贝叶斯套索回归
这个例子展示了如何通过使用贝叶斯套索回归执行可变选择。
套索回归是一种线性回归技术,它结合了正则化和变量选择。正则化通过降低回归系数的大小有助于防止过度拟合。套索回归的频率论观点不同于其他正则化技术,如岭回归,因为套索属性s值正好等于0,回归系数对应于不重要或冗余的预测值。
考虑这个多元线性回归模型:
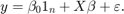
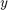 是一个向量N响应。
是一个向量N响应。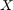 是一个矩阵P相应的观测预测变量。
是一个矩阵P相应的观测预测变量。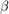 是一个向量P回归系数。
是一个向量P回归系数。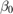 是拦截。
是拦截。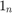 是一个长度N1的列向量。
是一个长度N1的列向量。 是iid高斯扰动的随机向量,其均值为0,方差为
是iid高斯扰动的随机向量,其均值为0,方差为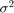 .
.
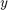
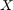
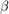
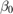
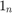

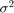
套索回归的频率观的目标函数是
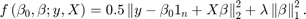
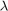 是惩罚(或收缩)项,与其他参数不同,它不适合数据。必须为指定值在估计之前,最好的做法是调整它。在指定值之后,
是惩罚(或收缩)项,与其他参数不同,它不适合数据。必须为指定值在估计之前,最好的做法是调整它。在指定值之后,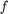 被最小化相对于该回归系数。最终的系数被套索估计。有关套索回归的频率论观点的详细信息,请参阅[191].
被最小化相对于该回归系数。最终的系数被套索估计。有关套索回归的频率论观点的详细信息,请参阅[191].
对于这个例子,考虑建立一个预测线性模型的美国失业率。你需要一个能很好概括的模型。换句话说,您希望通过删除所有冗余预测值和所有与失业率不相关的预测值来最小化模型复杂性。
加载和预处理数据
加载美国宏观经济数据集数据_USEconModel.mat.
负载数据模型
该数据集包括MATLAB®时间表数据表,其中包含从1947年第一季度到2009年第一季度测量的14个变量;UNRATE是美国失业率。有关详细信息,请输入描述在命令行。
在同一图形中绘制所有系列,但在单独的子地块中绘制。
图形对于j=1:size(DataTable,2)子图(4,4,j)plot(DataTable.Time,DataTable{:,j});title(DataTable.Properties.VariableNames(j));终止

所有系列,除联邦基金,GS10,TB3MS和UNRATE似乎有指数趋势。
将对数变换应用于具有指数趋势的变量。
haseExpoTrend=~ismember(DataTable.Properties.VariableNames,...[“联邦基金”“GD10”“TB3MS”“UNRATE”]);DataTableLog = varfun(@日志,数据表,“输入变量”,...VariableNames(haseExpoTrend));DataTableLog=[DataTableLog DataTable(:,DataTable.Properties.VariableNames(~hasexpotrend));
数据表日志时间表是什么样的数据表,但具有指数趋势的变量在对数尺度上。
在lasso回归目标函数中,具有相对较大量级的系数往往主导惩罚。因此,在实施lasso回归时,变量具有相似的尺度非常重要。比较中变量的尺度数据表日志通过在同一轴上绘制方框图。
图:箱线图(DataTableLog.Variables,'标签',DataTableLog.Properties.VariableNames);h=gca;h.XTickLabelRotation=45;title(“可变方框图”);

这些变量具有相当相似的尺度。
为了确定时间序列模型如何概括,步骤如下:
将数据划分为估计和预测样本。
将模型与估计样本相匹配。
使用拟合模型来预测应答到预测范围。
估计每个模型的预测均方误差(FMSE)。
选择具有最低FMSE模型。
为响应和预测数据创建估计和预测样本变量。指定一个4年(16个季度)的预测期。
FH = 16;Y = DataTableLog.UNRATE(1:(结束 - FH));YF = DataTableLog.UNRATE((端 - FH + 1):结束);isresponse = DataTable.Properties.VariableNames ==“UNRATE”;X = DataTableLog{1:(end - fh),~isresponse};XF = DataTableLog{(end - fh + 1):end,~isresponse};p =大小(X, 2);预测的数量%predictornames=DataTableLog.Properties.VariableNames(~isresponse);
飞度简单线性回归模型
将简单线性回归模型拟合到估计样本。指定变量名称(响应变量的名称必须是最后一个元素)。提取P-值。使用5%的显著性水平确定不显著系数。
SLRMdlFull=fitlm(X,y,“VarNames”,DataTableLog.Properties.VariableNames)slrPValue=SLRMdlFull.coefficientname;isInSig=SLRMdlFull.coefficientname(slrPValue>0.05)
SLRMdlFull =线性回归模型:UNRATE ~[13个预测因子中14项的线性公式]Estimate SE tStat pValue ________ ________ _______ __________ (Intercept) 88.014 5.3229 16.535 2.6568e-37 log_COE 7.1111 2.3426 3.0356 0.0027764 log_CPIAUCSL -3.4032 2.4611 -1.3828 0.16853 log_GCE -5.63 1.1581 -4.8615 2.6245e-06 log_GDP 14.522 3.9406 3.6851 0.00030659 log_GDPDEF 11.926 2.9298 4.0704 7.1598e-05 log_GPDI -2.5939 0.54603 -4.75044.2792e-06 log_GS10 0.57467 0.29313 1.9605 0.051565 log_HOANBS -32.861 1.4507 -22.652 2.3160 e-53 log_M1SL -3.3023 0.53185 -6.209 3.914e-09 log_M2SL -1.3845 1.0438 -1.3264 0.18647 log_PCEC -7.143 3.4302 -2.0824 0.038799F-statistic vs. constant model: 292, p-value = 2.26e-109 isig = 1x4 cell array {'log_CPIAUCSL'} {'log_GS10'} {'log_M2SL'} {'FEDFUNDS'}
SLRMdlFull是一个线性模型模型对象P-数值表明,在5%的显著性水平下,CPIAUCSL,GS10,M2SL和联邦基金这些都是无关紧要的变量。
重新装上线性模型没有预测数据的显着变量。使用完全和简化模型,预测失业率到预测范围,则估计FMSEs。
idxreduced =〜ismember(predictornames,isInSig);XReduced = X(:,idxreduced);SLRMdlReduced = fitlm(XReduced,Y,“VarNames”,[Predictor名称(idxreduced){'UNRATE'}]);yFSLRF =预测(SLRMdlFull,XF);yFSLRR =预测(SLRMdlReduced,XF(:,idxreduced));fmseSLRF = SQRT(均值((YF - 。yFSLRF)^ 2))fmseSLRR = SQRT(均值((YF - 。yFSLRR)^ 2))
fmseSLRF=0.6674 fmseSLRR=0.6105
简化模型的FMSE小于全模型的FMSE,表明简化模型具有更好的泛化能力。
适合频率拉索回归模型
将套索回归模型拟合到数据。使用默认正则化路径。套索默认情况下,标准化的数据。由于变量是类似的尺度,不规范他们。返回有关沿着正规化路径的千篇一律的信息。
[LassoBetaEstimates,FitInfo] =套索(X,Y,“标准化”错误的...“预测器名称”, predictornames);
默认情况下,套索通过使用一系列值来拟合100次lasso回归模型因此LassoBetaEstimates是回归系数估计的13×100矩阵。行对应于中的预测变量X和列对应于值.FitInfo是包括的值的结构(FitInfo。兰姆达),则每次拟合的均方误差(FitInfo.MSE),以及估计的截取量(截取).
计算由返回的每个模型的FMSE套索.
yFLasso=FitInfo.Intercept+XF*LassObetae估计值;Fmelasso=sqrt(平均值((yF-yFLasso)。^2,1));
绘制回归系数相对于收缩值的幅度。
hax = lassoPlot (LassoBetaEstimates FitInfo);L1Vals = hax.Children.XData;yyaxis正当h=绘图(L1VAL,Fmso,'行宽'2,'linestyle','--');图例(H,“FMSE”,“位置”,“西南”);ylabel (“FMSE”);标题(“常客套索”)

7个预测(DF = 7)的模型,似乎平衡最小FMSE和模型的复杂性良好。获得对应于含有7个预测并产生最小FMSE模型中的系数。
fmsebestlasso=min(fmseLasso(FitInfo.DF==7));idx=fmseLasso==fmsebestlasso;bestLasso=[FitInfo.Intercept(idx);LassoBetaEstimates(:,idx)];表格(bestLasso,“RowNames”,[“拦截”predictornames])
ans = 14x1 table bestLasso _________ Intercept 61.154 log_COE 0.042061 log_CPIAUCSL 0 log_GCE 0 log_GDP 0 log_GDPDEF 8.524 log_GPDI 0 log_GS10 1.6957 log_HOANBS -18.937 log_M1SL -1.3365 log_M2SL 0.17948 log_PCEC 0
该频率论套索分析表明,变量CPIAUCSL,格索,GDP.,GPDI,PCEC和联邦基金要么微不足道,要么多余。
拟合贝叶斯套索回归模型
在套索回归的贝叶斯视图,回归系数的先验分布是拉普拉斯(双指数),均值为0,比例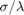 , 在哪里是固定收缩参数,并且
, 在哪里是固定收缩参数,并且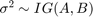 .有关详细信息,请参见
.有关详细信息,请参见lassoblm.
就像套索回归的常客观点一样,如果你增加,然后将得到的模型的稀疏性单调增加。然而,不同于频率论套索,贝叶斯套索具有不完全为0。相反,估计有一个后验分布和不显着的或冗余的,如果周围0区域具有高密度微不足道的或冗余的系数模式。
在MATLAB®中实现贝叶斯套索回归时,请注意统计和机器学习工具箱之间的一些差异™ 作用套索和计量经济学工具箱™对象lassoblm及其相关功能。
lassoblm是对象框架的一部分吗套索是一个函数。对象框架简化了计量经济学工作流程。不像
套索,lassoblm不标准化预测数据。但是,可以为每个系数提供不同的收缩值。此功能有助于保持系数估计值的可解释性。lassoblm将一个收缩值应用于每个系数;它不接受类似的正则化路径套索.
由于lassoblm框架适用于对每个系数的一个收缩值执行贝叶斯套索回归,您可以使用for循环在正则化路径上执行套索。
使用创建贝叶斯套索回归先验模型贝斯姆. 指定预测变量的数量和变量名称。显示存储在中的每个系数的默认收缩值兰姆达模型的属性。
PriorMdl = bayeslm (p,“模型类型”,“套索”,“VarNames”,预测器名称);表(PriorMdl.Lambda,“RowNames”PriorMdl.VarNames)
ans = 14x1 table Var1 ____ Intercept 0.01 log_COE 1 log_CPIAUCSL 1 log_GCE 1 log_GDP 1 log_GDPDEF 1 log_GPDI 1 log_GS10 1 log_HOANBS 1 log_M1SL 1 log_M2SL 1 log_PCEC 1 fefunds 1 TB3MS 1
PriorMdl是一个lassoblm模型对象。lassoblm收缩属性1.对于每个系数,截距除外,截距的收缩率为0.01.这些默认值可能不是在大多数应用中;最好的做法是有许多值进行试验。
考虑返回的正则化路径套索.将收缩值膨胀一倍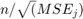 , 在哪里
, 在哪里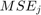 套索的最小均方误差是多少
套索的最小均方误差是多少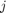 ,通过收缩值的数量=1。
,通过收缩值的数量=1。
ISMISSING =任何(isnan(X),2);N =总和(〜ISMISSING);%有效样本量lambda=FitInfo.lambda*n./sqrt(FitInfo.MSE);
考虑返回的正则化路径套索.在每次迭代时循环收缩值:
估计回归系数的后验分布和干扰方差,给定收缩和数据。因为预测器的规模是接近的,attribute相同的收缩到每个预测器,并attribute收缩
0.01到拦截。保存后的手段和95%置信区间。套索情节,如果95%的可信区间包括0,则对应的后验均值设置为零。
预测进入预测范围。
估计FMSE。
numlambda=numel(λ);%预先分配Bayeslasscoefficients=zeros(p+1,numlambda);Bayeslasscoci95=zeros(p+1,2,numlambda);fmseBayesLasso=zeros(numlambda,1);BLCPlot=zeros(p+1,numlambda);%估计和预测RNG(10);%用于重现对于j=1:numlambda PriorMdl.Lambda=Lambda(j);[EstMdl,Summary]=估计值(PriorMdl,X,y,'展示',false);Bayeslasscoefficients(:,j)=Summary.Mean(1:,end-1));BLCPlot(:,j)=Summary.Mean(1:,end-1));Bayeslasscocients(:,j)=Summary.CI95(1:,end-1),;idx=Bayeslasscoci95(:,end-1,j)<=0;BLCPlot(idx,j)=0;yFBayesLasso=forecast(EstMdl,XF);Fmsebayeslassaso(j)=sqrt(Mean)(Mean)(yF-yF));Bayeso;终止
在每次迭代中,估计运行吉布斯采样器,从完整的条件句(见解析可处理后验概率),并返回empiricalblm模型EstMdl,其中包含绘图和估算汇总表概括。您可以指定Gibbs采样器的参数,例如绘制数或细化方案。
一个好的做法是通过检查示踪图来诊断后验样本。但是,由于绘制了100个分布,因此本示例继续执行该步骤。
绘制系数相对于归一化L1惩罚的后验均值(除截距外的系数的大小之和)。在同一个图上,但是在右y轴上,画出fms。
L1Vals =总和(绝对值(BLCPlot(2:端,:)),1)/最高(总和(ABS(BLCPlot(2:端,:)),1));图形情节(L1Vals,BLCPlot(2:端,:))xlabel(“L1”);ylabel (的系数估计);YY轴正当H =情节(L1Vals,fmseBayesLasso,'行宽'2,'linestyle','--');图例(H,“FMSE”,“位置”,“西南”);ylabel (“FMSE”);标题(“贝叶斯套索”)

当归一化L1惩罚超过0.1时,模型趋向于更好地泛化。为了平衡最小的FMSE和模型复杂性,选择最简单的模型,使FMSE接近0.68。
idx=find(FmSebayesSlasso>0.68,1);fmseBayesLasso=FmSebayesSlasso(idx);bestBayesLasso=BayesLasso效率(:,idx);bestCI95=BayesLassoCI95(:,:,idx);table(bestBayesLasso,bestCI95,“RowNames”,[“拦截”predictornames])
ans = 14x2 table bestBayesLasso bestCI95 ______________ ______________________ Intercept 90.587 79.819 101.62 log_COE 6.5591 1.8093 11.239 log_CPIAUCSL -2.2971 -6.9019 1.7057 log_GCE -5.1707 -7.4902 -2.8583 log_GDP 9.8839 2.3848 17.672 log_GDPDEF-32.538 -35.589 -29.526 log_M1SL -3.0656 -4.1499 -2.0066 log_M2SL -1.1007 -3.1243 0.5844 log_PCEC -3.3342 -9.6496 1.8482
以确定是否变量是微不足道的或冗余的一种方式是通过检查是否0处于其相应系数95%的可信区间。使用该标准,CPIAUCSL,M2SL,PCEC和联邦基金是无关紧要的。
在表格中显示所有估计值以供比较。
SLRR=0(p+1,1);SLRR([true idxreduced])=SLRMdlReduced.coverties.Estimate;table([SLRMdlFull.coverties.Estimate;fmseslr],...[SLRR;fmseSLRR],...[最佳套索;最佳套索],...[bestBayesLasso;fmsebestbayeslasso],“VariableNames”,...{'SLRFull'“SLRReduced”'套索'“贝斯拉索”},...“RowNames”,[PriorMdl.VarNames;'MSE'])
ANS = 15x4表SLRFull SLRReduced套索BayesLasso ________ __________ ________ __________截取88.014 88.327 61.154 90.587 log_COE 7.1111 10.854 0.042061 6.5591 log_CPIAUCSL -3.4032 0 0 -2.2971 log_GCE -5.63 -6.1958 0 -5.1707 log_GDP 14.522 16.701 0 9.8839 log_GDPDEF 11.926 9.1106 8.524 10.281 log_GPDI -2.5939-2.6963 0 -2.0973 log_GS10 0.57467 0 1.6957 0.82485 log_HOANBS -32.861 -33.782 -18.937 -32.538 log_M1SL -3.3023 -2.8099 -1.3365 -3.0656 -1.3845 log_M2SL 0 0.17948 -1.1007 log_PCEC -7.143 -14.207 0 -3.3342 FEDFUNDS 0.044542 0 0 0.043672 TB3MS -0.1577 -0.078449 -0.14459 -0.15682 MSE 0.61048 0.61048 0.79425 0.69639
选择模型后,使用整个数据集对其进行重新估计。例如,要创建预测性贝叶斯套索回归模型,请创建一个先验模型,并指定产生最小FMSE的最简单模型的收缩率,然后使用整个数据集对其进行估计。
bestLambda=lambda(idx);PriorMdl=bayeslm(p,“模型类型”,“套索”,“拉姆达”,bestLambda,...“VarNames”,predictor name);后验概率mdl=估计值(PriorMdl[X;XF],[y;yF]);
方法:lasso MCMC抽样10000次,观察次数:201个预测数:14 |平均Std CI95正分布----------------------------------------------------------------------截距| 85.9643 5.2710[75.544,96.407]1.000经验对数| 12.3574 2.1817[8.001,16.651]1.000经验对数| 0.14981.9150[-3.733,4.005]0.525经验对数|-7.1850 1.0556[-9.208,-5.101]0.000经验对数| 11.8648 3.9955[4.111,19.640]0.999经验对数| GDPDEF 8.8777 2.4221[4.033,13.745]1.000经验对数1240GPDI-2.84-10.690][0.194,1.197]0.997经验对数|-32.3356 1.4941[-35.276,-29.433]0.000经验对数|-2.2279 0.5043[-3.202,-1.238]0.000经验对数| 0.3617 0.9123[-1.438,2.179]0.652经验对数|-11.3018 3.0353[-17.318,-1.252 0.000经验对数1240.040]0.392经验TB3MS |-0.1128 0.0660[-0.244,0.016]0.042经验Sigma2 | 0.1186 0.0122[0.097,0.145]1.000经验
另见
相关的话题
您还可以从以下列表中选择网站:
