训练和部署用于语义分割的全卷积网络
这个例子展示了如何使用GPU Coder™在NVIDIA®GPU上训练和部署一个全卷积语义分割网络。
语义分割网络对图像中的每个像素进行分类,从而得到按类分割的图像。语义分割的应用包括用于自动驾驶的道路分割和用于医疗诊断的癌细胞分割。要了解更多,请参见开始使用深度学习进行语义分割(计算机视觉工具箱).
为了说明训练过程,本例训练FCN-8s[1],这是一种用于语义图像分割的卷积神经网络(CNN)。用于语义分割的其他网络类型包括完全卷积网络,如SegNet和U-Net。您也可以将此训练过程应用于这些网络。
此示例使用CamVid数据集[2]从剑桥大学进行培训。该数据集是一组图像的集合,包含在驾驶时获得的街道视图。该数据集为包括汽车、行人和道路在内的32个语义类提供了像素级标签。
第三方的先决条件
要求
CUDA®支持NVIDIA GPU和兼容的驱动程序。
可选
NVIDIA CUDA工具包。
NVIDIA cuDNN库。
编译器和库的环境变量。有关编译器和库的支持版本的信息,请参见金宝app第三方硬件(GPU编码器).有关设置环境变量,请参见设置必备产品下载188bet金宝搏(GPU编码器).
验证GPU环境
使用coder.checkGpuInstall(GPU编码器)函数来验证运行此示例所需的编译器和库是否已正确设置。
envCfg = code . gpuenvconfig (“主机”);envCfg。DeepLibTarget =“cudnn”;envCfg。DeepCodegen = 1;envCfg。安静= 1;coder.checkGpuInstall (envCfg);
设置
本例创建了一个全卷积语义分割网络,其权重由VGG-16网络初始化。vgg16函数检查VGG-16网络支持包的深度学习工具箱模型是否存在,并返回一个预先训练的VGG-16模型。金宝app
vgg16 ();
下载FCN的预训练版本。这个预先训练的模型使您能够运行整个示例,而无需等待训练完成。doTraining标志控制示例是使用示例的训练网络还是预先训练的FCN网络来生成代码。
doTraining = false;如果~doTraining pretrainedURL =“//www.tatmou.com/金宝appsupportfiles/gpucoder/cnn_models/fcn/FCN8sCamVid.mat”;disp (“下载预先训练的FCN (448 MB)…”);websave (“FCN8sCamVid.mat”, pretrainedURL);结束
下载预先训练的FCN (448 MB)…
下载CamVid数据集
从这些url下载CamVid数据集。
imageURL =“http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/files/701_StillsRaw_full.zip”;labelURL =“http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/data/LabeledApproved_full.zip”;outputFolder = fullfile(pwd,“CamVid”);如果~存在(outputFolder“dir”mkdir(outputFolder) labelsZip = fullfile(outputFolder)“labels.zip”);imagesZip = fullfile(outputFolder,“images.zip”);disp (“正在下载16mb CamVid数据集标签……”);websave (labelsZip labelURL);解压缩(labelsZip fullfile (outputFolder“标签”));disp (“正在下载557 MB CamVid数据集图像……”);websave (imagesZip imageURL);解压缩(imagesZip fullfile (outputFolder“图片”));结束
数据下载时间取决于您的互联网连接。直到下载操作完成,示例才会继续执行。或者,使用您的网络浏览器先下载数据集到您的本地磁盘。然后,使用outputFolder变量指向下载文件的位置。
加载CamVid图像
使用imageDatastore加载CamVid图像。imageDatastore使您能够有效地将大量图像加载到磁盘上。
imgDir = fullfile(outputFolder,“图片”,701 _stillsraw_full);imds = imageDatastore(imgDir);
展示其中一张图片。
I = readimage(imds,25);I = histeq(I);imshow(我)

加载CamVid像素标签图像
使用pixelLabelDatastore(计算机视觉工具箱)加载CamVid像素标签图像数据。pixelLabelDatastore将像素标签数据和标签ID封装到一个类名映射中。
按照SegNet论文[3]中描述的训练方法,将CamVid中的32个原始类分组为11个类。指定这些类。
Classes = [“天空”“建筑”“极”“路”“路面”“树”“SignSymbol”“篱笆”“汽车”“行人”“自行车”];
为了将32个类减少为11个类,将原始数据集中的多个类分组在一起。例如,“Car”是“Car”、“SUVPickupTruck”、“Truck_Bus”、“Train”和“OtherMoving”的组合。方法返回分组的标签idcamvidPixelLabelIDs金宝app支持功能。
labelIDs = camvidPixelLabelIDs();
使用类和标签id创建pixelLabelDatastore。
labelDir = fullfile(outputFolder,“标签”);pxds = pixelLabelDatastore(labelDir,classes,labelIDs);
通过将像素标记的图像叠加在图像之上,读取并显示其中一个图像。
C = readimage(pxds,25);cmap = camvidColorMap;B = labeloverlay(I,C,“ColorMap”,提出);imshow (B) pixelLabelColorbar(提出、类);

没有颜色覆盖的区域没有像素标签,也不会在训练中使用。
分析数据集统计信息
要查看CamVid数据集中类标签的分布,请使用countEachLabel(计算机视觉工具箱).这个函数根据类标签计算像素的数量。
tbl = countEachLabel(pxds)
台=11×3表名称PixelCount ImagePixelCount ______________ __________ _______________ {'Sky'} 7.6801e+07 4.8315e+08 {'Building'} 1.1737e+08 4.8315e+08 {'Pole'} 4.7987e+ 08 4.8315e+08 {'Road'} 1.4054e+08 4.8459e +08 {'Pavement'} 3.3614e+ 08 4.8459e +08 {'Pavement'} 5.4259e+07 4.479e+08 {'SignSymbol'} 5.2242e+06 4.6863e+08 {'Fence'} 6.9211e+06 4.516e +08 {'Car'} 2.4437e+ 06 4.4444e+08 {'Pedestrian'} 3.4029e+06 4.4444e+08 {'Bicyclist'} 2.5912e+06 2.6196e+08
按类可视化像素计数。
frequency = tbl.PixelCount/sum(tbl.PixelCount);bar(1:numel(classes),frequency) xticks(1:numel(classes)) xticklabels(tbl.Name) xtickangle(45) ylabel(“频率”)
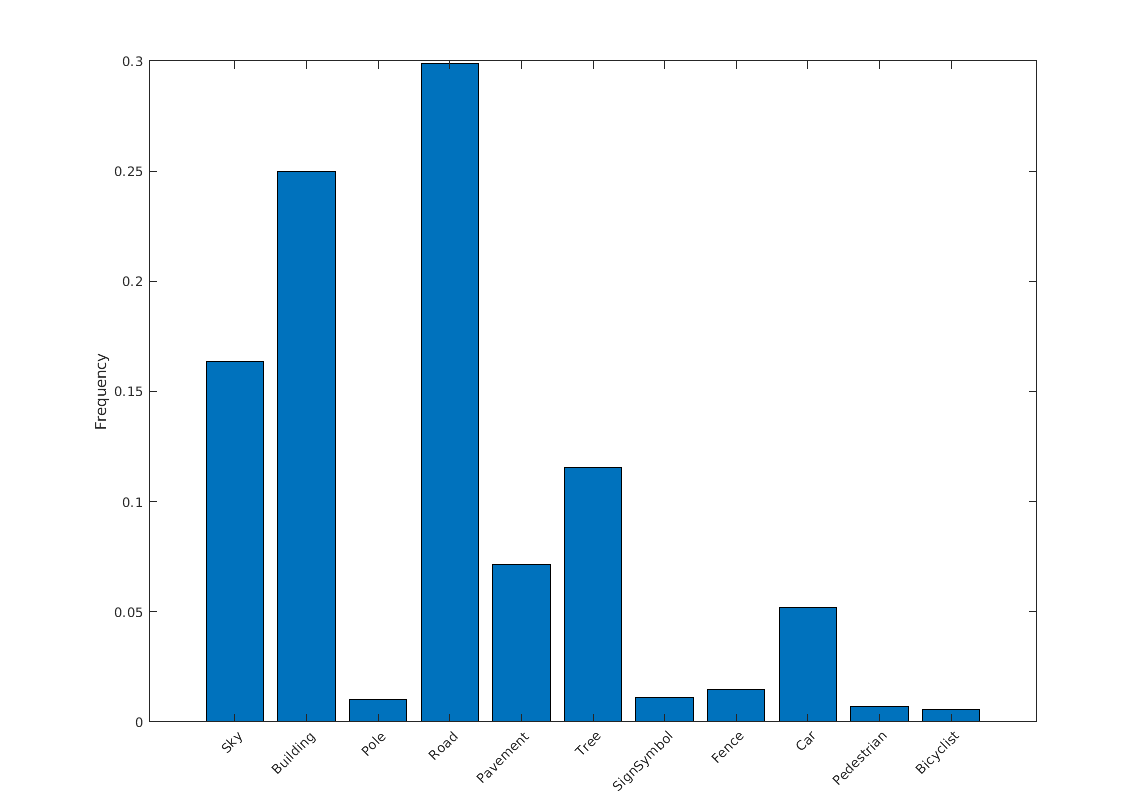
理想情况下,所有类都有相同数量的观察值。CamVid中的类是不平衡的,这是街景汽车数据集中的一个常见问题。这样的场景有更多的天空、建筑和道路像素比行人和骑自行车的像素,因为天空、建筑和道路在图像中覆盖了更多的区域。如果处理不当,这种不平衡会对学习过程造成不利影响,因为学习偏向于优势班级。在本例的后面,您将使用类权重来处理这个问题。
调整CamVid数据的大小
CamVid数据集中的图像是720 × 960。方法将图像和像素标签图像的大小调整为360 * 480resizeCamVidImages而且resizeCamVidPixelLabels金宝app支持功能。
imageFolder = fullfile(outputFolder,“imagesResized”, filesep);imds = resizeCamVidImages(imds,imageFolder);labelFolder = fullfile(outputFolder,“labelsResized”, filesep);pxds = resizeCamVidPixelLabels(pxds,labelFolder);
准备培训和测试集
SegNet通过使用数据集中60%的图像进行训练。其余的图像用于测试。下面的代码将图像和像素标签数据随机分为训练集和测试集。
[imdsTrain,imdsTest,pxdsTrain,pxdsTest] = partitionCamVidData(imds,pxds);
60/40分割的结果是以下数量的训练和测试图像:
numTrainingImages = numel(imdsTrain.Files)
numTrainingImages = 421
numTestingImages = numel(imdste . files)
numTestingImages = 280
创建网络
使用fcnLayers(计算机视觉工具箱)创建全卷积网络层,使用VGG-16权值初始化。的fcnLayers函数执行网络转换,从VGG-16转移权重,并添加语义分割所需的额外层。的输出fcnLayersfunction是一个表示FCN的LayerGraph对象。LayerGraph对象封装网络层和层之间的连接。
imageSize = [360 480];numClasses = numel(classes);lgraph = fcnLayers(imageSize,numClasses);
根据数据集中图像的大小选择图像大小。类的数量是根据CamVid中的类来选择的。
使用类加权来平衡类
CamVid中的类是不平衡的。方法计算出的像素标签计数可以改进训练countEachLabel(计算机视觉工具箱)函数并计算中频类权重[3]。
imageFreq = tbl。像素计数。/ tbl.ImagePixelCount;classWeights = median(imageFreq) ./ imageFreq;
类型指定类的权重pixelClassificationLayer(计算机视觉工具箱).
pxLayer = pixelClassificationLayer(“名字”,“标签”,“类”资源描述。的名字,“ClassWeights”classWeights)
类:[11×1 categorical] ClassWeights: [11×1 double] OutputSize: 'auto'超参数LossFunction: 'crossentropyex'
通过移除当前的pixelClassificationLayer并添加新的层来更新具有新的pixelClassificationLayer的SegNet网络。当前的pixelClassificationLayer命名为“pixelLabels”。删除它使用removeLayers函数,通过使用addLayers方法将新层连接到网络的其他部分connectLayers函数。
lgraph = removeLayers(lgraph,“pixelLabels”);lgraph = addLayers(lgraph, pxLayer);lgraph = connectLayers(lgraph,“softmax”,“标签”);
选择培训项目
训练的优化算法是Adam,它是由自适应力矩估计.使用trainingOptions函数指定用于Adam的超参数。
options = trainingOptions(“亚当”,...“InitialLearnRate”1 e - 3,...“MaxEpochs”, 100,...“MiniBatchSize”4...“洗牌”,“every-epoch”,...“CheckpointPath”tempdir,...“VerboseFrequency”2);
“MiniBatchSize”为4可以减少训练时的内存使用量。您可以根据系统中GPU内存的数量增加或减少该值。
'CheckpointPath'被设置为一个临时位置。这个名称-值对支持在每个训练阶段结束时保存网络检查点。如果由于系统故障或断电导致培训中断,您可以从保存的检查点恢复培训。确保'CheckpointPath'指定的位置有足够的空间来存储网络检查点。
数据增加
数据增强是通过训练过程中对原始数据的随机变换来提高网络精度的一种方法。通过使用数据增强,可以在不增加标记训练样本数量的情况下为训练数据添加更多的多样性。为了对图像和像素标签数据应用相同的随机变换,使用数据存储组合和变换。首先,结合imdsTrain而且pxdsTrain.
dsTrain = combine(imdsTrain, pxdsTrain);
接下来,使用数据存储转换来应用支持函数中定义的所需数据增强金宝appaugmentImageAndLabel.这里使用随机左右反射和+/- 10像素的随机X/Y平移进行数据增强。
xTrans = [-10 10];yTrans = [-10 10];dsTrain = transform(dsTrain, @(data)augmentImageAndLabel(data,xTrans,yTrans));
注意,数据扩充并不应用于测试和验证数据。理想情况下,测试和验证数据应该代表原始数据,并且不进行修改,以便进行无偏评价。
开始训练
开始使用trainNetwork如果doTrainingFlag是真的。否则,加载一个预先训练的网络。
该训练在NVIDIA™Titan Xp上进行了验证,其GPU内存为12 GB。如果你的GPU内存较少,你可能会耗尽内存。如果系统中没有足够的内存,请尝试降低MiniBatchSize财产trainingOptions为1。根据GPU硬件的不同,训练这个网络大约需要5个小时或更长时间。
doTraining = false;如果doTraining [net, info] = trainNetwork(dsTrain,lgraph,options);保存(“FCN8sCamVid.mat”,“净”);结束
将DAG网络对象保存为一个名为FCN8sCamVid.mat.这个mat文件在代码生成期间使用。
执行MEX代码生成
的fcn_predict.m函数接受图像输入,利用保存在。中的深度学习网络对图像进行预测FCN8sCamVid.mat文件。函数从中加载网络对象FCN8sCamVid.mat转化为一个持久变量mynet并在后续的预测调用中重用持久对象。
类型(“fcn_predict.m”)
版权所有The MathWorks, Inc. persistent mynet;if isempty(mynet) mynet = code . loaddeeplearningnetwork ('FCN8sCamVid.mat');End %传入输入输出= predict(mynet,in);
生成MEX目标设置的GPU配置对象,目标语言为c++。使用编码器。DeepLearningConfig(GPU编码器)函数创建一个cuDNN的深度学习配置对象,并将其分配给DeepLearningConfig属性的图形处理器代码配置对象。运行codegen(MATLAB编码器)指定输入大小[360,480,3]的命令。这个大小对应于FCN的输入层。
cfg = code .gpu config (墨西哥人的);cfg。TargetLang =“c++”;cfg。DeepLearningConfig =编码器。DeepLearningConfig (“cudnn”);codegen配置cfgfcn_predictarg游戏{(360480 3 uint8)}报告
代码生成成功:查看报告
运行生成的MEX
加载并显示输入图像。
我的意思是:“testImage.png”);imshow (im);

通过调用fcn_predict_mex在输入图像上。
Predict_scores = fcn_predict_mex(im);
的predict_scoresVariable是一个三维矩阵,有11个通道,对应于每个类的像素级预测分数。通过使用最大预测分数来计算通道以获得按像素划分的标签。
[~,argmax] = max(predict_scores,[],3);
将分割后的标签覆盖在输入图像上,显示分割后的区域。
Classes = [“天空”“建筑”“极”“路”“路面”“树”“SignSymbol”“篱笆”“汽车”“行人”“自行车”];cmap = camvidColorMap();SegmentedImage = labeloverlay(im,argmax,“ColorMap”,提出);图imshow (SegmentedImage);pixelLabelColorbar(提出、类);

清理
清除内存中加载的静态网络对象。
清晰的墨西哥人;
金宝app支持功能
函数data = augmentImageAndLabel(data, xTrans, yTrans)使用随机反射和增强图像和像素标签图像%的翻译。为i = 1:size(data,1)...“XReflection”,真的,...“XTranslation”xTrans,...“YTranslation”, yTrans);%将输出空间中图像中心的视图居中%,允许翻译将输出图像移出视图。路由= affineOutputView(size(data{i,1}), tform,“BoundsStyle”,“centerOutput”);使用相同的变换扭曲图像和像素标签。。Data {i,1} = imwarp(Data {i,1}, tform,“OutputView”,溃败);Data {i,2} = imwarp(Data {i,2}, tform,“OutputView”,溃败);结束结束
参考文献
朗,J., E.谢尔哈默,T.达雷尔。“语义分割的全卷积网络。”IEEE计算机视觉与模式识别会议论文集,2015,pp. 3431-3440。
[2]布罗斯托,G. J.福克尔,R.西波拉。“视频中的语义对象类:一个高清地面真相数据库。”模式识别信.2009年第2期第30卷第88-97页。
Badrinarayanan, V., A. Kendall和R. Cipolla。“SegNet:一种用于图像分割的深度卷积编码器-解码器架构”,arXiv预印本,arXiv:1511.00561, 2015。
您也可以从以下列表中选择网站:
