使用诊断特征设计器探索集成数据和比较特征
的诊断功能设计应用程序允许您使用多功能图形界面完成预测性维护工作流程的功能设计部分。交互式地设计和比较功能。然后,确定哪些特征最擅长区分来自不同组的数据,比如来自标称系统的数据和来自故障系统的数据。如果您有运行到故障的数据,您还可以评估哪些特性最适合确定剩余使用寿命(RUL)。最有效的特性最终会成为故障诊断和预测的条件指示器。
下图说明了预测性维护工作流程与诊断功能设计功能。
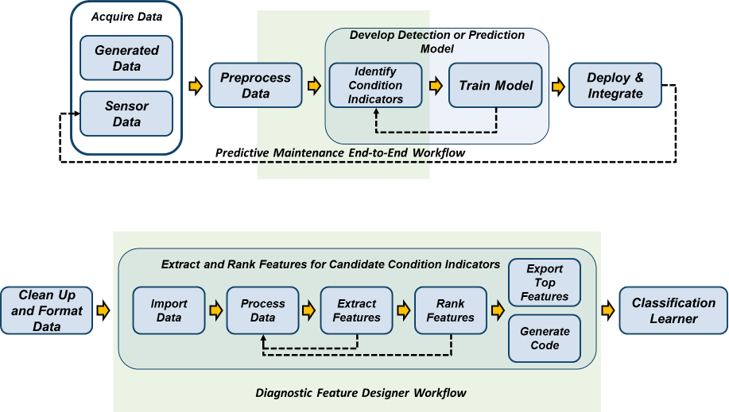
该应用程序在集成数据上运行。集成数据包含来自多个成员(如多个相似的机器)的数据度量,或单个机器(其数据按时间间隔(如天或年)分割)的数据度量。数据还可以包含描述集成成员故障状态或运行状态的条件变量。条件变量的定义值通常为标签.有关数据集的更多信息,请参见用于状态监测和预测维护的数据集成.
应用内工作流从数据导入点开始:
使用清理函数进行预处理
组织成单个数据文件或包含或引用所有集成成员的单个集成数据文件
在诊断功能设计,工作流包括进一步处理数据所需的步骤,从数据中提取特征,并根据有效性对这些特征进行排序。工作流程以选择最有效的特性并将这些特性导出到分类学习者模型培训的应用程序。
该工作流包括一个可选的MATLAB®代码生成步骤。当您生成捕获所选择特性的计算的代码时,您可以为包含更多成员的更大的度量数据集自动进行这些计算,比如来自不同工厂的类似机器。生成的特征集提供了额外的训练输入分类学习者.
使用诊断功能设计器执行预测性维护任务
的基本功能诊断功能设计.控件等选项卡中的控件与数据和结果交互功能设计选项卡,如图所示。控件中查看导入和派生的变量、特性和数据集数据浏览器.在绘图区域中可视化您的结果。

将导入数据转换为统一集成数据集
使用应用程序的第一步是导入数据。您可以从表、时间表或矩阵导入数据。您还可以导入一个集成数据存储,其中包含允许应用程序与外部数据文件交互的信息。您的文件可以包含实际或模拟的时域测量数据、光谱模型、变量名称、条件和操作变量,以及以前生成的特性。诊断功能设计将所有成员数据组合成一个集成数据集。在这个数据集中,每个变量都是一个集合信号或模型,其中包含所有单独的成员值。
要在多个会话中使用相同的数据,可以保存初始会话。会话数据既包括导入的变量,也包括计算出的任何其他变量和特性。然后,你可以在使用应用程序的任何时候打开会话。
有关为导入过程准备数据的信息,请参见:
有关导入过程本身的信息,请参见在诊断特征设计器中导入和可视化集成数据.
可视化数据
要绘制您导入或使用处理工具生成的信号或光谱,请从图图库中选择。图中显示了一个典型的信号道。交互式绘图工具允许您平移、缩放、显示峰值位置和峰值之间的距离,并显示集合内的统计变化。根据图中的条件标签对数据进行分组,可以清楚地看到成员数据是来自(例如)标称系统还是故障系统。

有关应用程序中绘图的信息,请参见在诊断特征设计器中导入和可视化集成数据.
计算新变量
要研究数据并为特征提取准备数据,请使用数据处理工具。每次你应用一个处理工具,应用程序创建一个新的派生变量,它的名字包含源变量和你使用的处理。例如,如果你从变量计算功率谱振动/数据,新的派生变量名为Vibration_ps /数据.
所有信号的数据处理选项包括集合级统计,信号残差,滤波,功率和阶谱。如果成员样本没有以相同的独立变量间隔出现,您还可以将数据插入到统一的网格中。
如果您的数据来自旋转机械,您可以执行时间同步信号平均(TSA)基于您的转速表输出或您的名义转速。从TSA信号,您可以产生额外的信号,如TSA残差信号和差值信号。这些来自tsa的信号通过保留或丢弃谐波和边带来隔离系统中的物理部件,它们是许多齿轮状况特征的基础。
许多处理选项都可以独立使用。有些选项可以或必须作为序列执行。除了前面讨论的旋转机械和TSA信号外,另一个例子是任何信号的残留产生。您可以:
使用系综统计生成代表整个集合特征的单成员统计变量,如均值和Max。
使用减去参考通过减去集合级值来生成每个成员的剩余信号。这些残差代表了信号之间的变化,并更清楚地揭示了偏离集合的其余部分的信号。
使用这些剩余信号作为附加处理选项或特征生成的源。
有关应用程序中数据处理选项的信息,请参见在诊断特征设计器中处理数据和探索特征.
计算选择
该应用程序提供了信号分段、集成数据存储值的本地应用内缓冲和并行处理的选项。
默认情况下,应用程序在一个操作中处理你的整个信号。您还可以分割信号并处理各个帧。如果集成中的成员表现出非平稳、时变或周期性的行为,基于帧的处理尤其有用。基于帧的处理还支持预测排序,因为它提供了特征值的时间历史金宝app。
当你将成员数据导入到应用中时,应用会创建一个本地集成,并向该集成中写入新的变量和特性。当你导入一个集成数据存储对象时,应用程序默认会与对象中列出的外部文件进行交互。如果你不希望应用程序写入你的外部文件,你可以选择让应用程序创建一个本地集合,并在那里写入结果。得到想要的结果后,可以将集成导出到MATLAB工作空间。在此基础上,可以使用命令行集成数据存储函数将希望保留到源文件中的变量和特性编写出来。有关集成数据存储的更多信息,请参见用于状态监测和预测维护的数据集成.
如果您有Parallel Computing Toolbox™,则可以使用并行处理。因为应用程序经常独立地对所有成员执行相同的处理,并行处理可以显著地提高计算时间。
生成功能
从原始和导出的信号和频谱,您可以计算特征并评估其有效性。您可能已经知道哪些特性可能工作得最好,或者您可能想对所有适用的特性进行试验。可用的特征范围从一般信号统计到可以识别故障精确位置的特殊齿轮状态指标,以及突出混沌行为的非线性特征。
每当你计算一组功能时,应用就会将它们添加到功能表中,并生成成员间值分布的直方图。该图展示了两个特征的直方图。直方图说明了每个特征如何很好地区分数据。例如,假设您的条件变量是faultCode与国家0用于标称系统数据和1对于故障系统数据,如图所示。您可以在直方图中看到,标称分组和错误分组是否会导致不同的或混合的直方图箱子。您可以一次查看所有功能直方图,或者选择应用程序在直方图集中包含哪些功能。

要比较所有特性的值,请使用特性表视图和特性跟踪图。特性表视图显示了所有集成成员的所有特性值的表。特征轨迹绘制这些值。此图可视化了集成中特征值的差异,并允许您识别特征值所代表的特定成员。
关于应用中功能生成和直方图解释的信息,请参见:
等级特性
直方图允许您执行特性有效性的初步评估。要执行更严格的相对评估,可以使用专门的统计方法对特征进行排序。该应用程序提供两种类型的排名-分类排名和预后排名.
分类排序方法通过区分数据组之间或数据组之间(如名义行为和错误行为之间)的能力对特征进行评分和排序。分类排序要求条件变量包含描述数据组的标签
预测排序方法根据跟踪退化的能力对特征进行评分和排序,以便能够预测剩余使用寿命(RUL)。预排序需要真实或模拟的运行到故障或故障进展数据,并且不使用条件变量。
图中显示了分类排名结果。您可以尝试多种排序方法,并同时查看每种方法的结果。通过排名结果,您可以消除无效的特征,并在计算派生变量或特征时评估参数调整的排名效果。

有关特性排名的信息,请参见:
诊断功能设计排名功能选项卡和技术排名部分
输出特征到分类学习者
定义了一组候选特性后,可以将它们导出到分类学习者统计和机器学习工具箱™中的应用程序。分类学习者训练模型来分类数据,使用自动化的方法来测试不同类型的模型与一个特征集。在这一过程中,分类学习者确定最佳模型和最有效的特性。对于预测性维护,使用分类学习者就是选择并训练一个模型来区分正常系统和故障系统的数据。您可以将此模型合并到故障检测和预测的算法中。关于从应用程序导出到分类学习者,请参阅分析和选择泵诊断的特性.
您还可以将您的特性和数据集导出到MATLAB工作区。这样做允许您使用命令行函数或其他应用程序可视化和处理原始和派生的集成数据。在命令行中,还可以将选择的特性和变量保存到文件中,包括集成数据存储中引用的文件。
有关导出的信息,请参见在诊断特征设计器中排列和导出特征.
生成MATLAB功能代码
为您选择的特征生成代码,这样您就可以使用MATLAB函数自动进行特征计算。例如,假设您有一个包含许多成员的大型输入数据集,但为了更快的应用响应,您希望在首次交互探索可能的功能时使用该数据的一个子集。在您使用应用程序确定最有效的功能之后,您可以生成代码,然后使用生成的代码将这些功能的相同计算应用到所有成员数据集。更大的成员集允许您提供更多的样本作为训练输入分类学习者.

函数[featureTable, outputTable] = diagnosticFeatures (inputData)%DIAGNOSTICFEATURES在诊断特性设计器中重新创建结果。%
另请参阅
相关的例子
更多关于
你也可以从以下列表中选择一个网站:
