bayeslm
创建贝叶斯线性回归模型对象
语法
描述
要创建用于多元时间序列分析的贝叶斯向量自回归(VARX)模型,请参见bayesvarm.
PriorMdl= bayeslm (NumPredictors)PriorMdl)由NumPredictors预测器,一个截距,和一个扩散,联合先验分布β而且σ2.PriorMdl是定义先验分布和维数的模板吗β.
PriorMdl= bayeslm (NumPredictors,'ModelType”,modelType)modelType为β而且σ2.对于这个语法,modelType可以是:
“共轭”,“semiconjugate”,或“扩散”创建一个标准的贝叶斯线性回归先验模型“mixconjugate”,“mixsemiconjugate”,或“套索”为预测变量选择创建贝叶斯线性回归先验模型
例如,“ModelType”、“共轭”表示高斯似然的共轭先验,即β|σ2为高斯分布,σ2是逆的。
PriorMdl= bayeslm (NumPredictors,'ModelType“modelType,名称,值)modelType.
如果你指定
“ModelType”、“经验”时,还必须指定BetaDraws而且Sigma2Draws名称-值对参数。BetaDraws而且Sigma2Draws描述各自的先验分布。如果你指定
“ModelType”,“自定义”时,还必须指定LogPDF名称-值对参数。LogPDF完全表征了联合先验分布。
例子
默认扩散先验模型
考虑预测美国实际国民生产总值(gdp)的多元线性回归模型(GNPR)采用工业生产指数(新闻学会)、总就业人数(E)和实际工资(或者说是).
对所有 , 是一系列均值为0,方差为0的独立高斯扰动吗 .
假设回归系数 还有扰动方差 为随机变量,其先验值和分布未知。在这种情况下,使用无信息的Jefferys先验:联合先验分布与 .
这些假设和数据似然意味着一个可分析处理的后验分布。
为线性回归参数创建一个扩散先验模型,这是默认的模型类型。指定预测器的数量p.
P = 3;Mdl = bayeslm(p)
Mdl = diffuseblm属性:NumPredictors: 3拦截:1 VarNames: {4 x1细胞}|意味着性病CI95积极的分布 ----------------------------------------------------------------------------- 拦截| 0正(南南)0.500一个β(1)| 0正成正比(南南)0.500一个β(2)| 0正成正比(南南)0.500一个β(3)| 0正成正比(南南)0.500正比于一个Sigma2 |正正(南南)1.000 1 / Sigma2成正比
Mdl是一个diffuseblm贝叶斯线性回归模型对象表示回归系数和扰动方差的先验分布。bayeslm在命令行上显示先前分布的摘要。因为先验是没有信息的,而且模型不包含数据,所以摘要是微不足道的。
如果你有数据,那么你可以通过先验模型来估计后验分布的特征Mdl和数据估计.
正-逆-半共轭先验模型
中的线性回归模型默认扩散先验模型.假设这些先验分布:
. 4 × 1向量的均值是多少 是一个4乘4的正定协方差矩阵。
. 而且 分别是逆伽马分布的形状和比例。
这些假设和数据似然暗示了一个正态-逆伽玛半共轭模型。条件后验在数据似然方面与先验共轭,但边缘后验在分析上是难以处理的。
为线性回归参数创建一个正态-逆伽玛半共轭先验模型。指定预测器的数量p.
P = 3;Mdl = bayeslm(p,“ModelType”,“semiconjugate”)
Mdl =半导体jugateblm与属性:NumPredictors: 3拦截:1 VarNames: {4x1 cell} Mu: [4x1 double] V: [4x4 double] A: 3 B:1 |意味着性病CI95积极的分布 ------------------------------------------------------------------------------- 拦截| 0 100 [-195.996,195.996]0.500 N(0.00、100.00 ^ 2)β(1)| 0 100 [-195.996,195.996]0.500 N(0.00、100.00 ^ 2)β(2)| 0 100 [-195.996,195.996]0.500 N(0.00、100.00 ^ 2)β(3)| 0 100 [-195.996,195.996]0.500 N(0.00、100.00 ^ 2)Sigma2 | 0.5000 - 0.5000[0.138, 1.616] 1.000搞笑(3.00,1)
Mdl是一个semiconjugateblm贝叶斯线性回归模型对象表示回归系数和扰动方差的先验分布。bayeslm在命令行上显示先前分布的摘要。例如,元素积极的表示对应参数为正的先验概率。
如果你有数据,那么你可以通过先验模型来估计边缘或条件后验分布的特征Mdl和数据估计.
法向-逆伽马共轭先验模型的超参数设置
中的线性回归模型默认扩散先验模型.假设这些先验分布:
. 4 × 1向量的均值是多少 是一个4乘4的正定协方差矩阵。假设你有先验知识 V是单位矩阵。
. 而且 分别是逆伽马分布的形状和比例。
这些假设和数据似然暗示了一个正态-逆伽马共轭模型。
为线性回归参数创建一个正态-逆伽马共轭先验模型。指定预测器的数量p并将回归系数名称设置为相应的变量名称。
P = 3;Mdl = bayeslm(p,“ModelType”,“共轭”,“亩”, -20;4;0.1;2),“V”眼睛(4),...“VarNames”, (“他们”“E”“福”])
Mdl =共轭与属性:NumPredictors: 3拦截:1 VarNames: {4x1 cell} Mu: [4x1 double] V: [4x4 double] A: 3 B:1 |意味着性病CI95积极的分布 ---------------------------------------------------------------------------------- 拦截| -20 0.7071 [-21.413,-18.587]0.000 t(-20.00、0.58 ^ 2,6)IPI | 4 0.7071 [2.587, 5.413] 1.000 t E(4.00、0.58 ^ 2,6)| 0.1000 - 0.7071[-1.313,1.513]0.566吨(0.10、0.58 ^ 2,6)WR | 2 0.7071 [0.587, 3.413] 0.993 t(2.00、0.58 ^ 2,6)Sigma2 | 0.5000 - 0.5000[0.138, 1.616] 1.000搞笑(3.00,1)
Mdl是一个conjugateblm贝叶斯线性回归模型对象表示回归系数和扰动方差的先验分布。bayeslm在命令行上显示先前分布的摘要。虽然bayeslm为截距和扰动方差分配名称,所有其他系数都有指定名称。
默认情况下,bayeslm将形状和比例设置为3.而且1,分别。假设你已经知道形状和比例是5而且2.
的先验形状和比例 到他们假设的值。
Mdl。一个=5;Mdl。B=2
Mdl =共轭与属性:NumPredictors: 3拦截:1 VarNames: {4x1 cell} Mu: [4x1 double] V: [4x4 double] A: 5 B:2 |意味着性病CI95积极的分布 ---------------------------------------------------------------------------------- 拦截| -20 0.3536 [-20.705,-19.295]0.000 t(-20.00、0.32 ^ 2,10)IPI | 4 0.3536 [3.295, 4.705] 1.000 t E(4.00、0.32 ^ 2,10)| 0.1000 - 0.3536[-0.605,0.805]0.621吨(0.10、0.32 ^ 2,10)WR | 2 0.3536 [1.295, 2.705] 1.000 t(2.00、0.32 ^ 2,10)Sigma2 | 0.1250 - 0.0722[0.049, 0.308] 1.000搞笑(5.00,2)
bayeslm根据形状和规模的变化更新先前的分布摘要。
自定义多元t系数先验模型
中的线性回归模型默认扩散先验模型.假设这些先验分布:
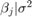 是四维t每个分量为50个自由度的分布,相关矩阵为单位矩阵。分布也集中在
是四维t每个分量为50个自由度的分布,相关矩阵为单位矩阵。分布也集中在![左${\[{\开始{数组}{* {20}{c}}{- 25} & # 38; 4 & # 38; 0 & # 38; 3结束\{数组}}\右]^ \ '}$](//www.tatmou.com/help/examples/econ/win64/CustomMultivariatetPriorModelForCoefficientsExample_eq06094370667326100457.png) 每个分量都被向量中相应的元素所缩放
每个分量都被向量中相应的元素所缩放![左${\[{\开始{数组}{* {20}{c}}{10} & # 38; 1 & # 38; 1 & # 38;结束1 \{数组}}\右]^ \ '}$](//www.tatmou.com/help/examples/econ/win64/CustomMultivariatetPriorModelForCoefficientsExample_eq11954731508684699991.png) .
.
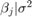
![左${\[{\开始{数组}{* {20}{c}}{- 25} & # 38; 4 & # 38; 0 & # 38; 3结束\{数组}}\右]^ \ '}$](http://www.tatmou.com/help/examples/econ/win64/CustomMultivariatetPriorModelForCoefficientsExample_eq06094370667326100457.png)
![左${\[{\开始{数组}{* {20}{c}}{10} & # 38; 1 & # 38; 1 & # 38;结束1 \{数组}}\右]^ \ '}$](http://www.tatmou.com/help/examples/econ/win64/CustomMultivariatetPriorModelForCoefficientsExample_eq11954731508684699991.png)
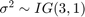 .
.
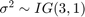
bayeslm将这些假设和数据似然视为对应的后验是难以分析的。
声明一个MATLAB®函数:
接受值为
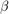 而且
而且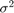 在一个列向量中,并接受超参数的值
在一个列向量中,并接受超参数的值返回联合先验分布的值,
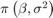 的值而且
的值而且
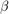
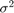
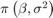
函数logPDF = priorMVTIG(params,ct,st,dof,C,a,b)多元t乘以逆伽马的对数密度% priorMVTIG将参数(1:end-1)传递给多元t密度%函数,每个分量的自由度为正%定相关矩阵C. priorMVTIG返回%,两个评估密度。%params:用于计算密度的参数值% m × 1数值向量。%% ct:多元分布分量中心,以(m-1) × 1为单位%数值向量。元素对应于第一个m-1个元素%的参数。%% st:多元t分布分量,以(m-1) × 1为单位%数值(m-1)乘1数值向量。元素对应于参数的前m-1个元素。%% dof:多元t分布的自由度,a%数值标量或(m-1)乘1数值向量。priorMVTIG扩展%使dof = dof*ones(m-1,1)的标量。自由度元素%对应于参数(1:end-1)中的元素。%% C:多元t分布的相关矩阵,an% (m-1)-by-(m-1)对称,正定矩阵。行和%列对应于params(1:end-1)中的元素。%% a:逆gamma形状参数,一个正数值标量。%% b:逆gamma比例参数,一个正标量。%Beta = params(1:(end-1));Sigma2 = params(end);tVal = (beta - ct)./st;mvtDensity = mvtpdf(tVal,C,dof);igDensity = sigma2 ^ (1) * exp (1 / (sigma2 * b)) /(γ(a) * b ^);logPDF = log(mvtDensity*igDensity);结束
创建一个匿名函数,操作如下priorMVTIG,但只接受参数值,并保持超参数值固定。
Dof = 50;C =眼睛(4);Ct = [-25;4;0;3);St = [10;1;1;1); a = 3; b = 1; prior = @(params)priorMVTIG(params,ct,st,dof,C,a,b);
为线性回归参数创建自定义联合先验模型。指定预测器的数量p.另外,指定for的函数句柄priorMVTIG,并传递超参数值。
P = 3;Mdl = bayeslm(p,“ModelType”,“自定义”,“LogPDF”之前,)
Mdl = customblm with properties: NumPredictors: 3截距:1 VarNames: {4x1 cell} LogPDF: @(params)priorMVTIG(params,ct,st,dof,C,a,b)先验由函数定义:@(params)priorMVTIG(params,ct,st,dof,C,a,b)
Mdl是一个customblm贝叶斯线性回归模型对象表示回归系数和扰动方差的先验分布。在这种情况下,bayeslm不在命令行上显示以前分发的摘要。
执行贝叶斯套索回归
中的线性回归模型默认扩散先验模型.
假设这些先验分布:
为k= 0,…,3, 拉普拉斯分布的均值为0,标度为 ,在那里 为收缩参数。系数是条件独立的。
. 而且 分别是逆伽马分布的形状和比例。
为贝叶斯线性回归创建一个先验模型bayeslm.指定预测器的数量p还有变量名。
P = 3;PriorMdl = bayeslm(p,“ModelType”,“套索”,“VarNames”, (“他们”“E”“福”]);
PriorMdl是一个lassoblm贝叶斯线性回归模型对象表示回归系数和扰动方差的先验分布。默认情况下,bayeslm收缩的属性0.01到截距1对模型中的其他系数。
的新值,通过指定3 × 1向量,更改除截距外的所有系数的默认收缩值λ的属性PriorMdl.
使收缩
10来新闻学会而且或者说是.因为
E有一个比其他变量大几个数量级的尺度,属性的收缩1 e5到它。
λ(2:结束)属性中指定变量对应的系数的收缩量VarNames的属性PriorMdl.
PriorMdl。λ=[10;1 e5;10);
加载Nelson-Plosser数据集。为响应和预测器系列创建变量。
负载Data_NelsonPlosserX = DataTable{:, priormll . varnames (2:end)};y = DataTable{:,“GNPR”};
执行贝叶斯套索回归通过传递先验模型和数据估计,即通过估计的后验分布
而且
.贝叶斯套索回归采用马尔可夫链蒙特卡罗(MCMC)从后验抽样。为了重现性,设置一个随机种子。
rng (1);PosteriorMdl =估计(PriorMdl,X,y);
方法:套带MCMC抽样,抽取10000次观测数:62个预测数:4 |平均标准CI95正分布-------------------------------------------------------------------------拦截| -1.3472 6.8160[-15.169,11.590]0.427经验IPI | 4.4755 0.1646[4.157, 4.799] 1.000经验E | 0.0001 0.0002[-0.000, 0.000] 0.796经验WR | 3.1610 0.3136[2.538, 3.760] 1.000经验Sigma2 | 60.1452 11.1180[42.319, 85.085] 1.000经验
绘制后验分布。
情节(PosteriorMdl)
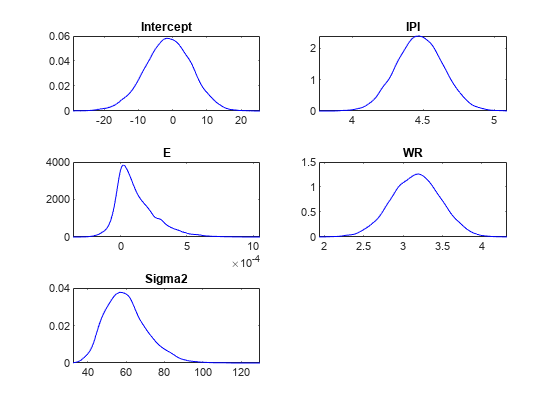
假设缩水率为10,分布E在0附近密度相当大。因此,E可能不是一个重要的预测因素。
输入参数
输出参数
更多关于
参考文献
[1]乔治,e。I。和r。e。麦卡洛克。"通过吉布斯抽样的变量选择"美国统计协会杂志.第88卷,第423号,1993年,第881-889页。
[2]库普,G. D. J.普瓦里尔,J. L.托比亚斯。贝叶斯计量经济学方法.纽约:剑桥大学出版社,2007年。
[3]帕克、T.和G.卡塞拉。“贝叶斯套索。”美国统计协会杂志.Vol. 103 No. 482, 2008, pp. 681-686。
另请参阅
对象
conjugateblm|semiconjugateblm|diffuseblm|customblm|empiricalblm|lassoblm|mixconjugateblm|mixsemiconjugateblm
功能
您也可以从以下列表中选择一个网站:
