops = 98 numFeatures = 50
在本例中,通过应用对数对听觉声谱图进行后处理。取小数字的对数会导致四舍五入错误。
要加快处理速度,可以使用parfor.
首先,确定数据集的分区数。如果您没有并行计算工具箱™,请使用单个分区。
如果~ isempty(版本(“平行”)) && ~reduceDataset pool = gcp;numPar = numpartitions (adsTrain、池);其他的numPar = 1;结束
对于每个分区,从数据存储中读取,填充信号零,然后提取特征。
parforii = 1:numPar subds = partition(adsTrain,numPar,ii);XTrain = 0 (numHops numBands 1,元素个数(subds.Files));为idx = 1:numel(subds. files) x = read(subds);xPadded =[0(地板(segmentSamples-size (x, 1)) / 2), 1); x; 0(装天花板((segmentSamples-size (x, 1)) / 2), 1)];XTrain (:,:,:, idx) =提取(afe xPadded);结束XTrainC {2} = XTrain;结束
将输出转换为沿第四维度的听觉光谱图的四维阵列。
XTrain =猫(4,XTrainC {:});[numHops, numBands numChannels numSpec] =大小(XTrain)
numHops = 98 numBands = 50 numChannels = 1 numSpec = 25021
根据窗户功率缩放特征,然后取日志。为了获得分布更平滑的数据,使用小偏移量对谱图取对数。
epsil = 1 e-6;XTrain = log10(XTrain + epsil);
执行上面的验证组中描述的特征提取步骤。
如果~ isempty(版本(“平行”))池= GCP;数参= numpartitions(adsValidation,池);其他的numPar = 1;结束parforii = 1:numPar subds = partition(adsValidation,numPar,ii);XValidation = 0 (numHops numBands 1,元素个数(subds.Files));为idx = 1:numel(subds. files) x = read(subds);xPadded =[0(地板(segmentSamples-size (x, 1)) / 2), 1); x; 0(装天花板((segmentSamples-size (x, 1)) / 2), 1)];XValidation (:,:,:, idx) =提取(afe xPadded);结束XValidationC {2} = XValidation;结束XValidation =猫(4,XValidationC {:});XValidation = log10(XValidation + epsil);
隔离列车和验证标签。删除空的类别。
YTrain = removecats (adsTrain.Labels);YValidation = removecats (adsValidation.Labels);
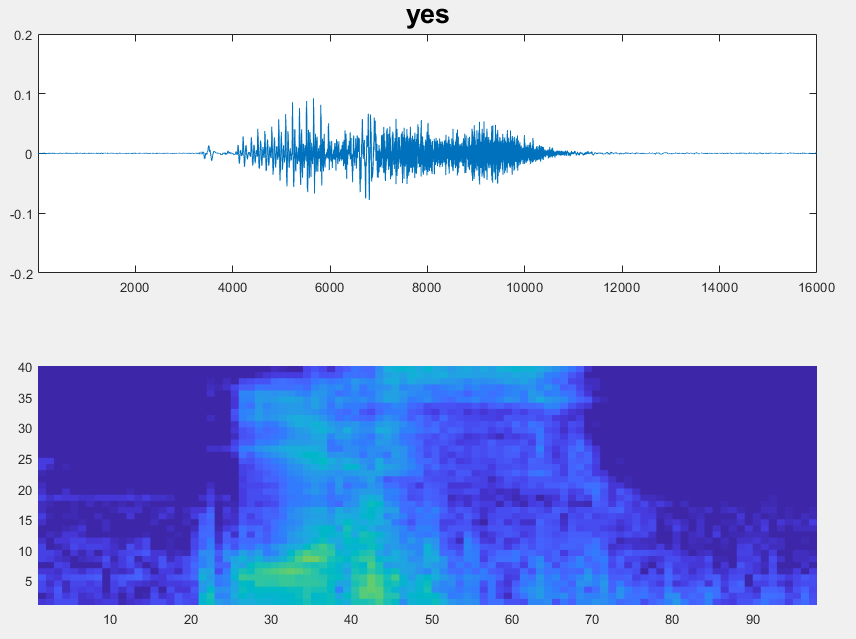
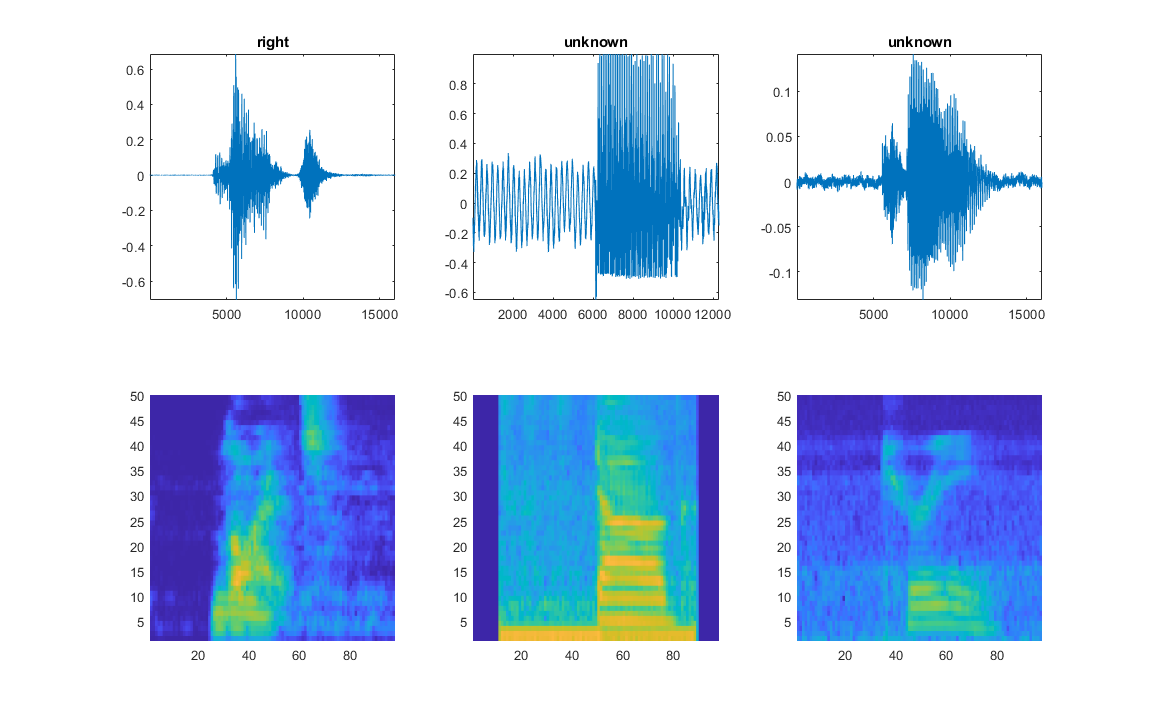
可视化数据
绘制一些训练样本的波形和听觉谱图。播放相应的音频片段。
specMin = min (XTrain [],“所有”);specMax = max (XTrain [],“所有”);idx = randperm(元素个数(adsTrain.Files), 3);图(“单位”,“归一化”,“位置”,[0.2 0.2 0.6 0.6]);为i = 1:3 [x,fs] = audioread(adsTrain.Files{idx(i)});次要情节(2、3、i)情节(x)轴紧标题(string (adsTrain.Labels (idx (i))))次要情节(2 3 i + 3) spect = (XTrain (:,: 1, idx(我)');cxis ([specMin specMax])阴影平声音(x, fs)暂停(2)结束
添加背景噪声数据
该网络不仅要能够识别不同的语音,还必须能够检测输入是否包含沉默或背景噪声。
使用音频文件_background_文件夹创建一秒背景噪音剪辑的样本。从每个背景噪声文件中创建相同数量的背景剪辑。您也可以创建自己的背景噪音录音,并将它们添加到_background_ 文件夹。计算所述频谱之前,将功能重新调整与由下式给出的范围内的数均匀分布采样的因子每个音频剪辑volumeRange.
adsBkg = audioDatastore (fullfile (dataFolder“背景”))numBkgClips = 4000;如果reduceDataset numBkgClips = numBkgClips / 20;结束volumeRange = log10([1的军医,1]);numBkgFiles =元素个数(adsBkg.Files);numClipsPerFile = histcounts (1: numBkgClips, linspace (1 numBkgClips numBkgFiles + 1);Xbkg = 0(大小(XTrain, 1),大小(XTrain, 2), 1, numBkgClips,“单一”);bkgAll = readall (adsBkg);印第安纳州= 1;为数= 1:numBkgFiles BKG = bkgAll {COUNT};idxStart =兰迪(numel(BKG)-fs,numClipsPerFile(计数),1);idxEnd = idxStart + FS-1;增益= 10 ^((volumeRange(2)-volumeRange(1))*兰特(numClipsPerFile(计数),1)+ volumeRange(1))。为j = 1:numClipsPerFile(count) x = bkg(idxStart(j):idxEnd(j)))*gain(j); / /统计x = max (min (x, 1), 1);Xbkg(:,:,:,印第安纳州)=提取(afe x);如果国防部(印第安纳州,1000)= = 0 disp (“加工”(印第安纳州)+ +字符串“背景剪辑退出”+字符串(numBkgClips))结束Ind = Ind + 1;结束结束Xbkg = log10(Xbkg + epsil);
adsBkg = audioDatastore具有属性:文件:{ '... \应用程序数据\本地\ TEMP \ google_speech \背景\ doing_the_dishes.wav';'... \应用程序数据\本地的\ Temp \ google_speech \背景\ dude_miaowing.wav';'... \应用程序数据\本地\ TEMP \ google_speech \背景\ exercise_bike.wav' ...和3更}文件夹:{C:\ Users \用户jibrahim \应用程序数据\本地\ TEMP \ google_speech \背景'} AlternateFileSystemRoots:{} OutputDataType: '双' 标签:{} SupportedO金宝apputputFormats:[ “WAV” “后手” “奥格” “MP4” “M4A”] DefaultOutputFormat: “WAV” 耗时1000个背景剪辑出的4000耗时2000背景剪辑出的4000耗时3000个背景剪辑出的4000加工4000个背景剪辑出来的4000
在训练集、验证集和测试集之间分割背景噪声谱图。因为_背景噪音_文件夹只包含约5分半钟的背景噪声,不同数据集中的背景样本具有高度相关性。为了增加背景噪音的变化,您可以创建自己的背景文件,并将它们添加到文件夹中。为了提高网络对噪声的鲁棒性,您还可以尝试在语音文件中混合背景噪声。
numTrainBkg =地板(0.85 * numBkgClips);numValidationBkg =地板(0.15 * numBkgClips);XTrain(:,:,: + 1:终端+ numTrainBkg) = Xbkg (:,:,:, 1: numTrainBkg);YTrain(+ 1:结束+ numTrainBkg) =“背景”;XValidation(:,:,: + 1:终端+ numValidationBkg) = Xbkg (:,:,:, numTrainBkg + 1:结束);YValidation(+ 1:结束+ numValidationBkg) =“背景”;
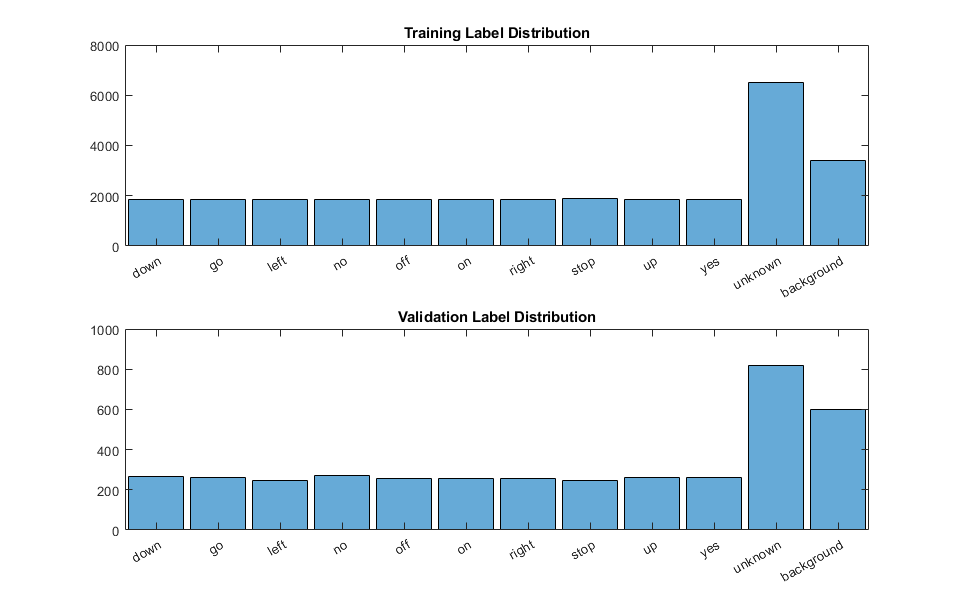
绘制不同类别标签在训练和验证集中的分布。
图(“单位”,“归一化”,“位置”,[0.2 0.2 0.5 0.5]) subplot(2,1,1) histogram(YTrain) title(“培训标签分配”)副区(2,1,2)的直方图(YValidation)标题(“验证标签分配”)
定义神经网络结构
创建一个简单的网络架构,作为一组层。使用卷积和批处理归一化层,并使用最大池化层在“空间上”(即在时间和频率上)对特征映射进行向下采样。添加一个最终的最大池化层,随着时间的推移将输入特征映射全局池化。这在输入谱图中强制了(近似)时间平移不变性,允许网络执行相同的分类,而不依赖于语音在时间上的确切位置。全局池还显著减少了最终完全连接层中的参数数量。为了减少网络记忆训练数据的特定特征的可能性,在最后一个完全连接层的输入中添加少量的dropout。
这个网络很小,因为它只有五个卷积层和几个过滤器。numF控制卷积层中的过滤器数量。为了提高网络的准确性,尝试通过添加相同的卷积块、批处理归一化块和ReLU层来增加网络深度。你也可以通过增加来增加卷积滤波器的数量numF.
使用加权交叉熵分类的损失。weightedClassificationLayer (classWeights)创建一个自定义分类层,计算交叉熵损失与观测加权classWeights.按照类出现的顺序指定类权重类别(YTrain).为了使每个类在损失中具有相等的总权重,使用与每个类中的训练示例数量成反比的类权重。使用Adam优化器训练网络时,训练算法独立于类权值的整体归一化。
classWeights = 1./countcats(YTrain);classWeights = classWeights' /平均值(classWeights);numClasses = numel(类别(YTrain));timePoolSize =小区(numHops / 8);dropoutProb = 0.2;numF = 12;层= [imageInputLayer([numHops numBands])convolution2dLayer(3,numF,“填充”,'相同的'maxPooling2dLayer(3,“步”2,“填充”,'相同的') convolution2dLayer (3 2 * numF“填充”,'相同的'maxPooling2dLayer(3,“步”2,“填充”,'相同的') convolution2dLayer(3、4 * numF,“填充”,'相同的'maxPooling2dLayer(3,“步”2,“填充”,'相同的') convolution2dLayer(3、4 * numF,“填充”,'相同的') batchNormalizationLayer reluLayer卷积2dlayer (3,4*numF,“填充”,'相同的') batchNormalizationLayer reluLayer maxPooling2dLayer([timePoolSize,1]) dropoutLayer(dropoutProb) fulllyconnectedlayer (numClasses) softmaxLayer weightedClassificationLayer(classWeights)];
列车网络的
指定培训选项。使用Adam优化器,迷你批量大小为128。训练25个周期,20个周期后学习率降低10倍。
miniBatchSize = 128;validationFrequency =地板(元素个数(YTrain) / miniBatchSize);选择= trainingOptions (“亚当”,...“InitialLearnRate”3的军医,...'maxepochs'25岁的...“MiniBatchSize”miniBatchSize,...“洗牌”,“每个历元”,...“阴谋”,“训练进步”,...“详细”,错误的,...'ValidationData'{XValidation, YValidation},...'ValidationFrequency'validationFrequency,...“LearnRateSchedule”,“分段”,...“LearnRateDropFactor”, 0.1,...'学习ropperiod', 20);
培训网络。如果你没有GPU,那么训练网络可能会花费一些时间。
trainedNet = trainNetwork (XTrain、YTrain层,选择);
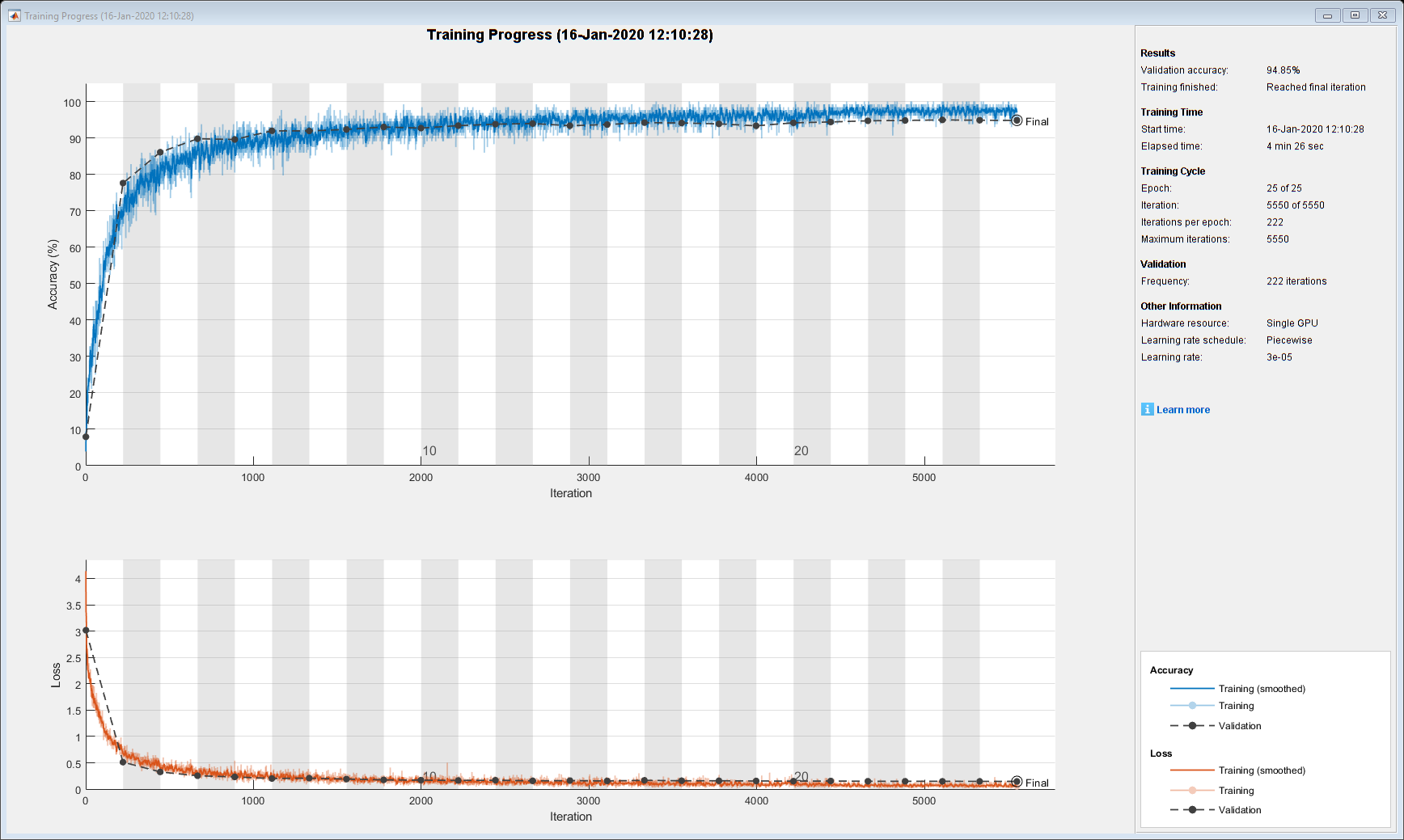
评估培训网络
计算网络在训练集(无数据增强)和验证集上的最终精度。这个网络对这个数据集非常精确。然而,培训、验证和测试数据都有类似的分布,不一定反映真实环境。这个限制特别适用于未知的类别,它只包含少量单词的话语。
如果reduceDataset负载(“commandNet.mat”,“trainedNet”);结束YValPred =分类(trainedNet XValidation);validationError = mean(YValPred ~= YValidation);YTrainPred =分类(trainedNet XTrain);= mean(YTrainPred ~= YTrain);disp (“训练误差:+ trainError * 100 +“%”) disp ("验证错误:"+ validationError * 100 +“%”)
训练误差:1.907%验证错误:5.5376%
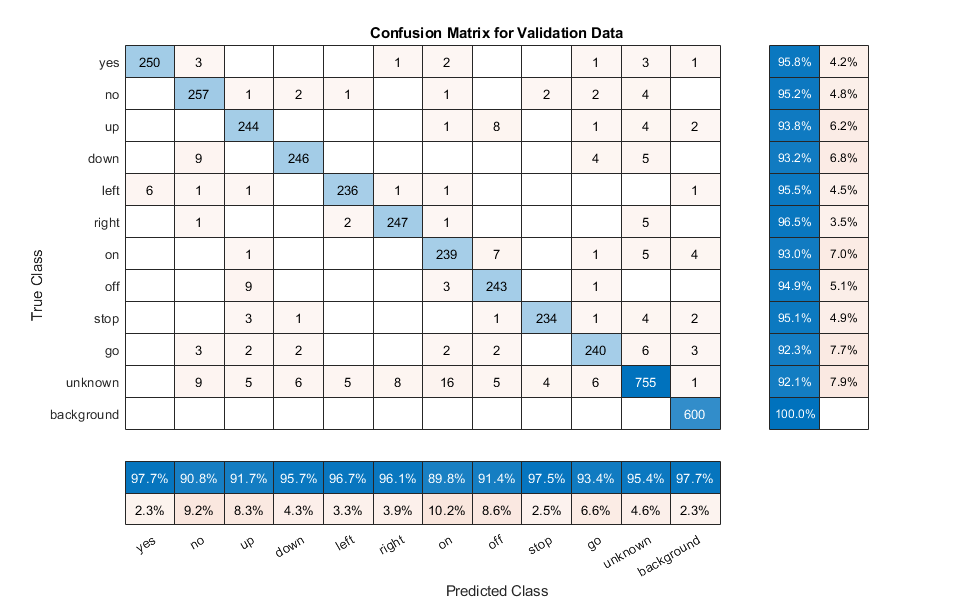
绘制混淆矩阵。通过使用列和行摘要显示每个类的精度和召回率。对混淆矩阵的类进行排序。最大的混淆是在未知的单词和命令之间,向上和从,下来和不, 和去和不.
图(“单位”,“归一化”,“位置”,[0.2 0.2 0.5 0.5]);厘米= confusionchart (YValidation YValPred);厘米。Title =“验证数据的混淆矩阵”;厘米。ColumnSummary =“column-normalized”;厘米。RowSummary =“row-normalized”;sortClasses(厘米,[命令,“未知”,“背景”])
当处理具有受限硬件资源的应用程序(如移动应用程序)时,请考虑可用内存和计算资源的限制。以千字节为单位计算网络的总大小,并在使用CPU时测试其预测速度。预测时间是对单个输入图像进行分类的时间。如果你向网络输入多个图像,这些图像可以同时分类,从而缩短每个图像的预测时间。然而,在对流音频进行分类时,单图像的预测时间是最相关的。
信息=谁(“trainedNet”);disp (“网络大小:”+信息。字节/ 1024 +“知识库”)为i = 1:100 x = randn([numHops,numBands]);tic [YPredicted,probs] = classification(训练网,x,“ExecutionEnvironment”,“cpu”);时间(i) = toc;结束disp (CPU上单图像预测时间:+的意思是(时间(11:结束))* 1000 +“女士”)
网络大小:286.7402 kB CPU上的单张图像预测时间:2.5119 ms
参考文献
[1]监狱长P。“语音指令:单字语音识别的公共数据集”,2017。可以从https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz.版权所有2017年谷歌的语音命令数据集采用知识共享署名4.0许可协议授权,可在这里:https://creativecommons.org/licenses/by/4.0/legalcode.
参考文献
[1]监狱长P。“语音指令:单字语音识别的公共数据集”,2017。可以从http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz.版权所有2017年谷歌的语音命令数据集采用知识共享署名4.0许可协议授权,可在这里:https://creativecommons.org/licenses/by/4.0/legalcode.
另请参阅
trainNetwork|分类|analyzeNetwork
相关话题
您还可以从以下列表中选择一个网站:
