交互式装配
基本装配UI
matlab.®Basic Fitting UI允许你交互:
模型数据使用样条插值,形状保持插值,或十次多项式
与数据图的一个或多个组合在一起
画出拟合的残差
计算模型系数
计算残差的范数(一个可以用来分析模型与数据吻合程度的统计数据)
使用该模型在数据之外进行插值或外推
保存系数和计算值到MATLAB工作区对话框使用外
生成MATLAB代码,重新计算适合和复制图与新的数据
请注意
Basic Fitting UI仅适用于2d绘图。有关更高级的拟合和回归分析,请参阅曲线拟合工具箱™文档和统计学和机器学习工具箱™文档。
基本装配准备
基本拟合UI在拟合之前按升序对数据进行排序。如果您的数据集很大,并且值不是按升序排序的,那么在拟合之前,Basic Fitting UI将花费更长的时间对数据进行预处理。
您可以加快基础,首先分拣您的数据拟合UI。要创建排序向量x_sorted和y_sorted从数据向量x和y,使用MATLAB排序功能:
[x_sorted, i] = sort(x);y_sorted = y(我);
打开基本拟合UI
要使用基本拟合UI,你必须首先绘制在图窗口中的数据,使用任何MATLAB绘图产生命令(只)x和y数据。
要打开基本拟合界面,选择工具>基本拟合从图窗口顶部的菜单。
示例:使用基本装配UI
这个例子说明了如何使用基本拟合UI,以适应,可视化,分析,保存和生成多项式回归代码。
装载并绘制人口普查数据
该文件census.mat包含在10年为间隔的1790年到1990年美国人口数据。
要加载和绘制数据,在MATLAB提示符下输入以下命令:
加载人口普查情节(cdate、流行,“罗”)
的加载命令将以下变量到MATLAB工作区:
CDATE-列向量,以10为增量,包含从1790年到1990年的年份。它是预测变量。流行-列向量与美国人口每年在CDATE.它是响应变量。
数据载体以升序,按年份排序。该图显示了人口一年的函数。
现在,您可以随着时间的推移,以适应一个方程的数据模型的人口增长。
用三次多项式拟合预测人口普查数据
通过选择打开基本装配对话框工具>基本拟合在Figure窗口中。
在类型的适合基本拟合对话框的区域,选择立方体复选框,以适应三次多项式的数据。

MATLAB使用您的选择来拟合数据,并将三次回归线添加到图中,如下所示。

在计算合适,MATLAB遇到困难和问题下面的警告:
这一警告表明,模型的计算系数对响应(测量总体)中的随机误差很敏感。它还建议你做一些事情来获得更好的适合。
继续使用立方匹配。由于不能向人口普查数据添加新的观察值,因此可以通过转换必须的值来提高适合度z得分在重新计算合适之前。选择居中并缩放x轴数据复选框,以使基本装配工具执行转换。
要了解数据如何定心和缩放,请参见学习如何基本拟合工具计算适合.
下误差估计(残差),选择规范的残差复选框。选择酒吧随着情节风格.





选择这些选项创建残差为条形图的插曲。
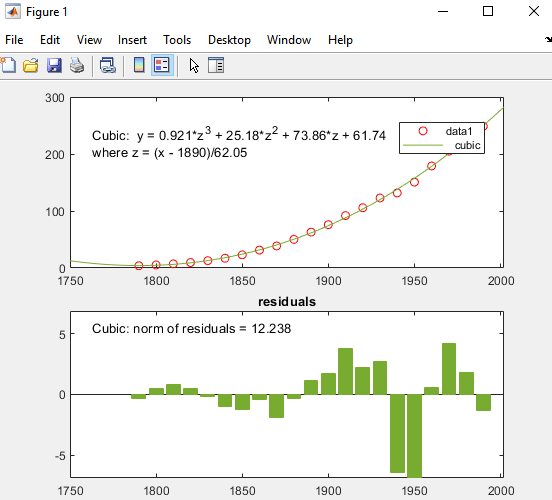
在1790年之前,立方拟合是一个很差的预测,因为它预示着人口的减少。这个模型似乎很好地逼近了1790年以后的数据。然而,残差中的一个模式表明,模型不满足正态误差的假设,这是最小二乘拟合的基础。的数据1在图例标识的线所观察到的x(CDATE)和y(流行)的数据值。的立方体回归线礼物中心和缩放数据值后的契合。请注意,该图显示了原始数据单元,即使该工具计算使用转化z分数的拟合。
为了进行比较,试图通过在中选择安装另一个多项式方程的人口普查数据类型的适合地区。
查看并保存立方匹配参数
在“基本装配”对话框中,单击扩张的结果按钮![]() 显示估计系数和残差范数。
显示估计系数和残差范数。

将拟合数据保存到MATLAB工作区,单击导出到工作区数值结果面板上的按钮。打开另存调整到工作区对话框。
选中所有复选框,单击好吧于拟合参数保存为MATLAB结构适合:
适合
适合=具有字段的结构:类型: '多项式度3' _系数:0.9210 25.1834 73.8598 61.7444]
现在,您可以在MATLAB编程中使用拟合结果,在基本拟合UI之外。
R2,决定系数
通过计算,你可以得到多项式回归预测观测数据的指示确定系数,或r平方(写为R2).R2统计量,范围从0到1,衡量自变量在预测因变量值方面的作用:
的R2值接近0表示拟合并不比模型好多少
y =常数.的R2值接近1表示自变量解释了因变量的大部分变异性。
R2从计算残差,即观察到的相关值与适合度预测值之间的有符号差异。
| 残差= Y观察到的- ÿ安装 | (1) |
R2本例中立方拟合的编号0.9988位于拟合结果在基本装配对话框中。
为了比较R2数立方拟合为线性最小二乘拟合,选择线性下类型的适合并获得将R2数0.921。该结果表明,线性最小二乘方拟合的人口数据的解释了其方差的92.1%。作为该数据的三次拟合解释方差的99.9%,后者似乎是一个更好的预测。然而,由于三次拟合预测使用三个变量(x,x2,x3.),一个基本科研2价值没有充分反映配合如何健壮。评价多元拟合优度更适当的措施是调整后的R2.有关计算和使用调整后的R2,请参阅残差与拟合优度.
插入和外推总体值
假设您想使用立方模型来插值1965年(原始数据中未提供的日期)的美国人口。
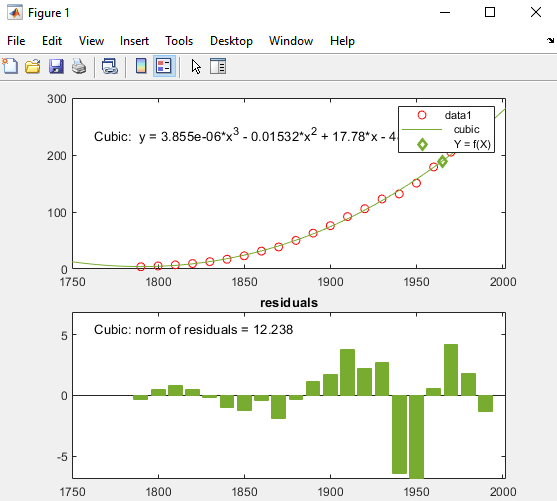
在基本装配对话框中,在插入/外推数据,进入X1965年的价值,并检查情节评估数据盒子。
请注意
使用未缩放和非中心X值。您不需要先居中和缩放,即使您选择了缩放X值来获得系数用三次多项式拟合预测人口普查数据.基本拟合工具,使得在幕后进行必要的调整。

的X的值和相应的值F(X)根据拟合计算,并绘制如下图:
生成代码文件以重现结果
在完成Basic Fitting会话后,可以生成MATLAB代码,重新计算fit并使用新数据重新绘制图。
在Figure窗口中,选择文件>生成代码.
这会在MATLAB编辑器的功能并显示它。代码显示了如何以编程方式重现你的基本的拟合对话框中所做的交互。
更改函数的名称来自第一线
createfigure更具体的东西,比如censusplot.代码文件保存到当前文件夹中的文件名censusplot.m函数的开头是:函数censusplot(X1, Y1, valuesToEvaluate1)
生成一些新的、随机扰动的人口普查数据:
rng (“默认”) randpop = pop + 10*randn(size(pop));用新数据重新绘制图,并重新计算适合度:
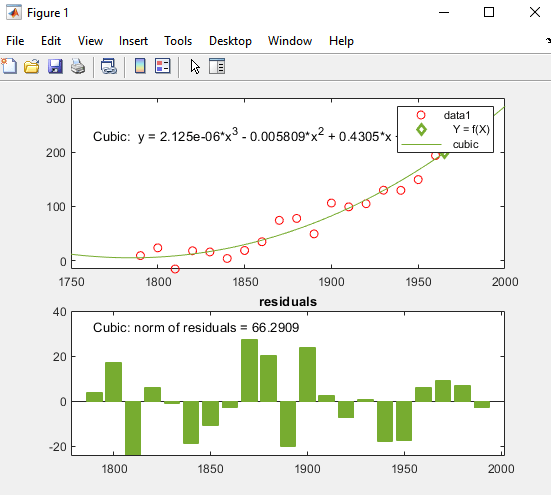
censusplot(CDATE,randpop,1965)
你需要三个输入参数:x, y值(
数据1),加上anx-VALUE为一个标记。下图显示了生成的代码生成的图形。新图的外观与生成代码的图的外观相匹配,但y数据值,立方拟合方程,柱状图中的残差值,如预期。

学习如何基本拟合工具计算适合
基本装配工具调用polyfit函数来计算多项式拟合。它调用polyval函数来评估适合度。polyfit分析其输入,以确定是否该数据是公调理配合的要求程度。
当它发现条件很差的数据时,polyfit尽可能地计算回归,但它也返回一个警告,表明适合度可以改进。基本拟合示例部分用三次多项式拟合预测人口普查数据显示这个警告。
以提高模型可靠性的一种方法是添加的数据点。然而,增加观测数据集并不总是可行的。另一种策略是改变预测变量正常化其中心和规模。(在该示例中,预测器是人口普查日期的矢量。)
的polyfit函数通过计算进行规范化z得分:
在哪里x是预测数据,μ是平均的x,σ的标准差是x.的z-scores给出的数据为0均值为1的标准差在基本拟合UI,你变换预测数据z-scores通过选择居中并缩放x轴数据复选框。
中心和缩放后,模型的系数计算的y数据作为的函数的z.这些是不同的(和更健壮的)比对计算的系数y作为一个功能x.模型的形式和残差的范数不变。基本装配UI自动缩放z-分数,使拟合图在相同的比例,以原始x数据。
要理解居中和缩放的数据是如何作为中间元素来创建最终图形的,请在命令窗口中运行以下代码:
关闭负载人口普查x = cdate;y =流行;z = (x-mean (x) /性病(x);%计算x数据的z-scores绘图(x,y,“罗”)%用红色标记标记数据持有在%准备坐标轴以接受顶部的新图形zfit = linspace (z(1)、z(结束),100);pz = polyfit (z, y, 3);%计算条件适合yfit = polyval (pz、zfit);xfit = linspace (x(1),(结束),100);情节(xfit yfit,“b -”)%绘制条件拟合与x数据
居中并缩放的三次多项式以蓝线表示,如下所示:

在代码中,计算z说明如何规范化数据。的polyfit如果在调用函数时提供三个返回参数,则函数会自己执行转换:
[P,S,μ= polyfit(X,Y,n)的
p,现在是基于规范化的x.返回向量,μ包含的平均值和标准偏差x.有关更多信息,请参见polyfit参考页面。
你也可以从以下列表中选择一个网站:
