模糊推理系统调优
由于复杂模糊推理系统的参数和规则较多,设计一个具有大量输入和隶属度函数的复杂模糊推理系统是一个具有挑战性的问题。要设计这样的FIS,您可以使用数据驱动的方法来学习规则和调优FIS参数。要调优模糊系统,请使用突使用TunefisOptions.目的。
使用模糊逻辑工具箱™软件,您可以调整1型和Type-2 Fiss以及FIS树。对于例子,见使用Type-2 FIS预测混沌时间序列和调整FIS树的油耗预测.
在培训期间,优化算法生成候选FIS参数集。使用每个参数集更新模糊系统,然后使用输入培训数据进行评估。
如果您有输入/输出培训数据,则基于模糊系统输出与来自训练数据的预期输出值之间的差异计算每个解决方案的成本。有关使用此方法的示例,请参阅调整Mamdani模糊推理系统.
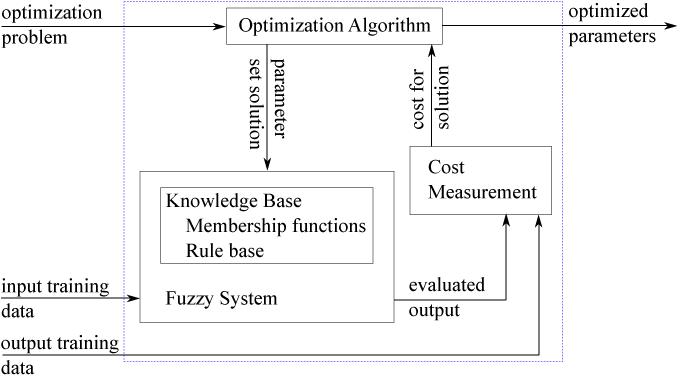
如果您没有输入/输出培训数据,则可以指定自定义模型和成本函数,用于评估候选FIS参数集。成本测量功能将输入发送到模糊系统并接收评估的输出。成本基于评估输出与模型预期的输出之间的差异。有关更多信息和使用此方法的示例,请参阅使用自定义代价函数调整模糊机器人避障系统.
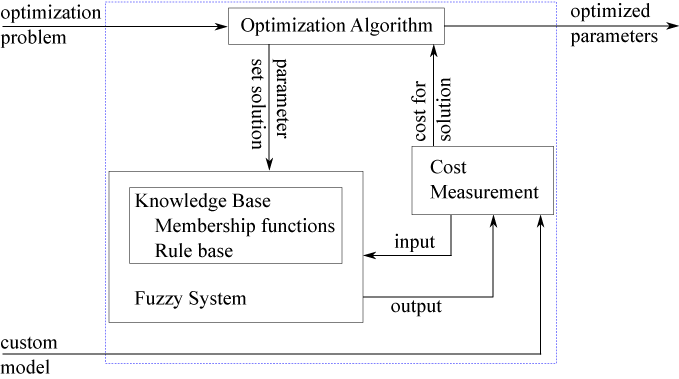
有关调整模糊系统的更多信息,请参阅以下示例。
调整方法
控件支持的调优方法如下表所示金宝app突函数。这些调整方法找到最优的FIS参数
| 方法 | 描述 | 更多的信息 |
|---|---|---|
| 遗传算法 | 基于人口的全局优化方法,通过人口成员之间的突变和交叉随机搜索 | 什么是遗传算法?(全局优化工具箱) |
| 粒子群优化 | 基于种群的全局优化方法,种群成员在搜索区域内步进 | 什么是粒子群优化?(全局优化工具箱) |
| 模式搜索 | 直接搜索本地优化方法,可以在当前点附近搜索一组点以查找新的最佳状态 | 什么是直接搜索?(全局优化工具箱) |
| 模拟退火 | 一种局部优化方法,模拟加热和冷却过程,在当前点附近找到一个新的最优点 | 模拟退火是什么?(全局优化工具箱) |
| 自适应神经模糊推理 | 调整隶属函数参数的背传播算法。或者,您可以使用ANFIS.函数。 |
神经适应学习与ANFIS |
前四种调优方法需要全局优化工具箱软件
全局优化方法,如遗传算法和粒子群优化,在大的参数调整范围内表现更好。这些算法在FIS优化的规则学习和参数调整阶段都很有用。
另一方面,局部搜索方法,如模式搜索和模拟退火,在较小的参数范围内表现更好。如果FIS是由训练数据使用Genfis.或者使用训练数据将规则库添加到FIS中,那么这些算法与全局优化方法相比可以产生更快的收敛速度。
防止调谐系统过拟合
数据过拟合是FIS参数优化中常见的问题。当发生过拟合时,调整后的FIS对训练数据集产生最优结果,但对测试数据集表现不佳。为了克服数据过拟合问题,可以使用单独的验证数据集对模型进行无偏评估,从而提前停止调优过程。
在调优时使用突功能,您可以使用k折交叉验证来防止过度装备。要防止更多信息和示例,请参阅用K折交叉验证优化FIS参数.
改善调整结果
要提高优化后的模糊系统的性能,请考虑以下指导原则。
在调整过程中使用多个阶段。例如,首先使用学习的规则库进行模糊系统的规则,然后调整输入/输出MF参数。
增加规则学习和参数调整阶段中的迭代次数。这样做会增加优化过程的持续时间,并且还可以增加由于培训数据的过度系统参数而增加了验证错误。为避免过度装备,请使用K-Fold交叉验证培训您的系统。
更改使用的群集技术
Genfis..根据群集技术,生成的规则可以在其对训练数据的表示中不同。因此,使用不同的聚类技术可能会影响性能突.改变FIS属性。尝试更改属性,如FIS的类型、输入数量、输入/输出MF的数量、MF类型和规则的数量。Sugeno系统具有更少的输出MF参数(假设MF恒定)和更快的去模糊。因此,对于具有大量输入的模糊系统,Sugeno FIS通常比Mamdani FIS收敛更快。少量的mf和规则减少了要调优的参数数量,从而产生了更快的调优过程。此外,大量的规则可能会导致训练数据过拟合。
修改MFS和规则的可调参数设置。例如,您可以调整三角形MF的支持,而无需更改其峰值位置。金宝app这样做减少了可调参数的数量,可以为特定应用程序产生更快的调整过程。对于规则,您可以通过设置来排除零MF索引
AllowEmpty可调设置为false,这将减少学习阶段的规则总数。
要改进模糊树的调优结果,请考虑以下指导原则。
在FIS树中,可以对每个FIS的参数分别进行调优。然后,您可以将所有的模糊系统协调在一起,以一般化参数值。
更改FIS树属性,例如模糊系统的数量和模糊系统之间的连接。
使用不同的排名和输入的分组到FIS树。有关创建FIS树的更多信息,请参阅模糊树.
另请参阅
相关话题
您还可以从以下列表中选择一个网站:
