用于汽油里程预测的调谐FIS树
这个例子展示了如何调整FIS树的参数,这是一个连接模糊推理系统的集合。这个例子使用粒子群和模式搜索优化,这需要全局优化工具箱™软件。
以英里/加仑(MPG)为单位的汽车油耗预测是一个典型的非线性回归问题。它使用多个汽车外形属性来预测燃油消耗量。培训数据可在加州大学欧文分校获得。机器学习库并包含了从不同品牌和型号的汽车中收集的数据。
此示例使用以下六个输入数据属性通过FIS树预测输出数据属性MPG:
气缸数
位移
马力
重量
加快
模型一年
准备数据
加载数据。从存储库获取的数据集的每一行表示不同的汽车配置文件。
数据= loadGasData;
数据包含7列,其中前6列包含以下输入属性。
气缸数
位移
马力
重量
加快
模型一年
第七列包含输出属性MPG。
创建单独的输入和输出数据集,X和Y分别地
X=数据(:,1:6);Y=数据(:,7);
将输入和输出数据集划分为训练数据(奇数索引样本)和验证数据(偶数索引样本)。
trnX = X(1:2:最终,);%训练输入数据集trnY = Y(1:2:最终,);%训练输出数据集vldX = X(2:2:最终,);%验证输入数据集vldY = Y(2:2:最终,);%验证输出数据集
提取每个数据属性的范围,您将在FIS构造期间使用它来定义输入/输出范围。
数据范围=[最小(数据)'最大(数据)';
构建一个FIS树
对于本例,使用以下步骤构建FIS树:
根据输入属性与输出属性的相关性对其进行排序。
使用排名输入属性创建多个FIS对象。
从FIS对象构建一个FIS树。
根据相关系数对输入进行排序
计算训练数据的相关系数。在相关矩阵的最后一行中,前六个元素显示六个put数据属性和输出属性之间的相关系数。
c1 = corrcoef(数据);c1(最终,:)
ans=1×7-0.7776 -0.8051 -0.7784 -0.8322 0.4233 0.5805 1.0000
前四个输入属性有负值,最后两个输入属性有正值。
将具有负相关性的输入属性按相关系数的绝对值降序排列。
重量
位移
马力
气缸数
按相关系数的绝对值按降序排列具有正相关的输入属性。
模型一年
加快
这些排名表明,体重和车型年份分别与MPG负相关和正相关最高。
创建模糊推理系统
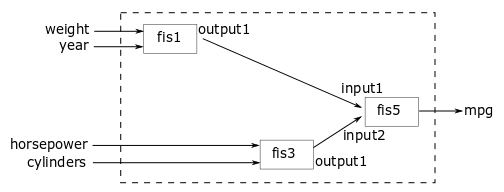
对于本例,使用以下结构实现FIS树。
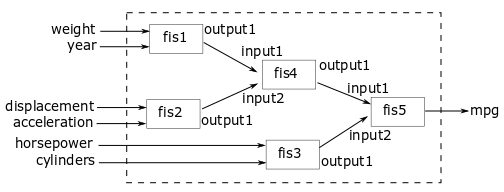
FIS树使用多个双输入一输出的FIS对象来减少推理过程中使用的规则总数。fis1,fis2和fis3直接获取输入值并生成中间值英里/加仑值,它们被进一步组合使用fis4和fis5。
将具有负相关值和正相关值的输入属性配对,以结合对输出的正影响和负影响进行预测。输入按其等级分组如下:
重量和型号年
位移和加速度
马力和气缸数
最后一组仅包括具有负相关值的输入,因为只有两个输入具有正相关值。
与Mamdani系统相比,本例使用sugeno类型的FIS对象在调优过程中更快地进行评估。每个FIS包括两个输入和一个输出,其中每个输入包含两个默认的三角隶属函数(MFs),输出包含4个默认常量MFs。使用相应的数据属性范围指定输入和输出范围。
第一个FIS结合了权重和模型年属性。
fis1=sugfis(“姓名”,“fis1”);fis1=附加输入(fis1,数据范围(4,:),“NumMFs”2,“姓名”,“重量”);fis1 = addInput (fis1 dataRange (6:)“NumMFs”2,“姓名”,“年”);fis1 = addOutput (fis1 dataRange (7:)“NumMFs”,4);
第二种FIS结合了位移和加速度属性。
fis2 = sugfis (“姓名”,“fis2”);fis2=附加输入(fis2,数据范围(2,:),“NumMFs”2,“姓名”,“位移”);fis2=附加输入(fis2,数据范围(5,:),“NumMFs”2,“姓名”,“加速”);fis2 = addOutput (fis2, dataRange (7:)“NumMFs”,4);
第三个FIS结合了马力和汽缸数量的属性。
fis3=sugfis(“姓名”,“fis3”); fis3=附加输入(fis3,数据范围(3,:),“NumMFs”2,“姓名”,“马力”); fis3=附加输入(fis3,数据范围(1,:),“NumMFs”2,“姓名”,“汽缸”);fis3 = addOutput (fis3 dataRange (7:)“NumMFs”,4);
第四个FIS结合了第一个和第二个FIS的输出。
fis4 = sugfis (“姓名”,“fis4”);fis4 = addInput (fis4 dataRange (7:)“NumMFs”2);fis4 = addInput (fis4 dataRange (7:)“NumMFs”2);fis4 = addOutput (fis4 dataRange (7:)“NumMFs”,4);
最后的FIS结合第三和第四个FIS的输出,生成估计的MPG。该FIS具有与第四个FIS相同的输入和输出范围。
fis5=fis4;五、姓名=“fis5”;fis5.输出(1).名称=“英里”;
构造FIS树
连接模糊系统(fis1,fis2,fis3,fis4和fis5)根据FIS树形图。
fisTin=fistree([fis1 fis2 fis3 fis4 fis5][...“fis1 / output1”“fis4 / input1”;...“fis2 / output1”“fis4 / input2”;...“fis3 / output1”“fis5/输入2”;...“fis4/输出1”“fis5/输入1”])
fisTin=fistree,具有以下属性:FIS:[1x5 sugfis]连接:[4x2字符串]输入:[6x1字符串]输出:“fis5/mpg”禁用结构检查:0有关参数优化,请参阅“getTunableSettings”方法。
使用训练数据调整FIS树
调整分两步进行。
学习规则库,同时保持输入和输出MF参数不变。
调整输入/输出MFs和规则的参数。
第一步由于规则参数少,计算量小,并且在训练过程中快速收敛到模糊规则库。在第二步中,使用第一步中的规则库作为初始条件,可以快速收敛参数调整过程。
学习规则
要了解规则库,请首先使用调谐器选项对象。全局优化方法(遗传算法或粒子群算法)适用于模糊系统所有参数未整定时的初始训练。对于本例,使用粒子群优化方法(“particleswarm”).
要学习新规则,请设置优化类型来“学习”。将最大规则数限制为4。每个FIS的优化规则数可以小于此限制,因为优化过程会删除重复的规则。
选择= tunefisOptions (“方法”,“particleswarm”,...“OptimizationType”,“学习”,...“NumMaxRules”,4);
如果您有Parallel Computing Toolbox™软件,您可以通过设置来提高调优过程的速度选项。UseParallel来符合事实的。如果没有并行计算工具箱软件,请设置选项。UseParallel来错误的。
将最大迭代次数设置为50。为了减少规则学习过程中的训练错误,可以增加迭代次数。但是,使用太多迭代可能会使FIS树与训练数据过度协调,从而增加验证错误。
options.MethodOptions.MaxIterations = 50;
由于粒子群优化使用随机搜索,为了获得可重复的结果,将随机数生成器初始化为其默认配置。
rng (“默认”)
使用指定的调整数据和选项调整FIS树。根据FIS树连接设置训练数据的输入顺序,如下所示:重量,年,取代,加快,马力和圆筒。
inputOrders1=[4 6 2 5 3 1];orderedTrnX1=trnX(:,inputOrders1);
学习规则tunefis功能大约需要4分钟。对于本例,通过设置启用调优runtunefis来符合事实的。在不运行的情况下加载预训练结果tunefis,您可以设置runtunefis来错误的。
runtunefis = false;
学习新规则时,参数设置可以为空。有关详细信息,请参阅tunefis。
如果runtunefis fisTout1=tunefis(fisTin,[],orderedTrnX1,trnY,options);% #好< UNRCH >其他的tunedfis=加载(“tunedfistreempgprediction.mat”);fisTout1 = tunedfis.fisTout1;fprintf('培训RMSE=%.3f MPG\n'calculateRMSE (fisTout1 orderedTrnX1 trnY));终止
训练RMSE=3.399英里/加仑
这个最好的f (x)列显示了训练均方根误差(RMSE)。
学习过程为FIS树生成一组新规则。
fprintf("规则总数= %d\n",numel([Fistut1.FIS.Rules]);
规则总数=17
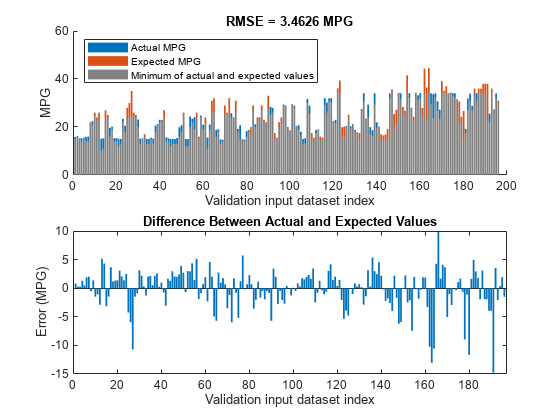
对于训练数据集和验证数据集,学习的系统应该具有相似的RMSE性能。要计算验证数据集的RMSE,请评估fisout1使用验证输入数据集vldX. 要在评估期间隐藏运行时警告,请将所有警告选项设置为没有一个。
计算生成的输出数据和验证输出数据集之间的RMSEvldY.由于培训和验证错误相似,学习系统不会过度拟合培训数据。
orderedVldX1 = vldX (:, inputOrders1);plotActualAndExpectedResultsWithRMSE (fisTout1 orderedVldX1 vldY)
调整所有参数
学习新规则后,调整输入/输出MF参数以及学习规则的参数。要获得FIS树的可调参数,请使用无法获取的设置作用
[in,out,rule]=getTunableSettings(Fistut1);
要在不学习新规则的情况下调整现有FIS树参数设置,请设置优化类型来“优化”。
options.OptimizationType=“优化”;
由于FIS树已经使用训练数据学习了规则,因此使用局部优化方法快速收敛参数值。对于本例,使用模式搜索优化方法(“模式搜索”).
选项。方法=“模式搜索”;
与上一个规则学习步骤相比,调整FIS树参数需要更多的迭代次数。因此,将调整过程的最大迭代次数增加到75次。与第一个调整阶段一样,可以通过增加迭代次数来减少训练错误。但是,使用过多的迭代次数可能会使参数过度调整到训练删除数据,增加验证错误。
options.MethodOptions.MaxIterations = 75;
为了改善模式搜索结果,设置方法选项使用CompletePoll这是真的。
options.MethodOptions.UseCompletePoll=true;
使用指定的可调设置、训练数据和调整选项调整FIS树参数。
用tunefis功能需要几分钟。在不跑步的情况下加载预先训练的结果tunefis,您可以设置runtunefis来错误的。
rng (“默认”)如果runtunefis fisTout2=tunefis(fisTout1[in;out;rule],orderedTrnX1,trnY,options);% #好< UNRCH >其他的fisTout2 = tunedfis.fisTout2;fprintf('培训RMSE=%.3f MPG\n'calculateRMSE (fisTout2 orderedTrnX1 trnY));终止
训练均方根误差= 3.037 MPG
在调整过程结束时,与上一步相比,训练误差减小。
检查性能
验证调整后的FIS树的性能,fisout2,使用验证输入数据集vldX。
比较从验证输出数据集获得的预期MPGvldY以及使用fisout2。计算这些结果之间的均方根误差。
绘图实际值和预期结果(fisTout2,订购VLDX1,vldY)
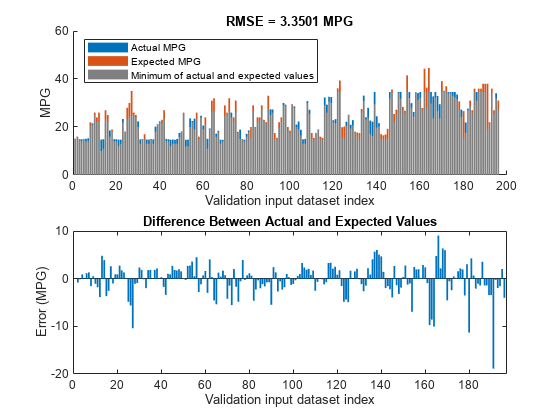
与初始学习规则库的结果相比,调整FIS树参数可以提高RMSE。由于训练误差和验证误差相似,因此参数值不会超调。
分析中间数据
为了深入了解模糊树的操作,可以将组件模糊系统的输出添加为FIS树的输出。对于本例,要访问中间FIS输出,需要向调优的FIS树添加三个额外的输出。
fisTout3=fisTout2;fisTout3.输出(结束+1)=“fis1 / output1”;财政部3.产出(结束+1)=“fis2 / output1”;财政部3.产出(结束+1)=“fis3 / output1”;
要生成附加输出,请评估增强的FIS树,fisTout3。
actY = evaluateFIS (fisTout3 orderedVldX1);图,plot(actY(:,[2 3 4 1])),xlabel(“输入数据集指数”), ylabel (“英里”),轴([1 200 0 55])“fis1输出”“fis2输出”“fis3输出”“fis5输出”],...“位置”,“东北”,“NumColumns”2)标题(“中期和最终产出”)
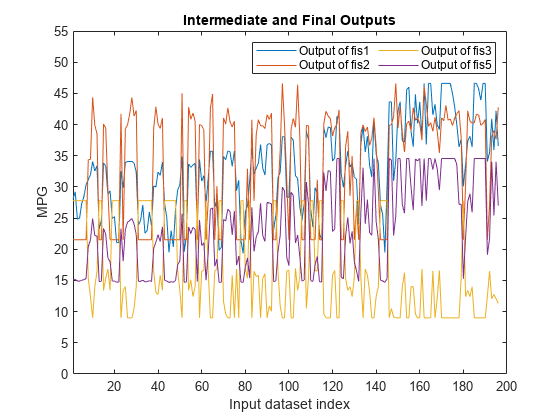
FIS树的最终输出(fis5产出)似乎与产出高度相关fis1和fis3.为验证该评估,请检查FIS输出的相关系数。
c2=corrcoef(actY(:,[2 3 4 1]);c2(完:)
ans=1×40.9541 0.8245 -0.8427 1.0000
相关矩阵的最后一行表示fis1和fis3(分别为第一列和第三列)与最终输出的相关性高于fis2(第二列)。这一结果表明,通过删除来简化FIS树fis2和fis4并且可以产生与原始树结构相似的训练结果。
简化并重新训练FIS树
去除fis2和fis4从FIS树连接的输出fis1到的第一个输入fis5。当您从FIS树中删除一个FIS时,到该FIS的任何现有连接也将被删除。
fistut3.FIS([2 4])=[];fistut3.Connections(end+1,:)=[“fis1 / output1”“fis5/输入1”]; fis5.输入(1).名称=“fis1out”;
要使FIS树输出的数量与训练数据中的输出数量匹配,请从中删除FIS树输出fis1和fis3。
fisTout3.Outputs(2:结束)= [];
根据新的FIS树输入配置更新输入训练数据顺序。
inputOrders2 = [4 6 3 1];orderedTrnX2 = trnX (:, inputOrders2);
由于FIS树配置已更改,因此必须重新运行学习和调优步骤。在学习阶段,现有的规则参数也被调整以适应FIS树的新配置。
选项。方法=“particleswarm”;options.OptimizationType=“学习”;options.MethodOptions.MaxIterations = 50;[~, ~,规则]= getTunableSettings (fisTout3);rng (“默认”)如果runtunefis fiout4 = tunefis(fiout3,rule,orderedTrnX2,trnY,options);% #好< UNRCH >其他的fisTout4=TunedFS.fisTout4;fprintf('培训RMSE=%.3f MPG\n'calculateRMSE (fisTout4 orderedTrnX2 trnY));终止
训练RMSE=3.380英里/加仑
在训练阶段,调整隶属函数和规则的参数。
选项。方法=“patternsearch”;options.OptimizationType=“优化”; options.MethodOptions.MaxIterations=75;options.MethodOptions.UseCompletePoll=true;[in、out、rule]=getTunableSettings(fisTout4);rng(“默认”)如果runtunefis fisTout5=tunefis(fisTout4[in;out;rule],orderedTrnX2,trnY,options);% #好< UNRCH >其他的fisTout5=tunedFS.fisTout5;fprintf('培训RMSE=%.3f MPG\n',计算器(fisTout5,orderedTrnX2,trnY));终止
训练RMSE=3.049英里/加仑
在调优过程的最后,FIS树包含更新的MF和规则参数值。新FIS树配置的规则库大小小于之前的配置。
fprintf("规则总数= %d\n",numel([fisTout5.FIS.Rules]);
规则总数=11
检查简化FIS树的性能
使用检查数据集的四个输入属性评估更新后的FIS树。
orderedVldX2 = vldX (:, inputOrders2);plotActualAndExpectedResultsWithRMSE (fisTout5 orderedVldX2 vldY)
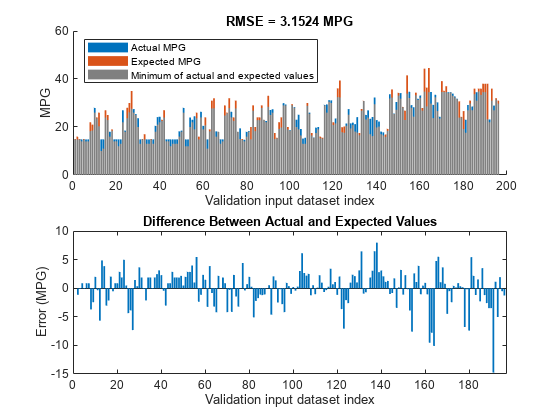
与使用六个输入属性的第一个配置相比,具有四个输入属性的简化FIS树在RMSE方面产生了更好的结果。因此,它表明,FIS树可以用较少的输入和规则来表示,以概括训练数据。
结论
可以通过以下方法进一步改善调整后的FIS树的训练误差:
在规则学习和参数调优阶段不断增加的迭代次数。这样做会增加优化过程的持续时间,还会增加由于训练数据的系统参数过优而导致的验证错误。
使用全局优化方法,例如
ga和粒子热,在规则学习和参数调优阶段。ga和粒子热由于它们是全局优化器,因此在较大的参数调整范围内表现更好。另一方面,patternsearch和同时退火对于较小的参数范围,性能更好,因为它们是本地优化器。如果已经使用培训数据将规则添加到FIS树中,则patternsearch和同时退火可以产生更快的收敛ga和粒子热。有关这些优化方法及其选项的更多信息,请参阅ga(全局优化工具箱),粒子热(全局优化工具箱),patternsearch(全局优化工具箱)和同时退火(全局优化工具箱)。更改FIS属性,例如FIS类型、输入数量、输入/输出MFs数量、MF类型和规则数量。对于具有大量输入的模糊系统,Sugeno FIS通常比Mamdani FIS收敛更快,因为Sugeno系统的输出MF参数更少(如果
常数使用MFs)和更快的解模糊。少量MFs和规则减少了要调整的参数数量,从而产生更快的调整过程。此外,大量规则可能会过度拟合训练数据。修改MFs和规则的可调参数设置。例如,您可以在不改变其峰值位置的情况下调优三角形MF的支持。金宝app这样做可以减少可调参数的数量,并为特定的应用程序生成更快的调优过程。对于规则,可以通过设置
AllowEmpty可调设置错误的,这减少了学习阶段的规则总数。改变FIS树的属性,如模糊系统的数量和模糊系统之间的连接。
使用FIS树输入的不同排序和分组。
局部函数
作用绘图实际结果和预期结果(fis、x、y)计算实际结果和预期结果之间的RMSE[rmse,actY]=计算器mse(fis,x,y);%绘制结果图次要情节(2,1,1)在巴(actY)巴(y)巴(min)巴(actY,y),“脸色”,[0.5 0.5 0.5])持有关xlabel([0 200 0 60])“验证输入数据集索引”), ylabel (“英里”)传奇([“实际MPG”“预期MPG”“实际值和期望值的最小值”],...“位置”,“西北”)标题(“RMSE=”+ num2str (rmse) +“MPG”) subplot(2,1,2) bar(actY-y) xlabel(“验证输入数据集索引”), ylabel (“错误(MPG)”)标题(“实际值与期望值之差”)终止作用[rmse, actY] = calculateRMSE (fis, x, y)%评估金融中间人actY = evaluateFIS (fis, x);%计算RMSEdel=actY-y;rmse=sqrt(平均值(^2));终止作用x y = evaluateFIS (fis)%指定FIS评估的选项持久的蒸发如果isempty(evalOptions) = evalfisOptions(“清空PutFuzzySetMessage”,“没有”,...“NoRuleFiredMessage”,“没有”,“OutOfRangeInputValueMessage”,“没有”);终止%评估金融中间人y=蒸发量(fis,x,蒸发量);终止
另见
相关的话题
您还可以从以下列表中选择网站:
