基于深度学习的多标签文本分类
这个示例展示了如何对具有多个独立标签的文本数据进行分类。
对于每个观察可能有多个独立标签的分类任务——例如,一篇科学文章的标签——你可以训练一个深度学习模型来预测每个独立类别的概率。为了使网络能够学习多标签分类目标,可以使用二进制交叉熵损失单独优化每个类的损失。
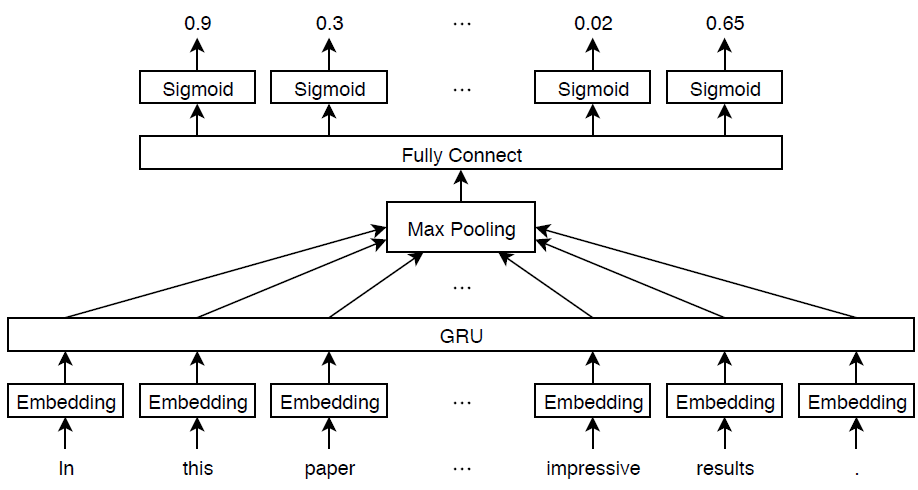
这个例子定义了一个深度学习模型,它根据使用arXiv API[1]收集的数学论文摘要对学科领域进行分类。该模型由单词嵌入和GRU、最大池操作、全连接操作和sigmoid操作组成。
要衡量多标签分类的性能,可以使用标签F-score[2]。标记F-score通过关注带有部分匹配的每个文本分类来评估多标签分类。该度量是匹配标签与真实和预测标签总数的标准化比例。
这个例子定义了以下模型:
将单词序列映射到数字向量序列的单词嵌入。
一种GRU操作,学习嵌入向量之间的依赖关系。
将一系列特征向量缩减为单个特征向量的最大池操作。
将特征映射到二进制输出的全连接层。
用于学习输出和目标标签之间的二进制交叉熵损失的sigmoid操作。
此图显示了一段文本在模型体系结构中传播并输出概率向量。概率是独立的,因此它们不必求和为一。
导入文本数据
使用arXiv API从数学论文中导入一组摘要和类别标签。属性指定要导入的记录数量importSize变量请注意,arXiv API的速率限制为一次查询1000篇文章,需要在请求之间等待。
进口规模=50000;
导入第一组记录。
url =“https://export.arxiv.org/oai2?verb=ListRecords”+...“集=数学”+...“&metadataPrefix=arXiv”;选项=网络选项(“超时”, 160);代码= webread (url选项);
解析返回的XML内容并创建htmlTree包含记录信息的对象。
树=htmlTree(代码);子树=findElement(树,“记录”);元素个数(子树)
迭代地导入更多的记录块,直到达到所需的数量,或者没有更多的记录。要继续从停止的位置导入记录,请使用resumptionToken属性。要遵守arXiv API施加的速率限制,请使用暂停函数。
而numel(子树)“resumptionToken”);如果等空(近尾端)打破终止resumptionToken=extractHTMLText(subtreeResumption);url=“https://export.arxiv.org/oai2?verb=ListRecords”+..." &resumptionToken = "+resumptionToken;暂停(20)代码=webread(url,选项);树=htmlTree(代码);子树=[子树;findElement(树,“记录”));终止
提取和预处理文本数据
从解析的HTML树中提取摘要和标签。
找到“和“< >类别”元素使用findElement函数。
subtreeAbstract=htmlTree("");subtreegory=htmlTree("");对于i=1:numel(子树)子树抽象(i)=findElement(子树(i),“抽象”);subtreeCategory (i) = findElement(子树(我),“类别”);终止
属性从包含摘要的子树中提取文本数据extractHTMLText函数。
textData=extractHTMLText(subtreeAbstract);
的标记和预处理文本数据预处理文本函数,列在示例的最后。
documentsAll=预处理文本(textData);documentsAll(1:5)
ans=5×1标记化文档:72个标记:描述新算法$(k,\ell)$卵石游戏颜色获得特征化系列$(k,\ell)$sparse graph算法解族问题关注树分解图特例稀疏图出现刚性理论近年来受到越来越多的关注特殊有色卵石推广加强先前的结果lee streinu给出了新的证明tuttenashwilliams特征树性提出了新的分解证明arsity base$(千分之一)$pebble游戏颜色工作公开连接pebble游戏算法之前的稀疏图算法gabow gabow westermann hendrickson 22标记:显示行列式stirling循环数计数未标记的非循环单源自动机证明涉及双射自动机某些标记的格点路径符号可逆对合评估行列式18标记:“论文”“显示”“计算”“$\lambda{\alpha}”“规范”“$\alpha\ge 0”“并矢”“网格”“结果”“结果”“描述”“哈代”“空间”“$h^p(r^n)$”“术语”“并矢”“特殊”“原子”"62标记:部分立方体等距子图超立方体结构图定义平均半立方体djokovi-winklers关系发挥重要作用理论部分立方体结构利用纸刻画二部图部分立方体任意维新刻画建立新的证明已知结果给出操作笛卡尔积粘贴展开收缩过程利用纸张构造新的部分立方体旧的特殊等距格维数有限部分立方体获得平均运算计算29个标记:纸张呈现算法计算hecke特征系统hilbertsiegel尖点形式实二次域窄类数给出示例二次域$\q(\sqrt{5})$示例识别hilbertsiegel特征形式可能提升hilbert特征形式
从包含标签的子树中提取标签。
strLabels=extractHTMLText(subtreeCegory);labelsAll=arrayfun(@split,strLabels,“UniformOutput”、假);
删除不属于的标签“数学”设置
对于i = 1:numel(labelsAll) labelsAll{i} = labelsAll{i}(startsWith(labelsAll{i},“数学。”));终止
可视化word cloud中的某些类。查找与以下内容对应的文档:
摘要标记为“组合数学”,而不是标记为
“统计理论”摘要标注“统计理论”而未标注“统计理论”
“组合学”两者都有标记的摘要
“组合学”和“统计理论”
使用伊斯梅尔函数。
idxCO=cellfun(@(lbls)ismember(“数学。有限公司”,lbls)和&~ismember(“数学圣”,lbls),labelsAll);idxST=cellfun(@(lbls)ismember(“数学圣”,lbls)和&~ismember(“数学。有限公司”lbls) labelsAll);idxCOST = cellfun(@(lbls)) ismember(“数学。有限公司”lbls) & & ismember (“数学圣”lbls) labelsAll);
在单词云中可视化每个组的文档。
图子地块(1,3,1)wordcloud(文档所有(idxCO));标题(“组合学”次要情节(1、3、2)wordcloud (documentsAll (idxST));标题(“统计理论”)子批次(1,3,3)wordcloud(文档所有(idxCOST));标题(“两者”)

查看类个数。
一会=独特(猫(labelsAll {:}));numClasses =元素个数(类名)
numClasses = 32
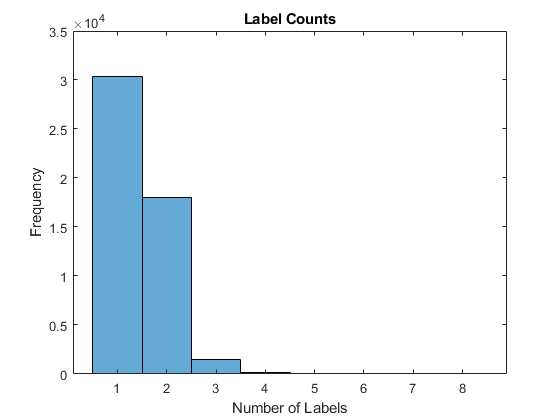
使用直方图可视化每个文档标签的数量。
labelCounts=cellfun(@numel,labelsAll);图直方图(labelCounts)xlabel(“标签”) ylabel (“频率”)标题(”标签项”)
为深度学习准备文本数据
将数据划分为训练分区和验证分区CVD分区函数。通过设置,保留10%的数据进行验证“坚持”选择0.1。
本量利= cvpartition(元素个数(documentsAll),“坚持”, 0.1);documentsTrain = documentsAll(培训(cvp));documentsValidation = documentsAll(测试(cvp));labelsTrain = labelsAll(培训(cvp));labelsValidation = labelsAll(测试(cvp));
创建一个单词编码对象,将培训文档编码为单词索引序列。通过设置“秩序”选项“频率”,以及“MaxNumWords”选择5000。
enc=文字编码(文档),“秩序”,“频率”,“MaxNumWords”,5000)
enc=wordEncoding,属性:NumWords:5000词汇:[1×5000字符串]
要改进培训,请使用以下技巧:
在训练时,截断文档的长度,以减少使用的填充量,并且不丢弃太多的数据。
使用按长度升序排序的文档训练一个历元,然后在每个历元中洗牌数据。这种技术称为索塔格勒.
要选择用于截断的序列长度,请在直方图中可视化文档长度,并选择捕获大部分数据的值。
documentLengths = doclength (documentsTrain);图直方图(documentLengths)包含(“文档长度”) ylabel (“频率”)标题(“文档长度”)

大多数培训文件的代币少于175枚。使用175个标记作为截断和填充的目标长度。
maxSequenceLength = 175;
要使用sortagrad技术,请按长度升序对文档进行排序。
[~,idx]=排序(documentlength);documentsTrain=documentsTrain(idx);labelsTrain=labelsTrain(idx);
定义和初始化模型参数
定义每个操作的参数并将其包含在结构中。使用parameters.OperationName.ParameterName哪里参数结构是,O名称是操作的名称(例如“俱乐部”),及ParameterName是参数的名称(例如,“重量”).
创建一个结构参数包含模型参数。使用零初始化偏差。使用以下权重初始值设定项进行操作:
对于嵌入,用随机的法线值初始化权值。
对于GRU操作,使用
草签函数,列在示例的最后。属性初始化权值,用于完全连接操作
initializeGaussian函数,列在示例的最后。
embeddingDimension = 300;numHiddenUnits = 250;inputSize = cn . numwords + 1;参数=结构;[endnoterp.com] . weights = dlarray(randn([embedingdimension inputSize]));parameters.gru.InputWeights = dlarray (initializeGlorot (3 * numHiddenUnits embeddingDimension));parameters.gru.RecurrentWeights = dlarray (initializeGlorot (3 * numHiddenUnits numHiddenUnits));parameters.gru.Bias = dlarray (0 (3 * numHiddenUnits, 1,“单身”));parameters.fc.Weights=dlarray(初始化高斯([numclass,numHiddenUnits]);parameters.fc.Bias=dlarray(零(numclass,1,“单身”));
查看参数结构。
参数
参数=带字段的结构:Emb: [1×1结构]gru: [1×1结构]fc: [1×1结构]
查看GRU操作的参数。
parameters.gru
ans=带字段的结构:input twights: [750×300 dlarray] recurrentwights: [750×250 dlarray] Bias: [750×1 dlarray]
定义模型函数
创建函数模型,它计算前面描述的深度学习模型的输出。这个函数模型将输入数据作为输入dlX以及模型参数参数.网络输出标签的预测。
定义模型梯度函数
创建函数modelGradients,它接受一小批输入数据作为输入dlX以及相应的目标T包含标签,并返回关于可学习参数、相应损耗和网络输出的损耗梯度。
指定培训选项
训练5个时代与小批量大小256。
numEpochs=5;miniBatchSize=256;
使用Adam优化器进行训练,学习率为0.01,指定梯度衰减和平方梯度衰减因子分别为0.5和0.999。
learnRate = 0.01;gradientDecayFactor = 0.5;squaredGradientDecayFactor = 0.999;
使用阈值为1的渐变剪辑 范数梯度剪辑。
梯度阈值=1;
将培训进度可视化到绘图中。
阴谋=“训练进步”;
若要将概率向量转换为标签,请使用概率高于指定阈值的标签。指定标签阈值为0.5。
labelThreshold = 0.5;
每个时代都要验证网络。
numObservationsTrain=numel(documentsTrain);NumiteOptionSperepoch=floor(numObservationsTrain/miniBatchSize);validationFrequency=NumiteOptionSperepoch;
如果GPU可用,则在GPU上进行培训。这需要并行计算工具箱™. 使用GPU需要并行计算工具箱™ 和支持的GPU设备。有关支持的设备的信息,请参阅金宝appGPU支金宝app持情况(并行计算工具箱).
执行环境=“自动”;
火车模型
使用自定义训练循环训练模型。
对于每个epoch,循环小批数据。在每个纪元的末尾,洗牌数据。在每次迭代结束时,更新训练进度图。
对于每个小批量:
将文档转换为单词索引序列,并将标签转换为虚拟变量。
将序列转换为
dlarray基础类型为single的对象,并指定标注标签“BCT”(批处理、通道、时间)。对于GPU培训,请转换为
gpuArray物体。评估模型梯度和损失使用
dlfeval和modelGradients函数。剪辑的梯度。
使用以下命令更新网络参数:
adamupdate函数。如有必要,请使用
模型预测函数,列在示例的最后。更新训练图。
初始化培训进度图。
如果情节= =“训练进步”图形%标记F分数。subplot(2,1,1) lineFScoreTrain = animatedline(“颜色”0.447 - 0.741 [0]);lineFScoreValidation = animatedline (...“线型”,'--',...“标记”,“o”,...“MarkerFaceColor”,“黑”);ylim([01])xlabel(“迭代”) ylabel (“标签f值”)网格在%的损失。子地块(2,1,2)lineLossTrain=动画线(“颜色”[0.85 0.325 0.098]);lineLossValidation = animatedline (...“线型”,'--',...“标记”,“o”,...“MarkerFaceColor”,“黑”);ylim([0正])包含(“迭代”) ylabel (“损失”)网格在终止
初始化亚当优化器的参数。
trailingAvg=[];trailingAvgSq=[];
准备验证数据。创建一个一次性编码矩阵,其中非零项对应于每个观测的标签。
numObservationsValidation=numel(documentsValidation);TValidation=0(NumClass,numObservationsValidation,“单身”);对于i=1:numObservationsValidation[~,idx]=ismember(labelvalidation{i},classNames);TValidation(idx,i)=1;终止
训练模型。
迭代=0;开始=tic;%环游各个时代。对于时代= 1:numEpochs%在小批量上循环。对于i=1:numIterationsPerEpoch迭代=迭代+1;idx=(i-1)*miniBatchSize+1:i*miniBatchSize;%读取小批量数据并将标签转换为虚拟%变量。文件=文件应变(idx);标签=标签序列(idx);%将文档转换为序列。len = min (maxSequenceLength马克斯(doclength(文档)));X = doc2sequence (enc、文档...“PaddingValue”inputSize,...“长度”,len);X=cat(1,X{:});% Dummify标签。T = 0 (numClasses, miniBatchSize,“单身”);对于j=1:miniBatchSize[~,idx2]=ismember(标签{j},类名);T(idx2,j)=1;终止%转换小批数据到美元。dlX=dlX阵列(X,“BTC”);%如果在GPU上训练,则将数据转换为gpuArray。如果(b)执行环境==“自动”&&canUseGPU)| |执行环境==“图形”dlX = gpuArray (dlX);终止使用dlfeval和% modelGradients函数。[gradient,loss,dlYPred] = dlfeval(@modelGradients, dlX, T, parameters);%梯度剪裁。gradient = dlupdate(@(g) thresholdL2Norm(g, gradientThreshold),gradient);%使用Adam优化器更新网络参数。(参数、trailingAvg trailingAvgSq) = adamupdate(参数、渐变...trailingAvg trailingAvgSq,迭代,learnRate、gradientDecayFactor squaredGradientDecayFactor);%显示培训进度。如果情节= =“训练进步”子批次(2,1,1)D=持续时间(0,0,toc(开始),“格式”,“hh:mm:ss”);标题(”时代:“+纪元+,已过:+字符串(D))%的损失。addpoints (lineLossTrain、迭代、双(收集(extractdata(损失))))% f值标签。YPred = extractdata(dlYPred) > labelThreshold;分数= labelingFScore (YPred T);addpoints (lineFScoreTrain、迭代、双(收集(分数)))drawnow%显示验证度量。如果迭代== 1 || mod(iteration,validationFrequency) == 0 dlYPredValidation = modelPredictions(parameters,enc,documentsValidation,miniBatchSize,maxSequenceLength);%的损失。lossValidation = crossentropy (dlYPredValidation TValidation,...“目标类别”,“独立的”,...“DataFormat”,“CB”);addpoints (lineLossValidation、迭代、双(收集(extractdata (lossValidation))))% f值标签。YPredValidation = extractdata(dlYPredValidation) > labelThreshold;分数= labelingFScore (YPredValidation TValidation);addpoints (lineFScoreValidation、迭代、双(收集(分数)))drawnow终止终止终止%洗牌数据。idx=randperm(numObservationsTrain);documentsTrain=documentsTrain(idx);labelsTrain=labelsTrain(idx);终止

测试模型
要对一组新数据进行预测,请使用模型预测函数,列在示例的最后。这个模型预测函数以模型参数、单词编码和令牌化文档数组作为输入,并输出与指定的小批量大小和最大序列长度相对应的模型预测。
dlYPredValidation=模型预测(参数、enc、文档验证、miniBatchSize、maxSequenceLength);
要将网络输出转换为标签数组,请查找分数高于指定标签阈值的标签。
YPredValidation = extractdata(dlYPredValidation) > labelThreshold;
为了评估绩效,使用labelingFScore函数,列在示例末尾。标记F-score通过关注具有部分匹配的文本分类来评估多标签分类。
分数=标签分数(YPredValidation,TValidation)
得分=单0.5852
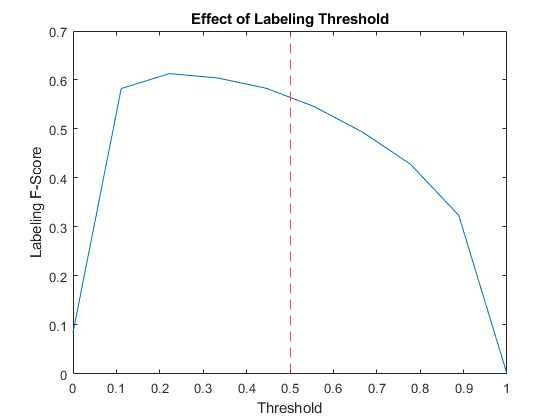
通过尝试阈值的一系列值并比较结果,查看标记阈值对标记F分数的影响。
用力推= linspace (0, 1, 10);分数= 0(大小(刺));对于i = 1:numel(thr) YPredValidationThr = extractdata(dlYPredValidation) >= thr(i);分数(i) = labelingFScore (YPredValidationThr TValidation);终止图绘制(用力推,得分)参照线(labelThreshold,“r——”);xlabel(“阈值”) ylabel (“标签f值”)标题(“标记阈值效应”)
可视化预测
为了可视化分类器的正确预测,计算真阳性的数量。真正的正数是一个分类器的实例正确地预测了一个观察到的特定类。
Y = YPredValidation;T = TValidation;numTruePositives = sum(T & Y,2);numObservationsPerClass = (T, 2)之和;true = numTruePositives ./ numObservationsPerClass;
在直方图中可视化每个类的真阳性数。
figure [~,idx] = sort(true, true, true)“下降”);柱状图(“类别”类名(idx),“垃圾计数”,truepositivates(idx))xlabel(“类别”) ylabel (“真阳性率”)标题(“真阳性率”)

通过显示真阳性、假阳性和假阴性的分布,可视化分类器错误预测的实例。假阳性是指分类器将特定错误类分配给观测值的实例。假阴性是指分类器未能分配特定正确类的实例进行观察。
创建一个混淆矩阵,显示真阳性、假阳性和假阴性计数:
对于每个类别,在对角线上显示真实的正计数。
对于每一对类(我,J),显示误报的实例数J当实例也是假否定for时我.
即,给定元素的混淆矩阵为:
计算假阴性和假阳性。
假阴性= T & ~Y;假阳性= ~T & Y;
计算非对角元素。
假阴性=排列(假阴性[3 2 1]);数字条件假阳性=总和(假阴性和假阳性,2);数字条件假阳性=挤压(数字条件假阳性);tpfnMatrix=数字条件假阳性;
将对角线元素设置为真正计数。
idxDiagonal = 1: numClasses + 1: numClasses ^ 2;tpfnMatrix (idxDiagonal) = numTruePositives;
使混淆矩阵中的真阳性和假阳性计数形象化confusionchart函数并对矩阵进行排序,使对角线上的元素按降序排列。
figure cm = confectionchart (tpfnMatrix,classNames);sortClasses(厘米,“descending-diagonal”);标题(真阳性,假阳性)

要更详细地查看矩阵,请将此示例作为一个活动脚本打开,并在一个新窗口中打开图形。
文本预处理功能
这个预处理文本函数使用以下步骤对输入文本数据进行标记和预处理:
使用
tokenizedDocument函数。的方法提取数学方程作为单个令牌“常规表达”选项,指定正则表达式"\$.*?\$",它捕获出现在两个“$”符号之间的文本。使用
erasePunctuation函数。属性将文本转换为小写
降低函数。使用
移除单词函数。用the使文本义化
normalizeWords函数与“风格”选项设置为“引理”.
函数文件= preprocessText (textData)标记文本。regularExpressions =表;regularExpressions。模式="\$.*?\$"; 正则表达式。键入=“方程式”;文档=标记化文档(textData,“常规表达”, regularExpressions);%擦掉标点符号。= erasePunctuation文件(文档);%转换为小写。文件=低(文件);% Lemmatize。= addPartOfSpeechDetails文件(文档);文档= normalizeWords(文档,“风格”,“引理”);删除停止字。文件=删除文字(文件);%删除短单词。文件=删除短两个文件(文件,2);终止
模型函数
这个函数模型将输入数据作为输入dlX以及模型参数参数,并返回标签的预测。
函数海底=模型(dlX、参数)%嵌入权重=parameters.emb.weights;dlX=嵌入(dlX,权重);%格鲁inputWeights = parameters.gru.InputWeights;recurrentWeights = parameters.gru.RecurrentWeights;偏见= parameters.gru.Bias;numHiddenUnits =大小(inputWeights, 1) / 3;hiddenState = dlarray(zeros([numHiddenUnits 1]));dlY = gru(dlX, hiddenState, inputwights, recurrentwights, bias,“DataFormat”,“认知行为治疗”);时间维度的最大池海底= max(海底,[],3);%完全连接重量= parameters.fc.Weights;偏见= parameters.fc.Bias;海底= fullyconnect(海底,重量、偏见,“DataFormat”,“CB”);%乙状结肠海底=乙状结肠(海底);终止
模型梯度函数
这个modelGradients函数接受一小批输入数据作为输入dlX与相应的目标T包含标签并返回关于可学习参数、相应损耗和网络输出的损耗梯度。
函数[梯度,损失,dlYPred]=模型梯度(dlX,T,参数)dlYPred=模型(dlX,参数);损失=交叉熵(dlYPred,T,“目标类别”,“独立的”,“DataFormat”,“CB”);梯度=dlgradient(损失、参数);终止
模型的预测函数
这个模型预测函数将模型参数、单词编码、标记化文档数组、小批量大小和最大序列长度作为输入,并通过迭代指定大小的小批量来返回模型预测。
函数DlyPredictions=modelPredictions(参数,enc,documents,miniBatchSize,maxSequenceLength)inputSize=enc.NumWords+1;NumBufferations=numel(文档);NumMiterations=ceil(NumBufferations/miniBatchSize);numFeatures=size(参数.fc.Weights,1);dlYPred=0(numFeatures,NumBufferations,“喜欢”, parameters.fc.Weights);对于i=1:numIterations idx=(i-1)*miniBatchSize+1:min(i*miniBatchSize,numObservations);len=min(maxSequenceLength,max(doclength(documents(idx)));X=doc2sequence(enc,documents(idx)),...“PaddingValue”inputSize,...“长度”,len);X=cat(1,X{:});dlX=dlarray(X,“BTC”);dlYPred (:, idx) =模型(dlX、参数);终止终止
标签f值函数
标签F分数函数[2]通过关注具有部分匹配的每文本分类来评估多标签分类。度量值是匹配标签与给定的真实和预测标签总数的归一化比例
在哪里N和C分别对应观测值和类的数量,和Y和T分别对应于预测和目标。
函数score = labelingFScore(Y,T) numObservations = size(T,2);score = (2 * sum(Y .* T)) ./ sum(Y + T);score = sum(scores) / numObservations;终止
Glorot权重初始化函数
这个草签函数根据gloria初始化生成权重数组。
函数weights = initializeGlorot(numOut, numIn) varWeights = sqrt(6 / (numIn + numOut));= varWeights * (2 * rand([numOut, numIn]),“单身”) - 1);终止
高斯权重初始化函数
这个initializeGaussian函数从平均值为0、标准偏差为0.01的高斯分布中采样权重。
函数参数=初始化高斯(sz)参数=随机数(sz,“单身”) * 0.01;终止
嵌入函数
这个嵌入函数将数值索引映射到由输入权重给定的相应向量。
函数Z=嵌入(X,权重)将输入重塑为向量。[N,T]=尺寸(X,2:3);X=重塑(X,N*T,1);索引到嵌入矩阵中。Z=重量(:,X);%通过分离批次和序列维度重塑输出。Z =重塑(Z, [], N, T);终止
范数梯度裁剪函数
这个阈值L2范式函数缩放输入梯度,以便
当
可学习参数的梯度的范数值大于指定的阈值。
函数gradient = thresholdL2Norm(gradient,gradientThreshold) gradientNorm = sqrt(sum(gradients(:).^2));如果gradientNorm > gradientThreshold gradient = gradient * (gradientThreshold / gradientNorm);终止终止
参考文献
arXiv.《arXiv API》,于2020年1月15日发布。https://arxiv.org/help/api
分类任务性能度量的系统分析信息处理与管理45岁的没有。4(2009): 427 - 437。
另见
adamupdate|dlarray|dlfeval|dlgradient|数据更新|完全连接|格鲁|doc2sequence(文本分析工具箱)|extractHTMLText(文本分析工具箱)|htmlTree(文本分析工具箱)|tokenizedDocument(文本分析工具箱)|wordEncoding(文本分析工具箱)
相关的话题
你也可以从以下列表中选择一个网站:
