定义文本解码器模型函数
此示例显示如何定义文本解码器模型函数。
在深度学习的背景下,解码器是一个深度学习网络的一部分,其将潜伏向量映射到某些示例空间。您可以使用解码向量进行各种任务。例如,
通过使用编码向量初始化反复化网络来文本生成。
通过使用编码的向量作为上下文向量来序列到序列平移。
使用编码向量作为上下文向量的图像字幕。
加载数据
加载编码数据sonnetsencoded .mat.这个MAT文件包含单词编码,一个小批序列DLX.,以及相应的编码数据DLZ.通过该示例中使用的编码器输出定义文本编码器模型功能.
s = load(“sonnetsencoded.mat”);内附= s.enc;dlX = s.dlX;dlZ = s.dlZ;[latentDimension, miniBatchSize] =大小(dlZ 1:2);
初始化模型参数
解码器的目标是生成给定初始输入数据和网络状态的序列。
初始化以下模型的参数。
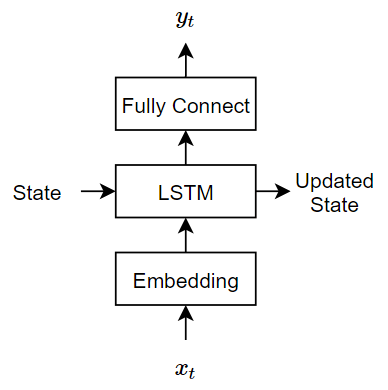
解码器使用LSTM初始化编码器输出来重建输入。对于每个时间步骤,解码器预测下一个时间步长并使用输出进行下一个时间步骤预测。编码器和解码器都使用相同的嵌入。
该模型使用三个操作:
嵌入在范围内的Word Indice映射
词汇对维度的载体embeddingdimension., 在哪里词汇编码词汇中的单词数和embeddingdimension.是嵌入学习的组件数量。LSTM操作用作输入单个单词矢量和输出1-by-
numhidandunits.矢量,在那里numhidandunits.是LSTM操作中隐藏单元的数量。LSTM网络的初始状态(第一个时间步的状态)是编码向量,因此隐藏单元的数量必须与编码器的潜在维数匹配。完全连接的操作将输入乘以权重矩阵添加偏置并输出大小的向量
词汇.
指定参数的尺寸。嵌入大小必须与编码器匹配。
EmbeddingDimension = 100;Vocabularysize = enc.numwords;numhidandunits = latentdimension;
为参数创建结构。
参数= struct;
使用高斯使用高斯初始化嵌入的权重initializeGaussian函数,该函数作为支持文件附加到本例中。金宝app指定0的平均值和0.01的标准偏差。要了解更多信息,请参阅高斯初始化.
mu = 0;sigma = 0.01;parameters.emb.weights = initializegaussian([Embeddingdimensionsize],mu,sigma);
初始化解码器LSTM操作的可读参数:
可学习参数的大小取决于输入的大小。因为LSTM操作的输入是来自嵌入操作的字向量的序列,所以输入通道的数量是embeddingdimension..
输入权重矩阵具有大小
4 * numhidendunits.-经过-输入, 在哪里输入是输入数据的维度。复发重量矩阵具有大小
4 * numhidendunits.-经过-numhidandunits..偏置载体具有尺寸
4 * numhidendunits.-By-1。
sz = [4 * numhidentunits embeddingdimensile];numout = 4 * numhidentunits;numin = embeddingdimension;参数.lstmdecoder.inputwights = initializeglorot(sz,numout,numin);参数.lstmdecoder.recurrentweights = initialize正常([4 * numhidentunits numhidentunits]);参数.lstmdecoder.bias = niginizeUnitForgetgate(numhidentunits);
初始化编码器完全连接操作的可读参数:
使用Glorot Initializer初始化权重。
用零初始化偏差
initializezeros函数,该函数作为支持文件附加到本例中。金宝app要了解更多信息,请参阅零初始化.
可学习参数的大小取决于输入的大小。因为全连接操作的输入是LSTM操作的输出,所以输入通道的数量为numhidandunits..使完全连接的操作输出向量具有尺寸脱延长,指定输出大小脱延长.
权重矩阵具有大小
输出-经过-输入, 在哪里输出和输入分别对应于输出和输入维度。偏置载体具有尺寸
输出-By-1。
使完全连接的操作输出向量具有尺寸词汇,指定输出大小词汇.
inputSize = numHiddenUnits;outputSize = vocabularySize;parameters.fcDecoder.Weights = dlarray (randn (outputSize inputSize,'单身的'));参数.fcdecoder.bias = dlarray(zeros(outputsize,1,'单身的'));
定义模型解码器函数
创建功能Modeldecoder.,列于解码器模型功能示例的一部分,计算解码器模型的输出。这Modeldecoder.功能,用作单词指数,模型参数和序列长度的输入序列,并返回相应的潜在特征向量。
在模型梯度函数中使用模型函数
使用自定义培训循环培训深度学习模型时,必须计算有关可读参数的损失的渐变。此计算取决于模型函数的前向通过的输出。
有两种使用解码器生成文本数据的常见方法:
闭环 - 对于每个时间步,使用先前预测作为输入进行预测。
打开循环 - 对于每次步骤,使用来自外部源的输入(例如,培训目标)进行预测。
闭环生成
闭环生成是当模型一次生成数据时一次生成数据,并使用先前的预测作为下一个预测的输入。与开环生成不同,此过程不需要在预测之间的任何输入,并且最适合没有监督的情况。例如,一种语言翻译模型,可以一次生成输出文本。
使用闭环
使用编码器输出初始化LSTM网络的隐藏状态DLZ..
州=结构;state.hiddentstate = dlz;State.cellstate = zeros(大小(dlz),'喜欢',dlz);
第一步,使用一个start令牌数组作为解码器的输入。为简单起见,从训练数据的第一个时间步中提取一个开始令牌数组。
DecoderInput = DLX(:,:,1);
预先释放解码器输出以具有大小numclasses.-经过-小匹匹匹匹配-经过-Sequencelength.与相同的数据类型DLX., 在哪里Sequencelength.是所需的生成长度,例如,训练目标的长度。对于此示例,指定序列长度为16。
Sequencelength = 16;dly = zeros(词汇表,小靶,序列灵长,'喜欢',DLX);dly = dlarray(dly,“认知行为治疗”);
对于每次步骤,预测序列的下一次步骤使用Modeldecoder.功能。在每次预测之后,找到与解码器输出的最大值对应的索引,并使用这些索引作为下次步骤的解码器输入。
为了t = 1:sequencelength [dly(:,:,t),状态] = modeldecoder(参数,解码input,状态);[〜,IDX] = max(dly(:,:,t));DecoderInput = IDX;结尾
输出是一个词汇-经过-小匹匹匹匹配-经过-Sequencelength.大批。
尺寸(dly)
ans =.1×3.3595 32 16.
此代码片段显示在模型渐变功能中执行闭环生成的示例。
函数梯度= MaposGRADENTERS(参数,DLX,SECENCELENGS)%编码输入。dlz = modelencoder(参数,dlx,sequencelengs);%初始化LSTM状态。州=结构;state.hiddentstate = dlz;State.cellstate = zeros(大小(dlz),'喜欢',dlz);%初始化解码器输入。DecoderInput = DLX(:,:,1);%闭环预测。Sequencelength = size(DLX,3);dly = zeros(numclasses,minibatchsize,sequencelength,'喜欢',DLX);为了t = 1:sequencelength [dly(:,:,t),状态] = modeldecoder(参数,解码input,状态);[〜,IDX] = max(dly(:,:,t));DecoderInput = IDX;结尾%计算损失。%……%计算梯度。%……结尾
开环生成:教师强迫
当使用闭环生成训练时,预测序列中每个步骤的最可能的单词可能导致次优效果。例如,在图像标题工作流程中,如果解码器预测标题的第一字是当给定大象的图像时的“a”,那么预测下一个单词的“大象”的概率变得更不可能,因为所以英语文本中出现“一象”短语的概率极低。
为了帮助网络收敛更快,您可以使用老师强迫:使用目标值作为解码器的输入,而不是以前的预测。使用教师强迫可以帮助网络从序列的后期时间步长中学习特征,而不必等待网络正确地生成序列的早期时间步长。
要执行教师强制,请使用ModelEncoder.直接使用目标序列作为输入。
使用编码器输出初始化LSTM网络的隐藏状态DLZ..
州=结构;state.hiddentstate = dlz;State.cellstate = zeros(大小(dlz),'喜欢',dlz);
使用目标序列作为输入进行预测。
dly = modeldecoder(参数,dlx,状态);
输出是一个词汇-经过-小匹匹匹匹配-经过-Sequencelength.阵列,其中Sequencelength.是输入序列的长度。
尺寸(dly)
ans =.1×3.3595 32 14.
此代码段显示在模型渐变功能中执行教师强制执行的示例。
函数梯度= MaposGRADENTERS(参数,DLX,SECENCELENGS)%编码输入。dlz = modelencoder(参数,dlx,dlz);%初始化LSTM状态。州=结构;state.hiddentstate = dlz;State.cellstate = zeros(大小(dlz),'喜欢',dlz);%老师强迫。dly = modeldecoder(参数,dlx,状态);%计算损失。%……%计算梯度。%……结尾
解码器模型功能
这Modeldecoder.函数,将模型参数、字索引序列和网络状态作为输入,并返回解码后的序列。
因为这LSTM.函数是有状态(当给定时间序列作为输入时,函数传播并更新每个时间步长之间的状态)嵌入和全协商默认情况下的功能(当给定时间序列为输入时,函数在每次阶段都运行)独立运行),Modeldecoder.功能支持序列和单个金宝app时间步骤输入。
函数(海底、州)= modelDecoder(参数、dlX状态)%嵌入。重量= parameters.emb.Weights;dlX =嵌入(dlX、重量);%lstm。Inputweights = parameters.lstmdecoder.Inputweights;reachrentweights = parameters.lstmdecoder.recurrentweights;bias = parameters.lstmdecoder.bias;hiddenstate = state.hiddentstate;cellstate = state.cellstate;[dly,hiddenstate,cellstate] = lstm(dlx,hiddenstate,cellstate,......输入重量,复制重量,偏见);state.hiddentstate = hiddenstate;state.cellstate = cellstate;%完全连接。权重= parameters.fcdecoder.weights;bias = parameters.fcdecoder.bias;dly =全协调(dly,重量,偏见);结尾
也可以看看
相关的话题
你也可以从以下列表中选择一个网站:
