说明GPU计算的三种方法:曼德尔布罗特集
此示例显示了如何在MATLAB®代码中表达简单,众所周知的数学问题,Mandelbrot Set。然后使用并行计算工具箱™此代码适用于三种方式使用GPU硬件:
使用现有算法,但使用GPU数据作为输入
使用
Arrayfun.对每个元素单独执行算法使用MATLAB/CUDA接口运行一些现有的CUDA/ c++代码
设置
下面的值指定了曼德尔布罗特集合在主心脏线和左侧p/q灯泡之间的山谷中高度缩放的部分。

在这些限制之间创建1000x1000格的实部(x)和虚部(y),并且在每个网格位置迭代Mandelbrot算法。对于该特定位置,500次迭代将足以完全呈现图像。
最大= 500;gridsize = 1000;XLIM = [-0.748766713922161,-0.7487667077771757];ylim = [0.12364084894862,0.123640851045266];
在matlab中设置的mandelbrot
下面是使用在CPU上运行的标准MATLAB命令的Mandelbrot设置。这是基于Cleve Moler中提供的代码“与MATLAB实验”电子书。
此计算被矢量化,使得每个位置一次更新。
% 设置t =抽搐();x = linspace(xlim(1), xlim(2), 1);y = linspace(ylim(1), ylim(2), gridSize);[xGrid,yGrid] = meshgrid(x, y);z0 = xGrid + 1i*yGrid;count = ones(size(z0));% 计算z = z0;为了n = 0:maxIterations z = z.*z + z0;inside = abs(z)<=2;count = count + inside;结尾count = log(count);%显示cputime = toc(t);图= GCF;Fig.Position = [200 200 600 600];ImageC(x,y,count);Colormap([Jet(); Flipud(Jet()); 0 0 0]);轴从标题(Sprintf(' % 1.2 fsecs (GPU) ', cpuTime);

使用GPUArray.
当MATLAB遇到GPU上的数据时,利用这些数据在GPU上进行计算。类GPUArray.提供可用于创建数据阵列的许多功能的GPU版本,包括Linspace.那logspace,meshgrid这里需要的功能。同样,数数使用该函数在GPU上直接初始化array的。
随着这些改变的数据初始化计算将现在在GPU上执行:
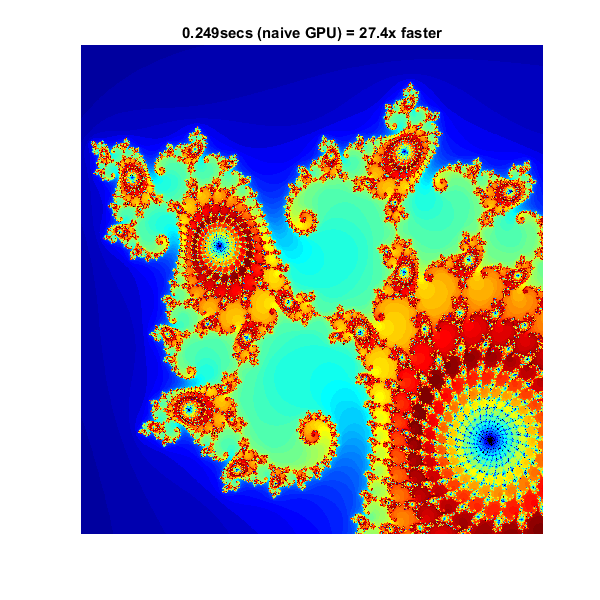
% 设置t =抽搐();x = gpuarray.linspace(xlim(1),xlim(2),gridsize);y = gpuarray.linspace(ylim(1),ylim(2),gridsize);[xGrid,yGrid] = meshgrid(x, y);z0 = complex(xGrid, yGrid);count = 1 (z0),“gpuArray”);% 计算z = z0;为了n = 0:maxIterations z = z.*z + z0;inside = abs(z)<=2;count = count + inside;结尾count = log(count);%显示count =聚集(计数);%从GPU获取回来的数据naiveGPUTime = toc(t);ImageC(x,y,count)轴从标题(Sprintf('%1.3fsecs(天真GPU)=%1.1fx更快'那......天真仿血液,Cutime / NaiveGputime))
元素明智的操作
注意,该算法对输入的每个元素都相等地操作,我们可以将代码放在一个助手函数中,并使用Arrayfun.。对于GPU阵列输入,所用功能Arrayfun.编译成本地GPU代码。在本例中,我们放入了循环pctdemo_processMandelbrotElement.m:
函数count = pctdemo_processmandelbrotelement(x0,y0,maxIrlations)z0 =复合物(x0,y0);z = z0;count = 1;虽然(count <= maxIrtations)&&(abs(z)<= 2)count = count + 1;z = z * z + z0;结束count = log(count);
注意,引入了一个早期中止,因为这个函数只处理一个元素。对于Mandelbrot集合的大多数视图,大量元素在很早就停止,这可以节省大量处理。的为了循环也被一个取代而循环因为它们通常更有效。此函数没有提及GPU并使用GPU特定功能 - 它是标准的MATLAB代码。
使用Arrayfun.意味着代替数以千计的呼叫来分隔GPU优化的操作(每个迭代至少6个),我们将一个调用一个调用执行整个计算的并行化GPU操作。这显着减少了开销。
% 设置t =抽搐();x = gpuarray.linspace(xlim(1),xlim(2),gridsize);y = gpuarray.linspace(ylim(1),ylim(2),gridsize);[xGrid,yGrid] = meshgrid(x, y);% 计算count = arrayfun(@pctdemo_processMandelbrotElement,......xGrid, yGrid, maxIterations);%显示count =聚集(计数);%从GPU获取回来的数据gpuarrayfuntime = toc(t);ImageC(x,y,count)轴从标题(Sprintf('%1.3fsecs (GPU arrayfun) = %1.1fx faster'那......gpuarrayfuntime,cputime / gpuarrayfuntime)));

与CUDA合作
在MATLAB实验通过将基本算法转换为C-MEX函数来实现改进的性能。如果您愿意在C / C ++中做一些工作,那么您可以使用并行计算工具箱来使用MATLAB数据呼叫预先写的CUDA内核。你这样做parallel.gpu.CUDAKernel特性。
一个CUDA/ c++实现的元素处理算法已经手工编写pctdemo_processmandelbrotelement.cu.:必须使用nVidia的NVCC编译器手工编译,以生成程序集级别pctdemo_processMandelbrotElement.ptx(.ptx代表“并行线程执行语言”)。
由于C ++中缺乏复杂数字,CUDA / C ++代码比我们所看到的MATLAB版本更多。但是,算法的本质不变:
__device__ unsigned int doIterations(double const realPart0, double const imagPart0, unsigned int const maxerrors) {// Initialize: z = z0 double realPart = realPart0;double imagPart = imagPart0;unsigned int count = 0;//循环直到escape while ((count <= maxers) && ((realPart*realPart + imagPart*imagPart) <= 4.0)) {++count;//更新:z = z*z + z0;double const oldRealPart = realPart;realPart = realPart*realPart - realPart*realPart + realPart0;imagPart = 2.0*oldRealPart*imagPart + imagPart0;}返回计数;}
在Mandelbrot集合中需要一个GPU线程,线程被分组成块。内核指示了线程块的大小,在下面的代码中,我们使用它来计算所需的线程块数量。这就变成了网格化。
%加载内核cudaFilename ='pctdemo_processmandelbrotelement.cu';ptxFilename = ['pctdemo_processmandelbrotelement。'parallel.gpu.ptxext);内核= parallel.gpu。CUDAKernel(pcxfilename, cudaFilename);% 设置t =抽搐();x = gpuarray.linspace(xlim(1),xlim(2),gridsize);y = gpuarray.linspace(ylim(1),ylim(2),gridsize);[xGrid,yGrid] = meshgrid(x, y);%确保我们有足够的块来涵盖所有位置numElements = nummel (xGrid);内核。ThreadBlockSize = (kernel.MaxThreadsPerBlock 1 1);内核。GridSize = [(numElements / kernel.MaxThreadsPerBlock),即:1);%打电话给内核count = 0 (size(xGrid)),“gpuArray”);count = feval(kernel, count, xGrid, yGrid, maxIterations, numElements);%显示count =聚集(计数);%从GPU获取回来的数据gpucudakerneltime = toc(t);ImageC(x,y,count)轴从标题(Sprintf('%1.3fsecs(gpu cudakernel)=%1.1fx更快'那......gpucudakerneltime,cputime / gpucudakerneltime)));

总结
此示例显示了三种方式,其中MATLAB算法可以适用于使用GPU硬件:
将输入数据转换为使用的GPU
GPUArray.,保留算法不变使用
Arrayfun.在A.GPUArray.对输入的每个元素单独执行算法使用
parallel.gpu.CUDAKernel使用MATLAB数据运行一些现有的CUDA / C ++代码
标题('Mandelbrot在GPU上设置)

您也可以从以下列表中选择一个网站: