线性回归
介绍
数据模型明确描述了两者之间的关系预测和响应变量。线性回归适合模型系数中线性的数据模型。最常见的线性回归是一个最小二乘适合,它可以拟合直线和多项式,以及其他线性模型。
在对数量对之间的关系进行建模之前,执行相关性分析以建立线性关系在这些数量之间是一个好主意。请注意,变量可以具有非线性关系,相关分析无法检测到。有关更多信息,请参阅线性相关.
MATLAB®基本拟合UI帮助您拟合数据,因此您可以计算模型系数并在数据上绘制模型。例如,请参见示例:使用基本装配UI.您也可以使用matlabPolyfit.和polyval函数使你的数据符合系数为线性的模型。例如,请参见程序拟合.
如果你需要用非线性模型来拟合数据,那么转换变量使关系线性化。或者,尝试直接使用统计学和机器学习工具箱来拟合非线性函数nlinfit函数,优化工具箱™lsqcurvefit.函数,或在曲线拟合工具箱™中应用函数。
本主题解释了如何:
执行简单的线性回归使用
\操作符。使用相关分析来确定两个量是否相关以证明数据的拟合。
用线性模型拟合数据。
通过绘制残差和寻找模式来评估拟合的优度。
计算合适r的良好度量2R和调整2
简单的线性回归
这个例子展示了如何使用事故数据集。该示例还向您展示了如何计算确定系数
评估回归。这事故数据集包含美国各州致命交通事故的数据。
线性回归模拟依赖或响应,变量之间的关系 和一个或多个独立或预测的变量变量 .简单线性回归只考虑使用关系的一个自变量
在哪里 是y-erlcept, 是斜坡(或回归系数),和 为误差项。
从一组开始 观测值的 和 给出的 那 、…… .利用简单的线性回归关系,这些值形成一个线性方程组。用矩阵形式表示这些方程为
让
关系现在 .
在Matlab中,你可以找到
使用mldivide操作员B = X、Y.
从数据集事故,载入事故数据y和国家人口数据X.找出线性回归关系
一个州的事故数量和这个州的人口数量之间\操作符。这\运算符执行最小二乘回归。
加载事故x = hwydata (: 14);%国家群体: y = hwydata (4);%事故/状态格式长b1 y = x \
b1 = 1.372716735564871 e-04
B1为斜率或回归系数。线性关系是
.
计算每个州的事故ycalc.从X使用的关系。通过绘制实际值来可视化回归y和计算的值ycalc..
yCalc1 = b1 * x;散射(x, y)在情节(x, yCalc1)包含(国家的人口) ylabel (“每个州的致命交通事故”)标题(“事故与人口的线性回归关系”网格)在
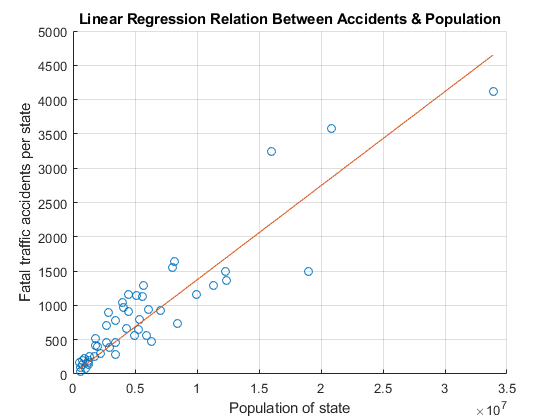
通过包含y轴截距来改善配合
在你的模型中
.计算
通过填充X一列1,用\操作符。
x = [x(长度(x),1)x];b = x \ y
b =2×1102×1.427120171726538 - 0.000001256394274
这个结果代表了关系 .
通过在同一个图中绘制它来可视化关系。
Ycalc2 = x * b;plot(x,ycalc2,' - ')传说(“数据”那'坡'那的斜率和拦截那“位置”那“最佳”);
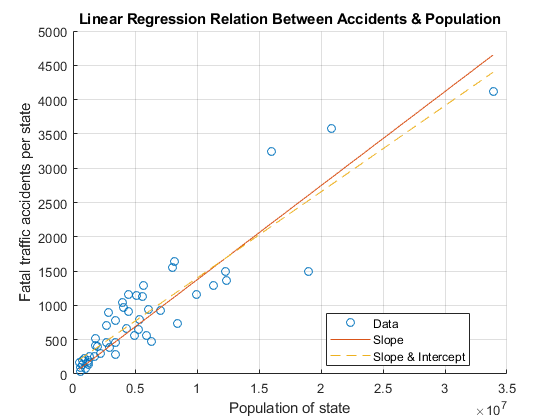
从图上看,这两件衣服看起来很相似。找到更合适的方法之一是计算决定系数, . 这是一个衡量模型预测数据好坏的指标吗 和 .值越高 ,模型对数据的预测就越好。
在哪里 表示计算值 和 的平均值 那 被定义为
通过比较的值,找到两个拟合的更好的拟合 .随着 值表明,包含y截距的第二次拟合更好。
RSQ1 = 1 - SUM((Y - YCALC1)。^ 2)/总和((y - 平均值(y))。^ 2)
Rsq1 = 0.822235650485566
RSQ2 = 1 - SUM((Y - YCALC2)。^ 2)/总和((y - 平均值(y))。^ 2)
RSQ2 = 0.838210531103428
残差与拟合优度
残差是观察到的响应(因变量)值和模型值预测.当您拟合一个适合您的数据的模型时,残差近似于独立随机误差。也就是说,残差的分布不应该呈现出明显的模式。
使用线性模型进行拟合需要最小化残差的平方和。这种最小化产生了所谓的最小二乘拟合。你可以通过观察残差图来洞察匹配的“优劣”。如果残差图有一个模式(即残差数据点没有出现随机散点),随机性表明模型没有适当地拟合数据。
在你的数据背景下评估你的每一个匹配度。例如,如果您拟合数据的目标是提取具有物理意义的系数,那么您的模型必须反映数据的物理性质。在评估拟合优度时,了解数据代表什么、如何测量它以及如何建模非常重要。
适合度的一个衡量标准是确定系数,或R2(发音为R-Square)。此统计信息表示您从拟合模型匹配的型号符合型号的旨在预测的依赖性变量的匹配程度如何。统计学家经常定义r2使用拟合模型的剩余方差:
R.2= 1 - SS渣油/党卫军总计
党卫军渣油是回归的残差平方和。党卫军总计是来自因变量的平均值的平方差的总和(总平方和)。两者都是正标量。
学习如何计算R2当您使用基本装配工具时,请参见R2,决定系数.了解有关计算r的更多信息2统计和它的多元泛化,继续阅读这里。
示例:计算r2从多项式适合
你可以推出R2从多项式回归系数来确定有多少方差y一个线性模型解释,如下面的例子所描述:
创建两个变量,
X和y的前两列数数数据文件中的变量count.dat:Load count.dat x = count(:,1);y = count (:, 2);
使用
Polyfit.计算一个线性回归来预测y从X:p = Polyfit(x,y,1)p = 1.5229 -2.1911
(1页)为斜率(2页)为线性预测器的截距。您还可以使用基本拟合界面.调用
polyval使用P.预测y,称之为结果YFIT.:YFIT = Polyval(p,x);
使用
polyval保存您自己键入Fit方程,在这种情况下,这看起来像:Yfit = p(1) * x + p(2);
将剩余值计算为签名数字的向量:
Yresid = y - yfit;
将残差平方求和,得到残差平方和:
SSresid =总和(yresid。^ 2);
计算总和的正方形
y乘以的方差y通过观察数减去1:SStotal = (length(y)-1) * var(y);
计算R2利用本课题导言中给出的公式:
这证明了线性方程RSQ = 1 - SSRESID / SSTotal RSQ = 0.8707
1.5229 * x -2.1911预测变量方差的87%y.
计算调整后R.2对多项式回归
你通常可以通过拟合高次多项式来减少模型中的残差。当你增加更多项时,你增加了决定系数,R2.你可以更接近数据,但代价是一个更复杂的模型,对于R2无法解释。但是,这种统计数据的改进,调整R.2,确实包括用于模型中的术语数量的罚款。调整R.2,因此,更适合于比较不同的模型如何适合相同的数据。调整R2被定义为:
R.2调整= 1 - (SS渣油/党卫军总计) * ((N.-1)/(N.-D.1))
下面的示例重复了前一个示例的步骤,例如:用多项式拟合计算R2,但执行立方(3度)拟合,而不是线性(1度)拟合。根据立方拟合,可以计算简单的和调整后的R2值来评估额外条款是否提高预测能力:
创建两个变量,
X和y的前两列数数数据文件中的变量count.dat:Load count.dat x = count(:,1);y = count (:, 2);
调用
Polyfit.生成一个立方拟合来预测y从X:P = Polyfit(X,Y,3)P = -0.0003 0.0390 0.2233 6.2779
(4页)为三次预测器的截距。您还可以使用基本拟合界面.调用
polyval使用系数P.预测y,命名结果YFIT.:YFIT = Polyval(p,x);
polyval计算你可以手动输入的显式方程:Yfit = P(1)* x。^ 3 + p(2)* x。^ 2 + p(3)* x + p(4);
将剩余值计算为签名数字的向量:
Yresid = y - yfit;
将残差平方求和,得到残差平方和:
SSresid =总和(yresid。^ 2);
计算总和的正方形
y乘以的方差y通过观察数减去1:SStotal = (length(y)-1) * var(y);
计算简单的R.2对于使用本主题介绍中给出的公式进行三次拟合:
rsq = 1 - SSresid/SStotal
最后,计算调整后的R2要考虑自由度:
调整R2, 0.8945,小于简单R2, .9083。它为多项式模型的预测能力提供了更可靠的估计。RSQ_ADJ = 1 - SSRESID / SSTOTOL *(长度(y)-1)/(长度(y) - 长度(p))rsq_adj = 0.8945
在许多多项式回归模型中,向等式增加术语增加了r2R和调整2.在前面的例子中,与线性拟合相比,使用立方拟合增加了两个统计量。(可以计算调整后的R2为你自己的线性拟合证明它有一个较低的值)然而,线性拟合并不总是比高阶拟合差:更复杂的拟合可以有更低的调整R2这表明增加的复杂性是不合理的。同时,R2对于基本拟合工具生成的多项式回归模型,调整后的R,总是在0和1之间变化2对于某些模型可能是负面的,表示一个模型有太多的项。
相关性并不意味着因果关系。始终将相关性和谨慎射出的系数。系数仅量化拟合模型删除的依赖变量中的差异量。这些措施不会描述您选择的模型或选择的独立变量的效果如何用于解释模型预测的变量的行为。
拟合数据曲线拟合工具箱功能
曲线拟合工具箱软件通过启用以下数据拟合功能来扩展核心MATLAB功能:
线性和非线性参数拟合,包括标准线性最小二乘,非线性最小二乘,加权最小二乘,约束最小二乘和强大的拟合程序
非参数拟合
用于确定拟合优度的统计学
推断,分化和集成
对话框,方便数据切片和平滑
以各种格式保存拟合结果,包括MATLAB代码文件,MAT文件和工作区变量
有关更多信息,请参阅曲线拟合工具箱文档。
你也可以从以下列表中选择一个网站:
