经典模型误用测试gydF4y2Ba
这个例子展示了似然比、Wald和Lagrange乘数检验的使用。这些测试在评估和评估模型的限制以及最终选择一个平衡了充分性和简单性这两个经常相互竞争的目标的模型时是有用的。gydF4y2Ba
介绍gydF4y2Ba
计量经济学模型是一种平衡。一方面,它们必须足够详细,以说明相关的经济因素及其对观测数据模式的影响。另一方面,它们必须避免不必要的复杂性,从而导致计算挑战、过度拟合或解释问题。工作模型通常是通过考虑一系列嵌套规范来开发的,在这些规范中,更大的理论模型被检查以简化参数的限制。如果参数是由最大似然估计的,通常使用三个经典检验来评估限制模型的充分性。他们是gydF4y2Ba似然比检验gydF4y2Ba,gydF4y2Ba瓦尔德测试gydF4y2Ba,gydF4y2Ba拉格朗日乘子检验gydF4y2Ba。gydF4y2Ba
模型参数的对数似然gydF4y2Ba ,考虑到数据gydF4y2Ba 是表示gydF4y2Ba (gydF4y2Ba |gydF4y2Ba ).没有对模型的限制,gydF4y2Ba 在最大似然估计(MLE)处优化gydF4y2Ba 。带有形式限制gydF4y2Ba (gydF4y2Ba )gydF4y2Ba ,gydF4y2Ba 在优化gydF4y2Ba 描述数据的对数似然一般降低。经典检验利用从这些优化中获得的信息来评估模型约束的统计显著性。框架非常通用;它包括线性和非线性模型,以及线性和非线性约束。特别地,它扩展了熟悉的框架gydF4y2BatgydF4y2Ba和gydF4y2BaFgydF4y2Ba线性模型的检验。gydF4y2Ba
每次测试都使用对数似然曲面的几何形状,以不同的方式评估模型限制的重要性:gydF4y2Ba
似然比检验考虑对数似然在gydF4y2Ba 和gydF4y2Ba 。如果限制不重要,那么这个差值应该接近于零。gydF4y2Ba
沃尔德测试考虑的是gydF4y2Ba 在gydF4y2Ba 。如果限制不重要,则该值应该接近gydF4y2Ba 在gydF4y2Ba 也就是0。gydF4y2Ba
拉格朗日乘子检验考虑梯度,或gydF4y2Ba分数gydF4y2Ba的,gydF4y2Ba 在gydF4y2Ba 。如果限制不重要,则该向量应该接近于gydF4y2Ba 也就是0。gydF4y2Ba
似然比检验直接评估对数似然的差异。沃尔德和拉格朗日乘数检验间接地做到了这一点,其思想是,评估量的不显著变化可以通过参数的不显著变化来识别。这种识别依赖于对数似然曲面在最大似然邻域的曲率。因此,Wald和Lagrange乘数检验在检验统计量的公式中包含了参数协方差的估计。gydF4y2Ba
Econometrics Toolbox™软件在函数中实现了似然比、Wald和Lagrange乘数测试gydF4y2BalratiotestgydF4y2Ba,gydF4y2BawaldtestgydF4y2Ba,gydF4y2Ba航空航天gydF4y2Ba,分别。gydF4y2Ba
数据和模型gydF4y2Ba
以下是美国人口普查局(U.S. Census Bureau)按教育程度给出的平均年收入数据:gydF4y2Ba
负载gydF4y2BaData_Income2gydF4y2BanumLevels = 8;X = 100 * repmat (1: numLevels numLevels 1);gydF4y2Ba%级别:100,200,…, 800年gydF4y2Bax = x (:);gydF4y2Ba%的教育gydF4y2Bay =数据(:);gydF4y2Ba%的收入gydF4y2Ban =长度(y);gydF4y2Ba%样本大小gydF4y2BalevelNames = DataTable.Properties.VariableNames;箱线图(数据、gydF4y2Ba“标签”gydF4y2BalevelNames电网)gydF4y2Ba在gydF4y2Ba包含(gydF4y2Ba“受教育程度”gydF4y2Ba) ylabel (gydF4y2Ba“平均年收入(1999年美元)”gydF4y2Ba)标题(gydF4y2Ba“{\bf收入和教育}”gydF4y2Ba)gydF4y2Ba
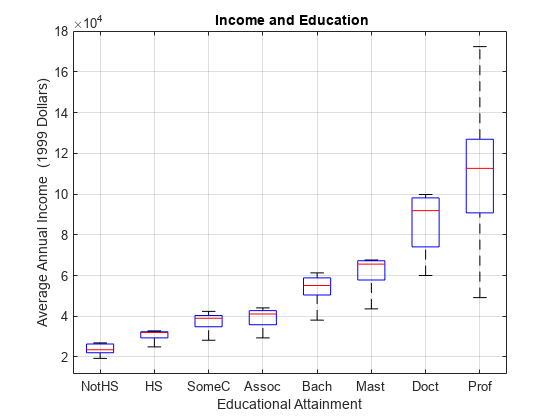
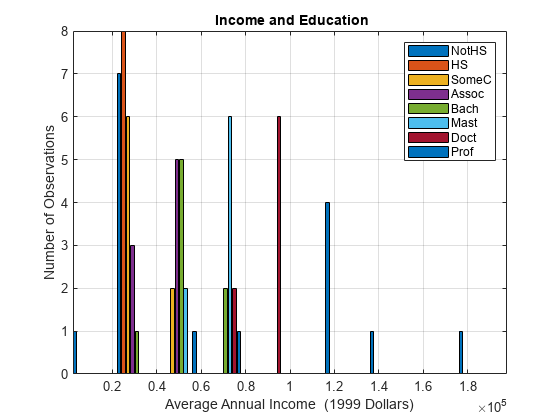
数据中的收入分配取决于教育程度gydF4y2BaxgydF4y2Ba。这个模式在数据的直方图中也很明显,它显示了小样本量:gydF4y2Ba
Figure edges = [0:0.2:2]*1e5;中心= [0.1:0.2:1.9]* 1 e5;BinCounts = 0(长度(边缘)1、numLevels);gydF4y2Ba为gydF4y2Baj = 1:numLevels BinCounts(:,j) = histcounts(Data(:,j),edges);gydF4y2Ba结束gydF4y2Ba;h =酒吧(中心、BinCounts);轴gydF4y2Ba紧gydF4y2Ba网格gydF4y2Ba在gydF4y2Ba传奇(h, levelNames)包含(gydF4y2Ba“平均年收入(1999年美元)”gydF4y2Ba) ylabel (gydF4y2Ba“数量的观察”gydF4y2Ba)标题(gydF4y2Ba“{\bf收入和教育}”gydF4y2Ba)gydF4y2Ba
这类数据的一个常见模型是带有条件密度的伽马分布gydF4y2Ba
在哪里gydF4y2Ba
和gydF4y2Ba
分布是gydF4y2Ba 指数分布,因此承认值的自然限制gydF4y2Ba 。指数分布gydF4y2Ba = 1,是单调递减的,太简单,无法描述数据中的单峰分布。为了说明的目的,我们将维护一个限制模型,它是gydF4y2Ba两个gydF4y2Ba指数分布,通过施加限制得到gydF4y2Ba
这个零模型将与由一般伽马分布所代表的无限制备选方案进行测试。gydF4y2Ba
条件伽马密度及其导数的对数似然函数通过解析得到:gydF4y2Ba
在哪里gydF4y2Ba 二函数是导数吗gydF4y2Ba 。gydF4y2Ba
采用对数似然函数对受限模型和非受限模型进行最大似然估计。导数被用来构造梯度和参数协方差估计的瓦尔德和拉格朗日乘数检验。gydF4y2Ba
最大似然估计gydF4y2Ba
由于MATLAB®和最优化工具箱™软件中的优化器找到最小值,我们通过最小化负对数似然函数来最大化对数似然。使用gydF4y2Ba
如上所述,我们用参数向量对负对数似然函数进行编码gydF4y2Bap =[β;ρ)gydF4y2Ba:gydF4y2Ba
nLLF = @ (p)和(p(2) *(日志(p (1) + x)) + gammaln (p(2))——(p(2) 1) *日志(y) + y / (p (1) + x));gydF4y2Ba
我们使用这个函数gydF4y2BafmincongydF4y2Ba计算的受限参数估计gydF4y2Ba
= 2。上下限gydF4y2Ba
确保对数gydF4y2BanLLFgydF4y2Ba在积极的论点被评估:gydF4y2Ba
选择= optimoptions (@fmincon,gydF4y2Ba“TolFun”gydF4y2Ba1平台以及gydF4y2Ba“显示”gydF4y2Ba,gydF4y2Ba“关闭”gydF4y2Ba);r0 = [1 1];gydF4y2Ba%初始值gydF4y2BaRLB = [-min(x) 2];gydF4y2Ba%下界gydF4y2Ba[Inf 2];gydF4y2Ba%上界gydF4y2Ba[rmle, rnLL] = fmincon (nLLF rp0 ,[],[],[],[], rlb,摩擦,[],选项);rbeta = rmle (1);gydF4y2Ba%限制贝塔估计gydF4y2Barrho = rmle (2);gydF4y2Ba%限制的估计gydF4y2BarLL = -rnLL;gydF4y2Ba%限制loglikelihoodgydF4y2Ba
不受限制的参数估计以类似的方式计算,从受限制的估计给出的初值开始:gydF4y2Ba
Up0 = [rbeta rho];gydF4y2Ba%初始值gydF4y2BaUlb = [-min(x) 0];gydF4y2Ba%下界gydF4y2Bauub = [Inf Inf];gydF4y2Ba%上界gydF4y2Ba[umle, unLL] = fmincon (nLLF up0 ,[],[],[],[], ulb号,[],选项);ubeta = umle (1);gydF4y2Ba%无限制贝塔估计gydF4y2Baurho = umle (2);gydF4y2Ba%无限制的估计gydF4y2Ba妳= -unLL;gydF4y2Ba%无限制loglikelihoodgydF4y2Ba
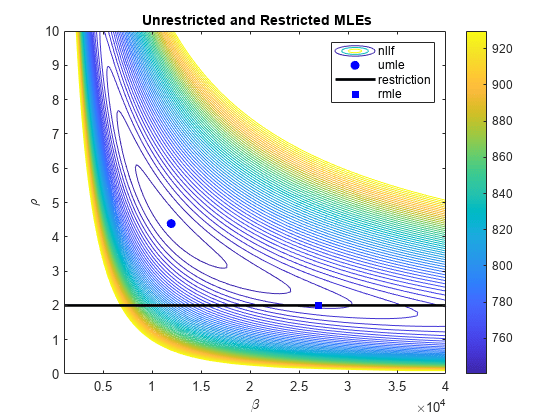
我们将MLEs显示在负对数似然曲面的对数等高线图上:gydF4y2Ba
β= 1 e3:1e2:4e4;罗斯= 0:0.1:10;(贝塔,罗斯)= meshgrid(贝塔,罗斯);NLL = 0(大小(贝塔));gydF4y2Ba为gydF4y2Bai = 1:元素个数(NLL)划分(i) = nLLF([β(i),罗斯(i)));gydF4y2Ba结束gydF4y2BaL = log10 (unLL);0.1 v = logspace (L - L + 0.1,100);轮廓(贝塔,罗斯,附近,v)gydF4y2Ba负对数似然曲面gydF4y2Bacolorbar举行gydF4y2Ba在gydF4y2Ba情节(ubeta urho,gydF4y2Ba“波”gydF4y2Ba,gydF4y2Ba“MarkerFaceColor”gydF4y2Ba,gydF4y2Ba“b”gydF4y2Ba)gydF4y2Ba%无限制的大中型企业gydF4y2Ba线([1 e3 4 e4] 2 [2],gydF4y2Ba“颜色”gydF4y2Ba,gydF4y2Ba“k”gydF4y2Ba,gydF4y2Ba“线宽”gydF4y2Ba,2)gydF4y2Ba%的限制gydF4y2Ba情节(rbeta rrho,gydF4y2Ba“废话”gydF4y2Ba,gydF4y2Ba“MarkerFaceColor”gydF4y2Ba,gydF4y2Ba“b”gydF4y2Ba)gydF4y2Ba%限制企业gydF4y2Ba传奇(gydF4y2Ba“nllf”gydF4y2Ba,gydF4y2Ba“umle”gydF4y2Ba,gydF4y2Ba“限制”gydF4y2Ba,gydF4y2Ba“rmle”gydF4y2Ba)包含(gydF4y2Ba“β\”gydF4y2Ba) ylabel (gydF4y2Ba‘\ρgydF4y2Ba)标题(gydF4y2Ba“{\bf无限制和受限MLEs}”gydF4y2Ba)gydF4y2Ba
协方差估计gydF4y2Ba
对数似然曲面的曲率与参数估计的方差/协方差之间的直观关系被形式化gydF4y2Ba信息矩阵平等gydF4y2Ba,用Fisher信息矩阵识别Hessian的负期望值。Hessian的二阶导数表示对数似然凹腔。Fisher信息矩阵表示参数方差;它的逆是渐近协方差矩阵。gydF4y2Ba
Wald和Lagrange乘数检验所需的协方差估计量可以用多种方法计算。一种方法是使用梯度的外积(OPG),它只需要对数似然的一阶导数。虽然OPG估价器因其相对简单而受欢迎,但它可能不可靠,特别是在小样本情况下。另一个通常更可取的估计量是负预期Hessian的逆。通过信息矩阵等式,该估计量为渐近协方差,适用于大样本。如果分析期望很难计算,预期的Hessian可以被在参数估计中评估的Hessian所取代,即所谓的“观测”Fisher信息。gydF4y2Ba
我们用的导数来计算这三个估计量gydF4y2Ba 早发现。Hessian中的条件期望使用gydF4y2Ba
我们评估了在非限制参数估计处的估计量,用于沃尔德检验,然后在限制参数估计处的估计量,用于拉格朗日乘子检验。gydF4y2Ba
不同的量表gydF4y2Ba 和gydF4y2Ba 参数反映在方差的相对大小。小样本量反映在估计值之间的差异。我们增加了显示器的精度来显示这些差异:gydF4y2Ba
格式gydF4y2Ba长gydF4y2Ba
在不受限制的参数估计下求值,估计量为:gydF4y2Ba
%功能估计量:gydF4y2BaUG = [-urho. / ubeta + x + y。* (ubeta + x) ^(2),日志(ubeta + x)ψ(urho) +日志(y)];Uscore = (UG)的总和;UEstCov1 =发票(UG的* UG)gydF4y2Ba% #好吧gydF4y2Ba
UEstCov1 =gydF4y2Ba2×2gydF4y2Ba10gydF4y2Ba6gydF4y2Ba× 6.1637 -0.0023 -0.0023 0.0000gydF4y2Ba
% Hessian估计量(观测信息):gydF4y2BaUDPsi =(ψ(urho + 0.0001)ψ(urho - 0.0001) / (0.0002);gydF4y2Ba%双导gydF4y2Ba嗯=[总和(urho. / (ubeta + x) ^ 2) 2 *总和(y / (ubeta + x) ^ 3),笔(1. / (ubeta + x));gydF4y2Ba...gydF4y2Ba总和(1. / (ubeta + x)) - n * UDPsi];UEstCov2 =发票(哦)gydF4y2Ba% #好吧gydF4y2Ba
UEstCov2 =gydF4y2Ba2×2gydF4y2Ba10gydF4y2Ba6gydF4y2Ba× 5.9143 -0.0019 -0.0019 0.0000gydF4y2Ba
%期望Hessian估计量(期望信息):gydF4y2BaUEH =[总和(urho. / ((ubeta + x) ^ 2)),笔(1. / (ubeta + x));gydF4y2Ba...gydF4y2Ba总和(1. / (ubeta + x)) - n * UDPsi];UEstCov3 =发票(UEH)gydF4y2Ba% #好吧gydF4y2Ba
UEstCov3 =gydF4y2Ba2×2gydF4y2Ba10gydF4y2Ba6gydF4y2Ba× 4.9935 -0.0016 -0.0016 0.0000gydF4y2Ba
在限制参数估计下求值,估计量为:gydF4y2Ba
%功能估计量:gydF4y2BaRG = [-rrho. / rbeta + x + y。* (rbeta + x) ^(2),日志(rbeta + x)ψ(rrho) +日志(y)];Rscore = (RG)的总和;REstCov1 =发票(RG * RG)gydF4y2Ba% #好吧gydF4y2Ba
REstCov1 =gydF4y2Ba2×2gydF4y2Ba10gydF4y2Ba7gydF4y2Ba× 6.6143 -0.0005 -0.0005 0.0000gydF4y2Ba
% Hessian估计量(观测信息):gydF4y2BaRDPsi =(ψ(rrho + 0.0001)ψ(rrho - 0.0001) / (0.0002);gydF4y2Ba%双导gydF4y2BaRH =[总和(rrho. / (rbeta + x) ^ 2) 2 *总和(y / (rbeta + x) ^ 3),笔(1. / (rbeta + x));gydF4y2Ba...gydF4y2Ba总和(1. / (rbeta + x)) - n * RDPsi];REstCov2 =发票(RH)gydF4y2Ba% #好吧gydF4y2Ba
REstCov2 =gydF4y2Ba2×2gydF4y2Ba10gydF4y2Ba7gydF4y2Ba× 2.7084 -0.0002 -0.0002 0.0000gydF4y2Ba
%期望Hessian估计量(期望信息):gydF4y2Ba盐土=[总和(rrho. / ((rbeta + x) ^ 2)),笔(1. / (rbeta + x));gydF4y2Ba...gydF4y2Ba总和(1. / (rbeta + x)) - n * RDPsi];REstCov3 =发票(盐土)gydF4y2Ba% #好吧gydF4y2Ba
REstCov3 =gydF4y2Ba2×2gydF4y2Ba10gydF4y2Ba7gydF4y2Ba× 2.6137 -0.0001 -0.0001 0.0000gydF4y2Ba
返回简短的数字显示:gydF4y2Ba
格式gydF4y2Ba短gydF4y2Ba
似然比检验gydF4y2Ba
似然比检验,评估对数似然差在非限制和限制参数估计的统计显著性,通常被认为是三种经典检验中最可靠的。它的主要缺点是需要对两个模型进行估计。如果不受限制的模型或约束是非线性的,这可能是一个问题,对必要的优化提出了重大要求。gydF4y2Ba
一旦通过最大似然估计获得所需的对数似然,则使用gydF4y2BalratiotestgydF4y2Ba执行似然比检验:gydF4y2Ba
景深= 1;gydF4y2Ba%限制数量gydF4y2Ba(LRh单体、LRstat简历]= lratiotest(妳,rLL景深)gydF4y2Ba% #好吧gydF4y2Ba
LRh =gydF4y2Ba逻辑gydF4y2Ba1gydF4y2Ba
= 7.9882 e-05部队gydF4y2Ba
LRstat = 15.5611gydF4y2Ba
简历= 3.8415gydF4y2Ba
该测试拒绝受限制模型(gydF4y2BaLRh = 1gydF4y2Ba),gydF4y2BapgydF4y2Ba值(gydF4y2Ba含碘= 7.9882 e - 005gydF4y2Ba)远低于默认显著性级别(gydF4y2Baα= 0.05gydF4y2Ba)和测试统计量(gydF4y2BaLRstat = 15.5611gydF4y2Ba)远高于临界值(gydF4y2Ba简历= 3.8415gydF4y2Ba).gydF4y2Ba
与Wald和Lagrange乘数检验一样,似然比检验也是渐近的;检验统计量是通过让样本容量趋于无穷得到的极限分布来评估的。相同的卡方分布,有自由度gydF4y2Ba景深gydF4y2Ba,用于评估三个检验中每个检验的单个检验统计量,且临界值相同gydF4y2Ba简历gydF4y2Ba。从小样本中进行推断的结果应该是显而易见的,这也是为什么这三种测试经常一起使用的原因之一,作为相互对照。gydF4y2Ba
瓦尔德测试gydF4y2Ba
Wald测试适用于约束对参数估计施加重大要求的情况,如多个非线性约束的情况。Wald检验的优点是它只需要不受限制的参数估计。它的主要缺点是,与似然比检验不同,它还需要对参数协方差进行合理准确的估计。gydF4y2Ba
要执行Wald测试,必须将限制表述为来自的功能gydF4y2BapgydF4y2Ba-维参数空间gydF4y2Ba问gydF4y2Ba维限制空间:gydF4y2Ba
与雅可比矩阵gydF4y2Ba
对于所考虑的伽玛分布,单限制gydF4y2Ba
用雅可比矩阵[0,1]将二维参数空间映射到一维约束空间。gydF4y2Ba
使用gydF4y2BawaldtestgydF4y2Ba使用前面计算的每个不受限制的协方差估计运行Wald测试。限制的数量gydF4y2Ba景深gydF4y2Ba是输入向量的长度吗gydF4y2BargydF4y2Ba,因此它不必像for那样显式输入gydF4y2BalratiotestgydF4y2Ba或gydF4y2Ba航空航天gydF4y2Ba:gydF4y2Ba
r = urho-2;gydF4y2Ba%限制向量gydF4y2BaR = [0 1];gydF4y2Ba%雅可比矩阵gydF4y2Ba限制= {r, r, r};雅克比= {R, R, R};UEstCov = {UEstCov1, UEstCov2 UEstCov3};(Wh Wp、Wstat简历]= waldtest(限制、雅克比UEstCov)gydF4y2Ba% #好吧gydF4y2Ba
Wh =gydF4y2Ba1 x3逻辑阵列gydF4y2Ba1 1 1gydF4y2Ba
Wp =gydF4y2Ba1×3gydF4y2Ba0.0144 0.0031 0.0014gydF4y2Ba
Wstat =gydF4y2Ba1×3gydF4y2Ba5.9878 8.7671 10.2066gydF4y2Ba
简历=gydF4y2Ba1×3gydF4y2Ba3.8415 3.8415 3.8415gydF4y2Ba
该测试拒绝使用每个协方差估计的受限模型。gydF4y2Ba
计量经济学工具箱和统计工具箱™软件的假设检验在默认的5%显著性水平上运行。显著性级别可以通过一个可选的输入来改变:gydF4y2Ba
α= 0.01;gydF4y2Ba% 1%显著水平gydF4y2Ba[Wh2, Wp2 Wstat2 cV2] = waldtest(限制、雅克比UEstCovα)gydF4y2Ba% #好吧gydF4y2Ba
Wh2 =gydF4y2Ba1 x3逻辑阵列gydF4y2Ba0 1 1gydF4y2Ba
Wp2 =gydF4y2Ba1×3gydF4y2Ba0.0144 0.0031 0.0014gydF4y2Ba
Wstat2 =gydF4y2Ba1×3gydF4y2Ba5.9878 8.7671 10.2066gydF4y2Ba
cV2 =gydF4y2Ba1×3gydF4y2Ba6.6349 6.6349 6.6349gydF4y2Ba
在新的显著性水平上,OPG估计器不能拒绝受限模型。gydF4y2Ba
拉格朗日乘数检验gydF4y2Ba
拉格朗日乘数检验适用于无限制模型对参数估计有重大要求的情况,如有限制模型是线性的,而无限制模型不是。拉格朗日乘子检验的优点是它只需要限制性参数估计。它的主要缺点是,像Wald检验一样,它也需要对参数协方差进行合理准确的估计。gydF4y2Ba
使用gydF4y2Ba航空航天gydF4y2Ba用前面计算的每个受限协方差估计运行拉格朗日乘数检验:gydF4y2Ba
成绩= {Rscore, Rscore Rscore};REstCov = {REstCov1, REstCov2 REstCov3};[LMh, LMp LMstat cV) =以前(分数,REstCov,景深)gydF4y2Ba% #好吧gydF4y2Ba
LMh =gydF4y2Ba1 x3逻辑阵列gydF4y2Ba1 1 1gydF4y2Ba
LMp =gydF4y2Ba1×3gydF4y2Ba0.0000 0.0024 0.0027gydF4y2Ba
LMstat =gydF4y2Ba1×3gydF4y2Ba33.4617 9.2442 8.9916gydF4y2Ba
简历=gydF4y2Ba1×3gydF4y2Ba3.8415 3.8415 3.8415gydF4y2Ba
该测试再次拒绝在默认显著性水平上的每个协方差估计的受限模型。由于首次检验统计量的异常大,OPG估计器的可靠性受到了质疑。gydF4y2Ba
总结gydF4y2Ba
这三种经典的模型误用检验为计量经济学家提供了一个天然的工具箱。在最大似然估计的背景下,他们都试图在逐步简化的数据描述层次结构中,在无限制模型和受限模型之间做出相同的区分。然而,每个测试都有不同的需求,因此可能在不同的建模情况下有用,这取决于计算需求。当一起使用时,推论在不同的测试中可能会有所不同,特别是在小样本的情况下。用户应将测试视为更广泛的统计和经济分析的一个组成部分。gydF4y2Ba
参考文献gydF4y2Ba
[1]gydF4y2BaR.戴维森和J. G.麦金农。gydF4y2Ba计量经济学理论与方法gydF4y2Ba。英国牛津:牛津大学出版社,2004。gydF4y2Ba
[2]gydF4y2Ba戈弗雷·l·G。gydF4y2Ba计量经济学中的误用检验gydF4y2Ba。英国剑桥:剑桥大学出版社,1997。gydF4y2Ba
[3]gydF4y2Ba格林,威廉。H。gydF4y2Ba计量经济学分析gydF4y2Ba。第六版。上鞍河,新泽西:普伦蒂斯霍尔,2008。gydF4y2Ba
[4]gydF4y2Ba汉密尔顿,詹姆斯D。gydF4y2Ba时间序列分析gydF4y2Ba。普林斯顿:普林斯顿大学出版社,1994。gydF4y2Ba
选择网站gydF4y2Ba
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:gydF4y2Ba。gydF4y2Ba
选择gydF4y2Ba网站gydF4y2Ba你也可以从以下列表中选择一个网站:gydF4y2Ba
美洲gydF4y2Ba
- 美国拉丁gydF4y2Ba(西班牙语)gydF4y2Ba
- 加拿大gydF4y2Ba(英语)gydF4y2Ba
- 美国gydF4y2Ba(英语)gydF4y2Ba
欧洲gydF4y2Ba
- 比利时gydF4y2Ba(英语)gydF4y2Ba
- 丹麦gydF4y2Ba(英语)gydF4y2Ba
- 德国gydF4y2Ba(德语)gydF4y2Ba
- 西班牙gydF4y2Ba(西班牙语)gydF4y2Ba
- 芬兰gydF4y2Ba(英语)gydF4y2Ba
- 法国gydF4y2Ba(法语)gydF4y2Ba
- 爱尔兰gydF4y2Ba(英语)gydF4y2Ba
- 意大利gydF4y2Ba(意大利语)gydF4y2Ba
- 卢森堡gydF4y2Ba(英语)gydF4y2Ba
- 荷兰gydF4y2Ba(英语)gydF4y2Ba
- 挪威gydF4y2Ba(英语)gydF4y2Ba
- 奥地利gydF4y2Ba(德语)gydF4y2Ba
- 葡萄牙gydF4y2Ba(英语)gydF4y2Ba
- 瑞典gydF4y2Ba(英语)gydF4y2Ba
- 瑞士gydF4y2Ba
- 联合王国gydF4y2Ba(英语)gydF4y2Ba
亚太地区gydF4y2Ba
- 澳大利亚gydF4y2Ba(英语)gydF4y2Ba
- 印度gydF4y2Ba(英语)gydF4y2Ba
- 新西兰gydF4y2Ba(英语)gydF4y2Ba
- 中国gydF4y2Ba
- 日本gydF4y2Ba(日本語)gydF4y2Ba
- 한국gydF4y2Ba(한국어)gydF4y2Ba
