First-to-Default互换
这个例子展示了如何在同质损失假设下为首次违约(FTD)互换定价。
首先违约互换是一种工具,当(以及如果)一篮子信贷工具中的第一种出现违约时,它将支付预先确定的金额。篮子里的信贷工具通常是债券。如果我们假设信用事件后的损失金额对篮子中的所有信用都是相同的,我们就在均匀的损失假设。这个假设使模型更简单,因为篮子中的任何违约都会触发相同的支付金额。这个例子是这些工具的定价方法的实现,如O’kane[2]所述。该方法有两个步骤:a)从数字上计算篮子的生存概率;b)使用生存曲线和标准单名信用违约掉期(CDS)功能来发现FTD价差并为现有FTD掉期定价。
将概率曲线与市场数据拟合
给定篮子中每个发行人的CDS市场报价,使用cdsbootstrap为每个发行人校正个别违约概率曲线。
%利率曲线ZeroDates = datenum ({“17-Jan-10”,“17-Jul-10”,“17-Jul-11”,“17-Jul-12”,...“17-Jul-13”,“17-Jul-14”});ZeroRates = [1.35 1.43 1.9 2.47 2.936 3.311]'/100;ZeroData = [zeroates ZeroRates];% CDS利差市场价差中的每一行对应一个不同的发行人;每一个%列到一个不同的到期日(对应于MarketDates)MarketDates = datenum ({“20-Sep-10”,“20-Sep-11”,“20-Sep-12”,“20-Sep-14”,...“20-Sep-16”});市场价差= [160 195 230 285 330;130 165 205 260 305;150 180 210 260 300;165 200 225 275 295];%发行人数量等于市场价差的行数nIssuers =大小(MarketSpreads, 1);%结算日期解决= datenum (“2009年- 7月17日”);
在实践中,时间轴被离散化,FTD生存曲线仅在网格点进行评估。我们每三个月用一个穴位。要求cdsbootstrap使用可选参数'ProbDates'返回我们想要的特定网格点上的默认概率值。我们将原始标准CDS市场日期添加到网格中,否则这些日期的违约概率信息将使用网格中最接近的两个日期进行插值,而市场日期的价格将与原始市场数据不一致。
ProbDates =联盟(MarketDates daysadd(结算360 * (0.25:0.25:8),1));nProbDates =长度(ProbDates);DefProb = 0 (nIssuers nProbDates);为ii = 1: n发行人市场数据= [MarketDates MarketSpreads(ii,:)'];ProbData = cdsbootstrap (ZeroData MarketData,结算,...“ProbDates”, ProbDates);DefProb (ii) = ProbData (:, 2) ';结束
这些是篮子中每个信用的校准违约概率曲线。
figure plot(ProbDates', defprobb) datetick title(“个人违约概率曲线”) ylabel (“累积概率”)包含(“日期”)

确定潜在可变阈值
潜在变量在不同的信用风险环境中使用,有不同的解释。在某些情况下,潜在变量是a的代理资产价值的变化,该变量的域被装箱,每个装箱对应一个信用评级。垃圾箱的限制或阈值是由信贷迁移矩阵确定的。在我们的语境中,潜变量与a相关默认的时间,阈值决定离散时间网格中可能出现默认值的容器。
在形式上,如果特定发行人的违约时间被表示为 ,我们知道它的默认概率函数
,我们知道它的默认概率函数 ,一个潜在变量
,一个潜在变量 和相应的阈值
和相应的阈值 满足
满足

或

这些关系使潜变量方法便于模拟和解析推导。这两个和都是时间的函数。
变量分布的选择确定阈值.在标准潜在变量模型中,变量服从标准正态分布,从哪个

在哪里 为累积标准正态分布。
为累积标准正态分布。
用前面的公式来确定缺省的时间阈值,或者只是默认阈值,对应于先前获得的篮子中信用的违约概率。
DefThresh = norminv (DefProb);
推导篮的生存曲线
根据O'Kane[2],我们使用一个单因素潜在变量模型来推导篮子的生存概率函数的表达式。
给定的参数 为每个发行人
为每个发行人 ,并给出独立的标准正态变量
,并给出独立的标准正态变量 和
和 ,单因素潜变量模型假设潜变量
,单因素潜变量模型假设潜变量 与发行人关联满足
与发行人关联满足

这就形成了发行人之间的相关性和 的
的 .所有潜在的变量共享公因数作为不确定性的来源,但每个潜在变量也有一个特殊的不确定性来源.系数越大时,潜在变量越像公共因素.
.所有潜在的变量共享公因数作为不确定性的来源,但每个潜在变量也有一个特殊的不确定性来源.系数越大时,潜在变量越像公共因素.
利用潜变量模型,推导出篮子存活概率的解析公式。
发行者的概率幸存的过去时间 ,换句话说,就是它的默认时间
,换句话说,就是它的默认时间 大于是
大于是

在哪里 发行者的默认阈值是否高于此值,-th日期在离散网格中。
发行者的默认阈值是否高于此值,-th日期在离散网格中。
条件返回单因子的值,即所有发行人都能度过难关的概率是

产品是合理的,因为所有的是独立的。因此,有条件的,是独立的。
时间上无违约的无条件概率是对所有值的积分吗之前的条件概率

与 标准法向密度。
标准法向密度。
通过计算每个点的一维积分在网格中,我们得到了整个篮子的生存曲线的离散化,这是FTD生存曲线。
潜在变量模型也可以用来模拟违约时间,这是许多信贷工具定价方法的后引擎。例如,Loeffler和Posch[1]通过模拟来估计一个篮子的存活概率。在每个模拟场景中,确定每个发行者的违约时间。通过一些簿记,可以从模拟中估计网格的每个桶上有第一个默认值的概率。在O’kane[2]中也讨论了模拟方法。仿真非常灵活,适用于许多信用工具。然而,如果可行的话,分析方法是首选,因为它们比模拟方法更快、更准确。
在我们的示例中,为了计算FTD存活概率,我们将所有beta值设置为目标相关性的平方根。然后我们循环时间网格中的所有日期来计算给出篮子存活概率的一维积分。
对于实现,条件生存概率是一个标量的函数Z将
condProb = @ (Z)刺激(normcdf ((-DefThresh (:, jj) +β* Z)。/√(1测试版。^ 2)));
然而,我们使用的积分函数要求被积函数的句柄接受向量。尽管围绕条件概率的标量版本进行循环可以工作,但使用下面的方法对条件概率进行矢量化要高效得多bsxfun.
β= sqrt (0.25) * 1 (nIssuers 1);FTDSurvProb = 0(大小(ProbDates));为jj = 1: nProbDates向量化条件概率是Z的函数vecCondProb = @ (Z)刺激(normcdf (bsxfun (@rdivide,...-repmat (DefThresh (:, jj), 1,长度(Z)) + bsxfun (@times,β,Z),...√1测试版。^ 2))));%截断正态分布域到[-5,5]区间FTDSurvProb (jj) =积分(@ (Z) vecCondProb (Z)。* normpdf (Z), 5、5);结束FTDDefProb = 1-FTDSurvProb;
比较FTD概率与个别发行人的违约概率。
figure plot(ProbDates', defprobb) datetick保持在情节(ProbDates FTDDefProb,“线宽”3) datetick保存从标题(“FTD和个人违约概率曲线”) ylabel (“累积概率”)包含(“日期”)

找到FTD价差和现有FTD互换的价格
假设篮子中的所有工具具有相同的回收率,或均质损失假设(见参考文献中的O'Kane),我们使用cdsspread函数,但传递的FTD概率数据刚刚计算。
成熟= MarketDates;ProbDataFTD = [ProbDates, ftddefprobb];FTDSpread = cdsspread (ZeroData ProbDataFTD,解决、成熟度);
将FTD价差与个人价差进行比较。
figure plot(MarketDates,MarketSpreads')日期标记保持在情节(MarketDates FTDSpread,“线宽”, 3)从标题(“FTD和个人CDS利差”) ylabel (“FTD传播(bp)”)包含(“到期日”)

现有的FTD交换可以定价cdsprice,使用相同的FTD概率。
Maturity0 = MarketDates (1);假定到期日为最近的市场日期Spread0 = 540;%现有FTD合同的价差%假定恢复和概念的默认值FTDPrice = cdsprice (ZeroData ProbDataFTD,解决、Maturity0 Spread0);流('现有FTD合同价格:%g\n'FTDPrice)
现有FTD合同价格:17644.7
分析相关敏感性
为了说明FTD价差对模型参数的敏感性,我们计算了一系列相关值的市场价差。
Corr = [0 0.01 0.10 0.25 0.5 0.75 0.90 0.99 1];FTDSpreadByCorr = 0(长度(成熟),(corr));FTDSpreadByCorr (: 1) = (MarketSpreads)的总和;FTDSpreadByCorr(:,结束)= max (MarketSpreads)”;为ii = 2:length(corr)-1 beta = sqrt(corr(ii))*ones(n发行人,1);FTDSurvProb = 0(长度(ProbDates));为jj = 1: nProbDates向量化条件概率是Z的函数condProb = @ (Z)刺激(normcdf (bsxfun (@rdivide,...-repmat (DefThresh (:, jj), 1,长度(Z)) + bsxfun (@times,β,Z),...√1测试版。^ 2))));%截断正态分布域到[-5,5]区间FTDSurvProb (jj) =积分(@ (Z) condProb (Z)。* normpdf (Z), 5、5);结束FTDDefProb = 1-FTDSurvProb;ProbDataFTD = [ProbDates, ftddefprobb];FTDSpreadByCorr(:,(二)= cdsspread (ZeroData ProbDataFTD,解决、成熟度);结束
FTD价差位于个人价差总和和最大价差之间的区间。当相关性增加到1时,FTD息差向篮子中单个息差的最大值(所有信用违约)靠拢。当相关性降至零时,FTD价差接近单个价差(独立信用)的总和。
图图例= cell(1,length(corr));情节(MarketDates FTDSpreadByCorr (: 1),凯西:”)传说{1}=“利差的总和”;datetick举行在为ii = 2:length(corr)-1 plot(MarketDates,FTDSpreadByCorr(:,ii)),“线宽”,3*corr(ii))图例{ii} = [“相关系数”num2str (ii) * 100 (corr)“%”];结束情节(MarketDates FTDSpreadByCorr(:,结束),“k -”。)传说{结束}=利差的马克斯;持有从标题(“不同相关性的FTD价差”) ylabel (“FTD传播(bp)”)包含(“到期日”)传说(传说,“位置”,“西北”)

对于期限较短且相关性较小的货币篮子,该货币篮子实际上是独立的(FTD息差非常接近单个利差的总和)。随着期限的延长,相关效应变得更加显著。
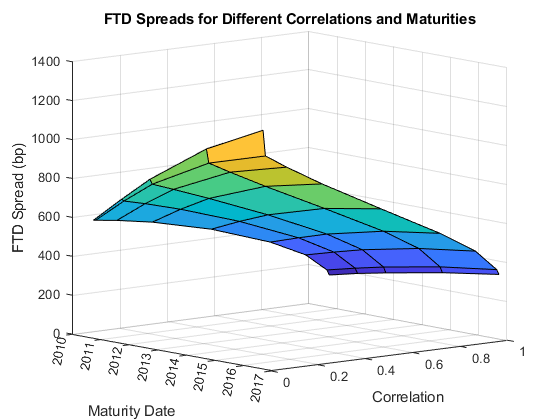
这是一个关于FTD扩展对相关性的依赖性的另一种可视化方法。
图冲浪(corr MarketDates FTDSpreadByCorr) datetick (“y”) ax = gca;斧子。YDir =“反向”;视图(-40年,10)标题(“不同相关性和期限的FTD价差”)包含(“相关”) ylabel (“到期日”) zlabel (“FTD传播(bp)”)
参考文献
[1]吕弗勒,甘特和彼得·波施,使用Excel和VBA进行信用风险建模, Wiley Finance, 2007。
多米尼克[2]•欧凯恩称,单名称和多名称信用衍生品模型, Wiley Finance, 2008。
另请参阅
cdsbootstrap|cdsprice|cdsrpv01|cdsspread
相关的话题
外部网站
你也可以从以下列表中选择一个网站:
