预测gydF4y2Ba
贝叶斯线性回归模型的预测的反应gydF4y2Ba
语法gydF4y2Ba
描述gydF4y2Ba
yFgydF4y2Ba=预测(gydF4y2BaMdlgydF4y2Ba,gydF4y2BaXFgydF4y2Ba)gydF4y2BanumPeriodsgydF4y2Ba预测的反应gydF4y2Ba贝叶斯线性回归模型gydF4y2BaMdlgydF4y2Ba考虑到预测的数据gydF4y2BaXFgydF4y2Ba,一个矩阵gydF4y2BanumPeriodsgydF4y2Ba行。gydF4y2Ba
估计预测,gydF4y2Ba预测gydF4y2Ba使用的均值gydF4y2BanumPeriodsgydF4y2Ba维后预测分布。gydF4y2Ba
如果gydF4y2Ba
MdlgydF4y2Ba之前是一个联合模型(返回的gydF4y2BabayeslmgydF4y2Ba),然后gydF4y2Ba预测gydF4y2Ba只使用联合先验分布和形成的创新分布预测分布。gydF4y2Ba如果gydF4y2Ba
MdlgydF4y2Ba是一个后模型(返回的gydF4y2Ba估计gydF4y2Ba),然后gydF4y2Ba预测gydF4y2Ba使用后的预测分布。gydF4y2Ba
南gydF4y2Ba在数据显示缺失值,gydF4y2Ba预测gydF4y2Ba使用list-wise删除删除。gydF4y2Ba
yFgydF4y2Ba=预测(gydF4y2BaMdlgydF4y2Ba,gydF4y2BaXFgydF4y2Ba,gydF4y2BaXgydF4y2Ba,gydF4y2BaygydF4y2Ba)gydF4y2BaXgydF4y2Ba和相应的响应数据gydF4y2BaygydF4y2Ba。gydF4y2Ba
如果gydF4y2Ba
MdlgydF4y2Ba之前是一个联合模型,然后呢gydF4y2Ba预测gydF4y2Ba生产前通过更新后的预测分布模型的参数,得到的信息数据。gydF4y2Ba如果gydF4y2Ba
MdlgydF4y2Ba是一个后模型呢gydF4y2Ba预测gydF4y2Ba更新后验信息参数,获得额外的数据。完整的数据可能是由额外的数据gydF4y2BaXgydF4y2Ba和gydF4y2BaygydF4y2Ba,创建的数据gydF4y2BaMdlgydF4y2Ba。gydF4y2Ba
yFgydF4y2Ba=预测(gydF4y2Ba___gydF4y2Ba,gydF4y2Ba名称,值gydF4y2Ba)gydF4y2Ba
(gydF4y2Ba还返回的协方差矩阵gydF4y2BayFgydF4y2Ba,gydF4y2BaYFCovgydF4y2Ba)=预测(gydF4y2Ba___gydF4y2Ba)gydF4y2BanumPeriodsgydF4y2Ba维后预测分布。标准差的预测是对角线的根元素。gydF4y2Ba
例子gydF4y2Ba
使用后预测分布预测的反应gydF4y2Ba
考虑的多元线性回归模型预测美国实际国民生产总值(gydF4y2BaGNPRgydF4y2Ba)使用工业生产指数的线性组合gydF4y2Ba新闻学会gydF4y2Ba)、就业总人数(gydF4y2BaEgydF4y2Ba),实际工资(gydF4y2Ba或者说是gydF4y2Ba)。gydF4y2Ba
对所有gydF4y2Ba ,gydF4y2Ba 是一系列的独立和0的均值和方差高斯干扰吗gydF4y2Ba 。gydF4y2Ba
假设这些先验分布:gydF4y2Ba
。gydF4y2Ba 意味着是一个4-by-1向量,gydF4y2Ba 是一个按比例缩小的4×4正定协方差矩阵。gydF4y2Ba
。gydF4y2Ba 和gydF4y2Ba 分别是形状和规模的逆伽马分布。gydF4y2Ba
这些假设和数据可能意味着normal-inverse-gamma共轭模型。gydF4y2Ba
创建一个normal-inverse-gamma共轭先验模型的线性回归参数。指定数量的预测gydF4y2BapgydF4y2Ba和变量名。gydF4y2Ba
p = 3;VarNames = [gydF4y2Ba“他们”gydF4y2Ba“E”gydF4y2Ba“福”gydF4y2Ba];PriorMdl = bayeslm (p,gydF4y2Ba“ModelType”gydF4y2Ba,gydF4y2Ba“共轭”gydF4y2Ba,gydF4y2Ba“VarNames”gydF4y2Ba,VarNames);gydF4y2Ba
MdlgydF4y2Ba是一个gydF4y2BaconjugateblmgydF4y2Ba贝叶斯线性回归模型对象代表回归系数的先验分布和扰动方差。gydF4y2Ba
加载Nelson-Plosser数据集。创建变量预测和响应数据。坚持过去10期的数据估计,这样你可以使用它们来预测实际国民生产总值。gydF4y2Ba
负载gydF4y2BaData_NelsonPlossergydF4y2Bafhs = 10;gydF4y2Ba%预测地平线大小gydF4y2BaX = DataTable{1:(结束- fhs), PriorMdl.VarNames(2:结束)};y = DataTable{1:(结束- fhs),gydF4y2Ba“GNPR”gydF4y2Ba};XF = DataTable{(结束- fhs + 1):最终,PriorMdl.VarNames(2:结束)};gydF4y2Ba%未来的预测数据gydF4y2BayFT = DataTable{(结束- fhs + 1):结束,gydF4y2Ba“GNPR”gydF4y2Ba};gydF4y2Ba%未来真实的反应gydF4y2Ba
估计边缘后验分布。关掉估计显示。gydF4y2Ba
PosteriorMdl =估计(PriorMdl, X, y,gydF4y2Ba“显示”gydF4y2Ba、假);gydF4y2Ba
PosteriorMdlgydF4y2Ba是一个gydF4y2BaconjugateblmgydF4y2Ba模型对象,其中包含的后验分布gydF4y2Ba
和gydF4y2Ba
。gydF4y2Ba
预测使用后反应预测分布和未来预测数据gydF4y2BaXFgydF4y2Ba。情节的真实值响应和预测的值。gydF4y2Ba
yF =预测(PosteriorMdl XF);图;情节(日期、DataTable.GNPR);持有gydF4y2Ba在gydF4y2Ba情节(日期((结束- fhs + 1):结束),yF h = gca;p =补丁([日期(结束- fhs + 1)日期(结束)日期(结束)日期(结束- fhs + 1)),gydF4y2Ba…gydF4y2Bah.YLim ([1, 1、2、2]), [0.8 0.8 0.8]);uistack (p,gydF4y2Ba“底”gydF4y2Ba);传奇(gydF4y2Ba“预测地平线”gydF4y2Ba,gydF4y2Ba“真正的GNPR”gydF4y2Ba,gydF4y2Ba“预测GNPR”gydF4y2Ba,gydF4y2Ba“位置”gydF4y2Ba,gydF4y2Ba“西北”gydF4y2Ba)标题(gydF4y2Ba“真正的国民生产总值:1909 - 1970”gydF4y2Ba);ylabel (gydF4y2Ba“rGNP”gydF4y2Ba);包含(gydF4y2Ba“年”gydF4y2Ba);持有gydF4y2Ba从gydF4y2Ba
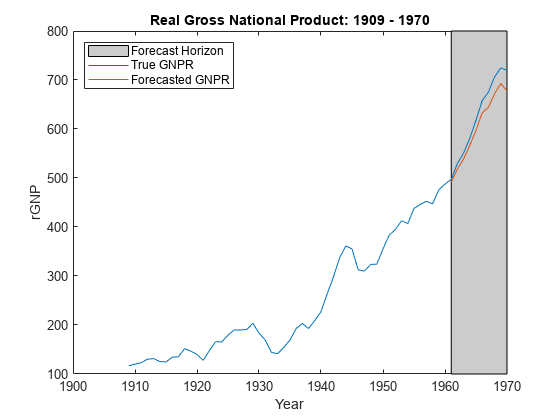
yFgydF4y2Ba是一个10-by-1向量的值相对应的实际国民生产总值未来预测数据。gydF4y2Ba
估计预测均方误差(RMSE)。gydF4y2Ba
frmse =√意味着(yF - yFT) ^ 2))gydF4y2Ba
frmse = 25.5397gydF4y2Ba
预测均方根误差是一个相对程度的预测精度。具体地说,您估计几个使用不同的假设模型。最低的模型预测的RMSE是表现最好的模型相比较。gydF4y2Ba
使用后直接预测观测gydF4y2Ba
考虑的回归模型gydF4y2Ba使用后预测分布预测的反应gydF4y2Ba。gydF4y2Ba
创建一个normal-inverse-gamma semiconjugate之前线性回归模型参数。指定数量的预测gydF4y2BapgydF4y2Ba和回归系数的名称。gydF4y2Ba
p = 3;PriorMdl = bayeslm (p,gydF4y2Ba“ModelType”gydF4y2Ba,gydF4y2Ba“semiconjugate”gydF4y2Ba,gydF4y2Ba“VarNames”gydF4y2Ba,(gydF4y2Ba“他们”gydF4y2Ba“E”gydF4y2Ba“福”gydF4y2Ba]);gydF4y2Ba
加载Nelson-Plosser数据集。为响应和预测系列创建变量。gydF4y2Ba
负载gydF4y2BaData_NelsonPlossergydF4y2BaX = DataTable {: PriorMdl.VarNames(2:结束)};y = DataTable {:,gydF4y2Ba“GNPR”gydF4y2Ba};gydF4y2Ba
坚持过去10期的数据估计,这样你可以使用它们来预测实际国民生产总值。关掉估计显示。gydF4y2Ba
fhs = 10;gydF4y2Ba%预测地平线大小gydF4y2BaX = DataTable{1:(结束- fhs), PriorMdl.VarNames(2:结束)};y = DataTable{1:(结束- fhs),gydF4y2Ba“GNPR”gydF4y2Ba};XF = DataTable{(结束- fhs + 1):最终,PriorMdl.VarNames(2:结束)};gydF4y2Ba%未来的预测数据gydF4y2BayFT = DataTable{(结束- fhs + 1):结束,gydF4y2Ba“GNPR”gydF4y2Ba};gydF4y2Ba%未来真实的反应gydF4y2Ba
预测使用后反应预测分布和未来预测数据gydF4y2BaXFgydF4y2Ba。指定样本的观察gydF4y2BaXgydF4y2Ba和gydF4y2BaygydF4y2Ba(MATLAB®组成的观察后)。gydF4y2Ba
yF =预测(PriorMdl XF, X, y)gydF4y2Ba
yF =gydF4y2Ba10×1gydF4y2Ba491.5404 518.1725 539.0625 566.7594 597.7005 633.4666 644.7270 672.7937 693.5321 678.2268gydF4y2Ba
预测反应后执行预测变量的选择gydF4y2Ba
考虑的回归模型gydF4y2Ba使用后预测分布预测的反应gydF4y2Ba。gydF4y2Ba
假设这些先验分布gydF4y2Ba = 0,…,3:gydF4y2Ba
,在那里gydF4y2Ba 和gydF4y2Ba 是独立的,标准正态随机变量。因此,系数高斯混合分布。假定所有系数是条件独立的,先天的,但它们依赖于扰动方差。gydF4y2Ba
。gydF4y2Ba 和gydF4y2Ba 分别是形状和规模的逆伽马分布。gydF4y2Ba
,它代表了随机variable-inclusion政权变量离散均匀分布。gydF4y2Ba
执行随机搜索变量选择(科学):gydF4y2Ba
创建一个贝叶斯回归模型对于科学的共轭先验数据的可能性。使用默认设置。gydF4y2Ba
坚持过去10期从估计的数据。gydF4y2Ba
估计边缘后验分布。gydF4y2Ba
p = 3;PriorMdl = bayeslm (p,gydF4y2Ba“ModelType”gydF4y2Ba,gydF4y2Ba“mixconjugate”gydF4y2Ba,gydF4y2Ba“VarNames”gydF4y2Ba,(gydF4y2Ba“他们”gydF4y2Ba“E”gydF4y2Ba“福”gydF4y2Ba]);负载gydF4y2BaData_NelsonPlossergydF4y2Bafhs = 10;gydF4y2Ba%预测地平线大小gydF4y2BaX = DataTable{1:(结束- fhs), PriorMdl.VarNames(2:结束)};y = DataTable{1:(结束- fhs),gydF4y2Ba“GNPR”gydF4y2Ba};XF = DataTable{(结束- fhs + 1):最终,PriorMdl.VarNames(2:结束)};gydF4y2Ba%未来的预测数据gydF4y2BayFT = DataTable{(结束- fhs + 1):结束,gydF4y2Ba“GNPR”gydF4y2Ba};gydF4y2Ba%未来真实的反应gydF4y2Barng (1);gydF4y2Ba%的再现性gydF4y2BaPosteriorMdl =估计(PriorMdl, X, y,gydF4y2Ba“显示”gydF4y2Ba、假);gydF4y2Ba
预测使用后反应预测分布和未来预测数据gydF4y2BaXFgydF4y2Ba。情节的真实值响应和预测的值。gydF4y2Ba
yF =预测(PosteriorMdl XF);图;情节(日期、DataTable.GNPR);持有gydF4y2Ba在gydF4y2Ba情节(日期((结束- fhs + 1):结束),yF h = gca;惠普=补丁([日期(结束- fhs + 1)日期(结束)日期(结束)日期(结束- fhs + 1)),gydF4y2Ba…gydF4y2Bah.YLim ([1, 1、2、2]), [0.8 0.8 0.8]);uistack(惠普、gydF4y2Ba“底”gydF4y2Ba);传奇(gydF4y2Ba“预测地平线”gydF4y2Ba,gydF4y2Ba“真正的GNPR”gydF4y2Ba,gydF4y2Ba“预测GNPR”gydF4y2Ba,gydF4y2Ba“位置”gydF4y2Ba,gydF4y2Ba“西北”gydF4y2Ba)标题(gydF4y2Ba“真正的国民生产总值:1909 - 1970”gydF4y2Ba);ylabel (gydF4y2Ba“rGNP”gydF4y2Ba);包含(gydF4y2Ba“年”gydF4y2Ba);持有gydF4y2Ba从gydF4y2Ba
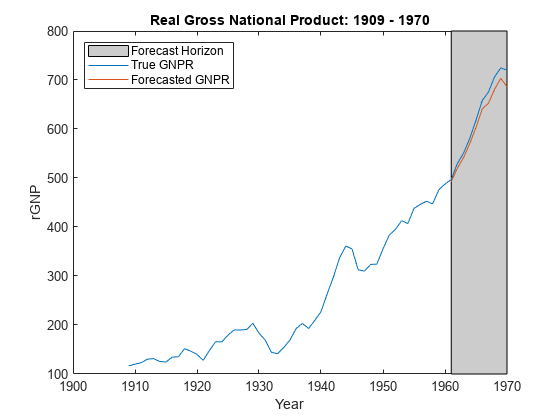
yFgydF4y2Ba是一个10-by-1向量的值相对应的实际国民生产总值未来预测数据。gydF4y2Ba
估计预测均方误差(RMSE)。gydF4y2Ba
frmse =√意味着(yF - yFT) ^ 2))gydF4y2Ba
frmse = 18.8470gydF4y2Ba
预测均方根误差是一个相对程度的预测精度。具体地说,您估计几个使用不同的假设模型。最低的模型预测的RMSE是表现最好的模型相比较。gydF4y2Ba
当您执行贝叶斯与科学价值回归,一个最佳实践是优化hyperparameters。这样做的方法之一是估计预测RMSE hyperparameter值的网格,并选择预测RMSE值最小化。gydF4y2Ba
使用条件后预测分布预测的反应gydF4y2Ba
考虑的回归模型gydF4y2Ba使用后预测分布预测的反应gydF4y2Ba。gydF4y2Ba
创建一个normal-inverse-gamma semiconjugate之前线性回归模型参数。指定数量的预测gydF4y2BapgydF4y2Ba和回归系数的名称。gydF4y2Ba
p = 3;PriorMdl = bayeslm (p,gydF4y2Ba“ModelType”gydF4y2Ba,gydF4y2Ba“semiconjugate”gydF4y2Ba,gydF4y2Ba“VarNames”gydF4y2Ba,(gydF4y2Ba“他们”gydF4y2Ba“E”gydF4y2Ba“福”gydF4y2Ba]);gydF4y2Ba
加载Nelson-Plosser数据集。为响应和预测系列创建变量。gydF4y2Ba
负载gydF4y2BaData_NelsonPlossergydF4y2BaX = DataTable {: PriorMdl.VarNames(2:结束)};y = DataTable {:,gydF4y2Ba“GNPR”gydF4y2Ba};gydF4y2Ba
坚持过去10期的数据估计,这样你可以使用它们来预测实际国民生产总值。关掉估计显示。gydF4y2Ba
fhs = 10;gydF4y2Ba%预测地平线大小gydF4y2BaX = DataTable{1:(结束- fhs), PriorMdl.VarNames(2:结束)};y = DataTable{1:(结束- fhs),gydF4y2Ba“GNPR”gydF4y2Ba};XF = DataTable{(结束- fhs + 1):最终,PriorMdl.VarNames(2:结束)};gydF4y2Ba%未来的预测数据gydF4y2BayFT = DataTable{(结束- fhs + 1):结束,gydF4y2Ba“GNPR”gydF4y2Ba};gydF4y2Ba%未来真实的反应gydF4y2Ba
预测反应通过使用测试版的条件后预测分布gydF4y2Ba
和使用未来的预测数据gydF4y2BaXFgydF4y2Ba。指定样本的观察gydF4y2BaXgydF4y2Ba和gydF4y2BaygydF4y2Ba(MATLAB®组成的观察后)。情节的真实值响应和预测的值。gydF4y2Ba
yF =预测(PriorMdl XF, X, y,gydF4y2Ba“Sigma2”gydF4y2Ba2);图;情节(日期、DataTable.GNPR);持有gydF4y2Ba在gydF4y2Ba情节(日期((结束- fhs + 1):结束),yF h = gca;惠普=补丁([日期(结束- fhs + 1)日期(结束)日期(结束)日期(结束- fhs + 1)),gydF4y2Ba…gydF4y2Bah.YLim ([1, 1、2、2]), [0.8 0.8 0.8])gydF4y2Ba
惠普=补丁的属性:FaceColor: [0.8000 0.8000 0.8000] FaceAlpha: 1 EdgeColor:[0 0 0]线型:”——“脸:(1 2 3 4)顶点:[4 x2双]显示所有属性gydF4y2Ba
uistack(惠普、gydF4y2Ba“底”gydF4y2Ba);传奇(gydF4y2Ba“预测地平线”gydF4y2Ba,gydF4y2Ba“真正的GNPR”gydF4y2Ba,gydF4y2Ba“预测GNPR”gydF4y2Ba,gydF4y2Ba“位置”gydF4y2Ba,gydF4y2Ba“西北”gydF4y2Ba)标题(gydF4y2Ba“真正的国民生产总值:1909 - 1970”gydF4y2Ba);ylabel (gydF4y2Ba“rGNP”gydF4y2Ba);包含(gydF4y2Ba“年”gydF4y2Ba);持有gydF4y2Ba从gydF4y2Ba
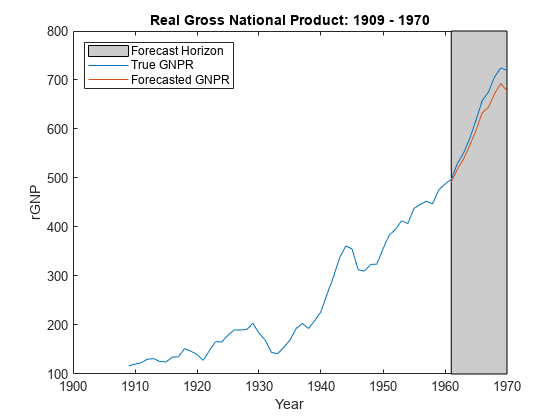
估计预测区间gydF4y2Ba
考虑的回归模型gydF4y2Ba使用后预测分布预测的反应gydF4y2Ba。gydF4y2Ba
创建一个normal-inverse-gamma semiconjugate之前线性回归模型参数。指定数量的预测gydF4y2BapgydF4y2Ba和回归系数的名称。gydF4y2Ba
p = 3;PriorMdl = bayeslm (p,gydF4y2Ba“ModelType”gydF4y2Ba,gydF4y2Ba“semiconjugate”gydF4y2Ba,gydF4y2Ba“VarNames”gydF4y2Ba,(gydF4y2Ba“他们”gydF4y2Ba“E”gydF4y2Ba“福”gydF4y2Ba]);gydF4y2Ba
加载Nelson-Plosser数据集。为响应和预测系列创建变量。gydF4y2Ba
负载gydF4y2BaData_NelsonPlossergydF4y2BaX = DataTable {: PriorMdl.VarNames(2:结束)};y = DataTable {:,gydF4y2Ba“GNPR”gydF4y2Ba};gydF4y2Ba
坚持过去10期的数据估计,这样你可以使用它们来预测实际国民生产总值。关掉估计显示。gydF4y2Ba
fhs = 10;gydF4y2Ba%预测地平线大小gydF4y2BaX = DataTable{1:(结束- fhs), PriorMdl.VarNames(2:结束)};y = DataTable{1:(结束- fhs),gydF4y2Ba“GNPR”gydF4y2Ba};XF = DataTable{(结束- fhs + 1):最终,PriorMdl.VarNames(2:结束)};gydF4y2Ba%未来的预测数据gydF4y2BayFT = DataTable{(结束- fhs + 1):结束,gydF4y2Ba“GNPR”gydF4y2Ba};gydF4y2Ba%未来真实的反应gydF4y2Ba
预测使用后反应及其协方差矩阵预测分布和未来预测数据gydF4y2BaXFgydF4y2Ba。指定样本的观察gydF4y2BaXgydF4y2Ba和gydF4y2BaygydF4y2Ba(MATLAB®组成的观察后)。gydF4y2Ba
[yF, YFCov] =预测(PriorMdl XF, X, y);gydF4y2Ba
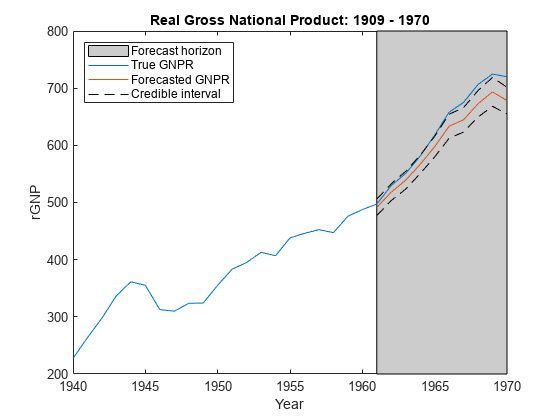
因为预测后验分布不是分析,合理的近似一组的95%置信区间gydF4y2Ba
对所有gydF4y2Ba 在预测地平线。估计95%的可信区间预测使用这个公式。gydF4y2Ba
n =总和(所有(~ isnan ((X, y))));cil = yF - norminv (0.975) * sqrt(诊断接头(YFCov));ciu = yF + norminv (0.975) * sqrt(诊断接头(YFCov));gydF4y2Ba
图数据、预测和预报区间。gydF4y2Ba
图;情节(日期(end-30:结束),DataTable.GNPR (end-30:结束));持有gydF4y2Ba在gydF4y2Ba甘氨胆酸h =;情节(日期((结束- fhs + 1):结束),yF情节(日期((结束- fhs + 1):结束),(cil ciu),gydF4y2Ba“k——”gydF4y2Ba)惠普=补丁([日期(结束- fhs + 1)日期(结束)日期(结束)日期(结束- fhs + 1)),gydF4y2Ba…gydF4y2Bah.YLim ([1, 1、2、2]), [0.8 0.8 0.8]);uistack(惠普、gydF4y2Ba“底”gydF4y2Ba);传奇(gydF4y2Ba“预测地平线”gydF4y2Ba,gydF4y2Ba“真正的GNPR”gydF4y2Ba,gydF4y2Ba“预测GNPR”gydF4y2Ba,gydF4y2Ba…gydF4y2Ba可信区间的gydF4y2Ba,gydF4y2Ba“位置”gydF4y2Ba,gydF4y2Ba“西北”gydF4y2Ba)标题(gydF4y2Ba“真正的国民生产总值:1909 - 1970”gydF4y2Ba);ylabel (gydF4y2Ba“rGNP”gydF4y2Ba);包含(gydF4y2Ba“年”gydF4y2Ba);持有gydF4y2Ba从gydF4y2Ba
输入参数gydF4y2Ba
输出参数gydF4y2Ba
限制gydF4y2Ba
如果gydF4y2BaMdlgydF4y2Ba是一个gydF4y2BaempiricalblmgydF4y2Ba模型对象,那么你不能指定gydF4y2BaβgydF4y2Ba或gydF4y2BaSigma2gydF4y2Ba。你不能预测预测分布条件下从使用实证先验分布。gydF4y2Ba
更多关于gydF4y2Ba
提示gydF4y2Ba
蒙特卡罗模拟是可能变更。如果gydF4y2Ba
预测gydF4y2Ba使用蒙特卡罗模拟,那么当你叫估计和推断可能有所不同gydF4y2Ba预测gydF4y2Ba在看似同等条件下多次。复制估算结果,设置一个随机数种子通过使用gydF4y2BarnggydF4y2Ba在调用之前gydF4y2Ba预测gydF4y2Ba。gydF4y2Ba如果gydF4y2Ba
预测gydF4y2Ba问题一个错误而估计后验分布使用自定义模型之前,然后试着调整初始参数值通过使用gydF4y2BaBetaStartgydF4y2Ba或gydF4y2BaSigma2StartgydF4y2Ba之前,或者尝试调整宣布日志功能,然后重构模型。错误可能表明日志的先验分布gydF4y2Ba负gydF4y2Ba在指定的初始值。gydF4y2Ba条件后预测分布的预测响应分析的模型,除了经验模型,通过模型对象和estimation-sample数据之前gydF4y2Ba
预测gydF4y2Ba。然后,指定gydF4y2BaβgydF4y2Ba名称-值对参数预测的条件后gydF4y2BaσgydF4y2Ba2gydF4y2Ba,或指定gydF4y2BaSigma2gydF4y2Ba名称-值对参数预测的条件后gydF4y2BaβgydF4y2Ba。gydF4y2Ba
算法gydF4y2Ba
每当gydF4y2Ba
预测gydF4y2Ba必须估计后验分布(例如,当gydF4y2BaMdlgydF4y2Ba代表一个先验分布,你供应gydF4y2BaXgydF4y2Ba和gydF4y2BaygydF4y2Ba)和后易于分析,gydF4y2Ba预测gydF4y2Ba评估封闭解决贝叶斯估计。金宝搏官方网站否则,gydF4y2Ba预测gydF4y2Ba诉诸蒙特卡罗模拟使用后预测分布预测。更多细节,请参阅gydF4y2Ba后估计和推断gydF4y2Ba。gydF4y2Ba这个数字说明了gydF4y2Ba
预测gydF4y2Ba减少了蒙特卡罗示例使用的值gydF4y2BaNumDrawsgydF4y2Ba,gydF4y2Ba薄gydF4y2Ba,gydF4y2Ba燃烧gydF4y2Ba。矩形表示连续分布的吸引。gydF4y2Ba预测gydF4y2Ba删除蒙特卡罗采样的白色矩形。剩下的gydF4y2BaNumDrawsgydF4y2Ba黑色的矩形组成蒙特卡罗抽样。gydF4y2Ba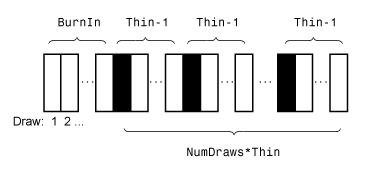

另请参阅gydF4y2Ba
对象gydF4y2Ba
conjugateblmgydF4y2Ba|gydF4y2BasemiconjugateblmgydF4y2Ba|gydF4y2BadiffuseblmgydF4y2Ba|gydF4y2BaempiricalblmgydF4y2Ba|gydF4y2BacustomblmgydF4y2Ba|gydF4y2BamixconjugateblmgydF4y2Ba|gydF4y2BamixsemiconjugateblmgydF4y2Ba|gydF4y2BalassoblmgydF4y2Ba
功能gydF4y2Ba
sampleroptionsgydF4y2Ba|gydF4y2Ba估计gydF4y2Ba
主题gydF4y2Ba
你也可以从下面的列表中选择一个网站:gydF4y2Ba
美洲gydF4y2Ba
- 美国拉丁gydF4y2Ba(西班牙语)gydF4y2Ba
- 加拿大gydF4y2Ba(英语)gydF4y2Ba
- 美国gydF4y2Ba(英语)gydF4y2Ba
欧洲gydF4y2Ba
- 比利时gydF4y2Ba(英语)gydF4y2Ba
- 丹麦gydF4y2Ba(英语)gydF4y2Ba
- 德国gydF4y2Ba(德语)gydF4y2Ba
- 西班牙gydF4y2Ba(西班牙语)gydF4y2Ba
- 芬兰gydF4y2Ba(英语)gydF4y2Ba
- 法国gydF4y2Ba(法语)gydF4y2Ba
- 爱尔兰gydF4y2Ba(英语)gydF4y2Ba
- 意大利gydF4y2Ba(意大利语)gydF4y2Ba
- 卢森堡gydF4y2Ba(英语)gydF4y2Ba
- 荷兰gydF4y2Ba(英语)gydF4y2Ba
- 挪威gydF4y2Ba(英语)gydF4y2Ba
- 奥地利gydF4y2Ba(德语)gydF4y2Ba
- 葡萄牙gydF4y2Ba(英语)gydF4y2Ba
- 瑞典gydF4y2Ba(英语)gydF4y2Ba
- 瑞士gydF4y2Ba
- 联合王国gydF4y2Ba(英语)gydF4y2Ba
亚太地区gydF4y2Ba
- 澳大利亚gydF4y2Ba(英语)gydF4y2Ba
- 印度gydF4y2Ba(英语)gydF4y2Ba
- 新西兰gydF4y2Ba(英语)gydF4y2Ba
- 中国gydF4y2Ba
- 日本gydF4y2Ba(日本語)gydF4y2Ba
- 한국gydF4y2Ba(한국어)gydF4y2Ba
