使用残余分析对离心泵的故障诊断
此示例显示了一种基于模型奇偶方程的方法,用于检测和诊断泵送系统中发生的不同类型的故障。此示例扩展了基于稳态实验的离心泵故障诊断到泵操作跨越多个操作条件的情况。
该示例遵循Rolf Isermann故障诊断应用书中的离心泵分析[1]。它使用系统识别工具箱™,统计和机器学习工具箱™,Control System Toolbox™和Simulink™的功能,并且不需要预测的维护工具箱™。金宝app
多转速泵运行-残差分析诊断
如果泵在快速变化或更广泛的速度范围内运行,则稳态泵头和扭矩方程不会产生精确的结果。摩擦和其他损失可能变得显着,模型的参数表现出对速度的依赖性。在这种情况下,一种广泛适用的方法是创建一个黑匣子模型的行为。此类模型的参数不需要身体有意义。该模型用作用于仿真已知行为的设备。模型的输出从相应的测量信号中减去以计算残差. 残差的特性,如均值、方差和幂,用于区分正常操作和故障操作。
使用静态泵头方程和动态泵管方程,可以计算图中所示的4个残差。
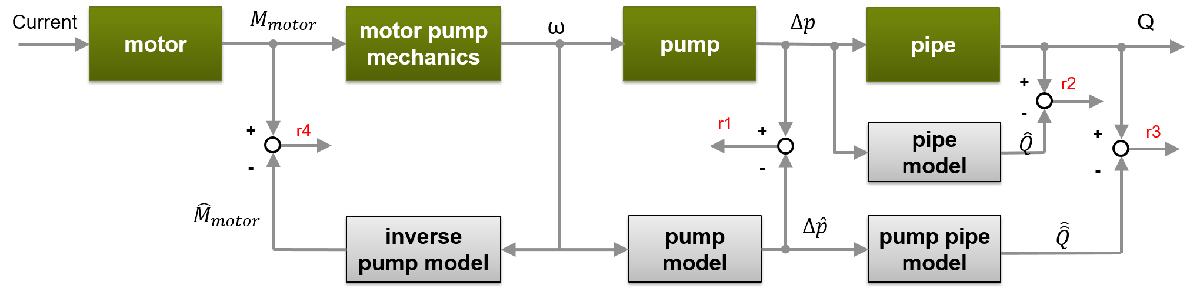
该模型具有以下组件:
静态泵模型:
动态管道模型:
动态泵管模型:
动态逆泵模型:
模型参数 显示对泵速的依赖。在这个例子中,计算参数的分段线性逼近。将操作区域划分为3个区域:
一个健康的泵在一个闭环控制器的闭环中运行参考转速范围为0 - 3000rpm。参考输入是一个改进的PRBS信号。在10hz采样频率下采集电机转矩、泵转矩、转速和压力的测量值。加载测量到的信号并绘制参考和实际泵速(这些是大数据集,约20MB,可从MathWorks支持文件站点下载)。金宝app
网址='//www.tatmou.com/金宝appsupportfiles/predmaint/fault-diagnosis-of-centrifugal-pumps-using-residual-analysis/DynamicOperationData.mat';WebSave(“DynamicOperationData.mat”,网址);负载DynamicOperationData图(t, RefSpeed, t, w) xlabel('时间'')ylabel(“泵转速(RPM)”)传奇('参考',“实际的”)

根据泵的转速范围定义工作状态。
I1 = w < = 900;%第一运行模式I2=w>900&w<=1500;%第二次操作制度I3=w>1500;%第三种经营制度
模型识别
A.静态泵模型识别
估计的参数
和
使用测量值的泵速度的静态泵方程
和压差
作为输入输出数据。请参阅辅助功能staticPumpEst执行此估计的。
th1 = 0 (3,1);th2 = 0 (3,1);dp =南(大小(dp));%估计压力差[th1(1),th2(1),dpest(I1)]=w,dp,I1;%区域1的θ1和θ2估计值[th1(2),th2(2),dpest(I2)]=w,dp,I2;%制度2的θ1、θ2估计值[th1(3), th2(3), dpest(I3)] = staticPumpEst(w, dp, I3);%方案3的θ1、θ2估计值绘图(t、dp、t、dpest)%比较测量和预测的压差xlabel('时间'')ylabel(“\Delta P”)传奇(“测量”,“估计”,'地点',“最好的”)头衔(“静态泵模型验证”)

B.动态管道模型识别
估计的参数
,
和
在管道流量方程中
,使用流量的测量值
和压差
作为输入输出数据。请参阅辅助功能动态窥视执行此估计的。
th3=零(3,1);th4=零(3,1);th5=零(3,1);[th3(1),th4(1),th5(1)]=动态速度(dp,Q,I1);%THETA3,THETA4,THETA5估计政权1[Th3(2),TH4(2),TH5(2)] = DynamicPIPEEST(DP,Q,I2);%THETA3,THETA4,THETA5估计政权2[Th3(3),TH4(3),TH5(3)] = DynamicPipeest(DP,Q,I3);%Theta3,Theta4,Theta5估计政权3
与静态泵模型不同,动态管道模型显示流量值的动态依赖性。为了模拟变速工况下的模型,使用控制系统工具箱的“LPV系统”块在Simulink中创建分段线性模型。请参阅Simulink模型金宝appLPV_pump_pipe和辅助函数simulatePumpPipeModel它执行模拟。

%检查控制系统工具箱可用性ControlsToolboxAvailable=~isempty(版本号(“控制”))&&许可证(“测试”,“控制工具箱”);如果控制按钮可用%模拟动态管道模型。使用压力的测量值作为输入Ts = t - t (1) (2);开关= 1(大小(w));开关(I2) = 2;开关(I3) = 3;UseEstimatedP = 0;Qest_pipe = simulatePumpPipeModel (Ts、th3 th4, th5);情节(t, Q t Qest_pipe)%比较测量和预测的流量别的%从分段线性Simulink模型加载预先保存的仿真结果金宝app加载DynamicOperationDataQest_pipeTs=t(2)-t(1);绘图(t、Q、t、Qest_管道)结尾xlabel('时间'')ylabel('流速(Q),m^3/s')传奇(“测量”,“估计”,'地点',“最好的”)头衔(“动态管道模型验证”)

C.动态泵管模型识别
动态泵管模型使用上述相同的参数( )除了模型模拟需要使用估计的压差,而不是测量的压差。因此不需要新的识别。检查 很好地再现了泵管动力学。
如果ControlStoolboBaIsableMailableMateStimatedP = 1;QEST_PUMP_PIPE = SIMULATEPUMPPIPEMODEL(TS,TH3,TH4,TH5);绘图(t,q,t,qest_pump_pipe)%比较测量和预测的流量别的加载DynamicOperationDataQEST_PUMP_PIPE.绘图(t,q,t,qest_pump_pipe)结尾xlabel('时间'')ylabel('流量q(m ^ 3 / s)')传奇(“测量”,“估计”,'地点',“最好的”)头衔('动态泵 - 管道模型验证')

配合几乎与使用测量的压力值所获得的配合完全相同。
D.动态逆泵模型识别
参数 通过回归先前扭矩和转速测量值上的测量扭矩值,可以以类似的方式识别。但是,所得分段线性模型的完整多转速模拟不能很好地拟合数据。因此,尝试了不同的黑盒建模方法,包括识别非线性ARX用理性回归模型拟合数据。
%在550个样品中使用前300个样品进行鉴定n = 350;sys3 = indiceNonlineararxModel(MMOT,W,Q,TS,N)
sys3 = 1输出2输入的ARX非线性模型input: u1, u2 Outputs: y1对应阶的标准回归量:na = [2] nb = [2 1] nk =[0 1]自定义回归量:u1(t-2)^2 u1(t)*u2(t-2) u2(t)^2非线性回归量:无回归量中模型输出为线性。状态:使用NLARX在时域数据上估计。拟合估计数据:50.55%(模拟焦点)FPE: 1759, MSE: 3214
Mmot_est=sim(sys3[w Q]);绘图(t,Mmot,t,Mmot_est)%比较测量和预测的电机转矩xlabel('时间'')ylabel('电动机扭矩(nm)')传奇(“测量”,“估计”,'地点',“最好的”)头衔('逆泵模型验证')

残渣生成
定义渣被测信号与相应模型产生的输出之间的差值。计算对应于四个模型组件的四个残差。
R1 = dp - dpest;r2 = Q - Qest_pipe;r3 = Q - Qest_pump_pipe;
在计算泵模型逆残差时,由于原残差方差较大,采用移动平均滤波器对模型输出进行平滑处理。
r4=Mmot-movmean(Mmot_est,[15]);
对培训残留物的看法:
图subplot(221) plot(t,r1) ylabel('静态泵 - R1')子图(222)绘图(t,r2)ylabel('动态管道 - r2')子地块(223)地块(t,r3)ylabel('动力泵管道- r3')xlabel('时间'')子图(224)plot(t,r4) ylabel(“动态逆泵-r4”)xlabel('时间'')

残留功能提取
残差是提取适当特征的信号用于故障隔离。由于没有参数信息可用,考虑纯粹源自信号特性(如信号的最大振幅或方差)的特征。
考虑使用PRBS输入实现在泵管道系统上的一组20个实验。
健康泵
故障1:间隙磨损
故障2:叶轮出口处有少量沉积物
故障3:叶轮进口处有沉积物
故障4:叶轮出口磨料磨损
故障5:叶片断裂
故障6:气蚀
故障7:速度传感器偏置
故障8:流量计偏差
故障9:压力传感器偏置
加载实验数据
网址='//www.tatmou.com/金宝appsupportfiles/predmaint/fault-diagnosis-of-centrifugal-pumps-using-residual-analysis/multispeedoperationdata.mat';WebSave(“MultiSpeedOperationData.mat”,网址);负载MultiSpeedoperationData.%生成操作模式标签标签= {“健康”,“ClearanceGapWear”,'ImpelleroutletLetteposit',...“ImpellerInletDeposit”,“磨料水”,“BrokenBlade”,“空化”,'speedsensorbias',...“流量计”,“压力传感器偏差”};
计算每个集合和每个操作模式的剩余值。这需要几分钟。因此,剩余数据保存在数据文件中。运行helperComputeEnsembleResidues生成残差,如下所示:
% HealthyR = helperComputeEnsembleResidues(HealthyEnsemble,Ts,sys3,th1,th2,th3,th4,th5);%正常数据残值
%从“HelperComputeSembleResolutions”运行加载预保存的数据网址='//www.tatmou.com/金宝appsupportfiles/predmaint/fault-diagnosis-of-centrifugal-pumps-using-residual-analysis/residuals.mat';WebSave('残差..,网址);负载残差
具有最多模式辨别力的残留物的特征是不知道的。因此,产生几个候选特征:每个残留的平均值,最大振幅,方差,峰和1标准。所有功能都使用健康合奏中的值范围进行缩放。
CandidateFeatures = {@mean, @ (x)马克斯(abs (x)), @kurtosis, @var, @ (x)和(abs (x))};FeatureNames = {“的意思是”,“马克斯”,“峰度”,“差异”,“单宁”};%从收集的每个故障模式残差生成特征表[HealthyFeature, MinMax] = helperGenerateFeatureTable(HealthyR, CandidateFeatures, FeatureNames);Fault1Feature = helperGenerateFeatureTable(Fault1R, CandidateFeatures, FeatureNames, MinMax);Fault2Feature = helperGenerateFeatureTable(Fault2R, CandidateFeatures, FeatureNames, MinMax);Fault3Feature = helperGenerateFeatureTable(Fault3R, CandidateFeatures, FeatureNames, MinMax);Fault4Feature = helperGenerateFeatureTable(Fault4R, CandidateFeatures, FeatureNames, MinMax);Fault5Feature = helperGenerateFeatureTable(Fault5R, CandidateFeatures, FeatureNames, MinMax);Fault6Feature = helperGenerateFeatureTable(Fault6R, CandidateFeatures, FeatureNames, MinMax);Fault7Feature = helperGenerateFeatureTable(Fault7R, CandidateFeatures, FeatureNames, MinMax);Fault8Feature = helperGenerateFeatureTable(Fault8R, CandidateFeatures, FeatureNames, MinMax);Fault9Feature = helperGenerateFeatureTable(Fault9R, CandidateFeatures, FeatureNames, MinMax);
每个特征表中有20个功能(每个残留信号的5个功能)。每个表包含50个观察(行),每个实验一个。
N = 50;%每种模式下的实验次数featureTable = [...[HealthyFeature(1:N,:)、repmat(标签(1),[N,1]);...[Fault1Feature(1:N,:)、repmat(标签(2),[N,1]);...[Fault2Feature(1:N,:)、repmat(标签(3),[N,1]);...[故障3Feature(1:n,:),Repmat(标签(4),[N,1])];...[Fault4Feature (1: N,:), repmat(标签(5),[N, 1]));...[Fault5Feature (1: N,:), repmat(标签(6),[N, 1]));...[Fault6Feature (1: N,:), repmat(标签(7),[N, 1]));...[故障7Feature(1:n,:),repmat(标签(8),[n,1])];...[故障8Feature(1:n,:),Repmat(标签(9),[N,1])];...[Fault9Feature(1:N,:),repmat(标签(10),[N,1])];FeatureTable.Properties.VariableNames{end}=“条件”;%预览一些训练数据样本disp(FeatureTable([2 13 37 49 61 62 73 85 102 120],:))
Mean1 Mean2 Mean3 Mean4最大值1最大值2最大值3 MAX4 Kurtosis1 Kurtosis2 Kurtosis3 Kurtosis4 Variance1 Variance2 Variance3 Variance4 OneNorm1 OneNorm2 OneNorm3 OneNorm4条件________ _______ _______ _______ _______ ________ ________ _________ _________ _________ _________ __________ _________ _________ _________ _________ ________ ________ ________ ________ _________________________ 0.32049 0.6358 0.6358 0.74287 0.39187 0.53219 0.53219 0.0417950.18957 0.089492 0.089489 0 0.45647 0.6263 0.6263 0.15642 0.56001 0.63541 0.63541 0.24258 { '健康'} 0.21975 0.19422 0.19422 0.83704 0 0.12761 0.12761 0.27644 0.18243 0.19644 0.19643 0.20856 0.033063 0.16772 0.16773 0.025119 0.057182 0.19344 0.19344 0.063167 { '健康'} 0.1847 0.25136 0.25136 0.87975 0.32545 0.13929 0.1393 0.0841620.72346 0.091488 0.091485 0.052552 0.063757 0.18371 0.18371 0.023845 0.10671 0.25065 0.25065 0.04848 { '健康'} 1 1 1 0 0.78284 0.94535 0.94535 0.9287 0.41371 0.45927 0.45926 0.75934 0.92332 1 1 0.80689 0.99783 1 1 0.9574{'Healthy' } -2.6545 0.90555 0.90555 0.86324 1.3037 0.7492 0.7492 0.97823 -0.055035 0.57019 0.57018 1.4412 1.4411 0.73128 0.73128 0.80573 3.2084 0.90542 0.90542 0.49257 {'ClearanceGapWear' } -0.89435 0.43384 0.43385 1.0744 0.82197 0.30254 0.30254 -0.022325 0.21411 0.098504 0.0985 -0.010587 0.55959 0.29554 0.29554 0.066693 1.0432 0.43326 0.43326 0.13785 {'ClearanceGapWear' } -1.2149 0.53579 0.53579 1.0899 0.87439 0.47339 0.47339 0.29547 0.058946 0.048138 0.048137 0.17864 0.79648 0.48658 0.48658 0.25686 1.4066 0.5353 0.5353 0.26663 {'ClearanceGapWear' } -1.0949 0.44616 0.44616 1.143 0.56693 0.19719 0.19719 -0.012055 -0.10819 0.32603 0.32603 -0.0033592 0.43341 0.12857 0.12857 0.038392 1.2238 0.44574 0.44574 0.093243 {'ClearanceGapWear' } -0.1844 0.16651 0.16651 0.87747 0.25597 0.080265 0.080265 0.49715 0.5019 0.29939 0.29938 0.5338 0.072397 0.058024 0.058025 0.1453 0.20263 0.16566 0.16566 0.14216 {'ImpellerOutletDeposit'} -3.0312 0.9786 0.9786 0.75241 1.473 0.97839 0.97839 1.0343 0.0050647 0.4917 0.4917 0.89759 1.7529 0.9568 0.9568 0.8869 3.6536 0.97859 0.97859 0.62706 {'ImpellerOutletDeposit'}
分类器设计
A.可视化模式使用散点图可分离性
通过目视检查功能开始分析。为此,考虑故障1:磨损在间隙处。要查看最适合检测到此故障的功能,请生成带有标签“健康”和“清除”的功能的散点图。
t = featurectable(:,1:20);p = t.variables;r = featureetable.condition;我= strcmp(r,“健康”)|Strcmp(r,“ClearanceGapWear”);f =图;gplotmatrix (P(我:),[],R (I)) f.Position (3:4) = f.Position (3:4) * 1.5;

虽然不清晰可见,但第1列和第17列中的功能提供了最大的分离。请更仔细地分析这些功能。
f =图;名称= featureetable.properties.variablenames;J = [1 17];流('为间隙故障选择的功能:%s\n',strjoin(姓名(J),', ')))
间隙故障的选定特征:平均值1,1或M1
gplotmatrix(p(i,[117]),[],R(i))

绘图现在清楚地表明,均值1和onenorm1的特征可用于将健康模式与间隙故障模式分开。可以针对每个故障模式执行类似的分析。在所有情况下,可以找到一个分辨故障模式的一组功能。因此侦查始终可能出现错误的行为。但是,错误隔离由于相同的特征会受到多种故障类型的影响,因此比较困难。例如,特征Mean1 (r1的平均值)和OneNorm1 (r1的1-norm)显示了许多故障类型的变化。有些故障(如传感器偏差)在许多特征上是可分离的,因此更容易分离。
对于三个传感器偏差故障,从散点图的手动检查中拾取特征。
数字;我= strcmp(r,“健康”)|Strcmp(r,“压力传感器偏差”)|Strcmp(r,'speedsensorbias')|Strcmp(r,“流量计”);j = [1 4 6 16 20];%选定的特征索引流('传感器的选定功能''偏差:%s\n',strjoin(姓名(J),', ')))
传感器偏置的选定功能:均值1,平均值4,max2,variance4,onenorm4
gplotmatrix(P(I,J),[],R(I))

所选特征的散点图表明,在一对或多对特征上可以区分4种模式。使用简化的特征集训练一个20个成员的Tree Bagger分类器,用于简化故障集(仅传感器偏差)。
RNG.违约重复性的%Mdl=TreeBagger(20,特征表(I,[J 21]),“条件”,...“OOB预测”,'在',...“OOB预测重要性”,'在');图形图(oobError(Mdl))xlabel(“树的数量”)ylabel('错误分类概率')

错误分类误差小于3%,因此可以选择并使用较小的特征集对特定故障子集进行分类。
B.使用分类学习者应用程序的多级分类
上一节的重点是手动检查散点图,以减少特定故障类型的功能。这种方法可以繁琐,可能无法涵盖所有故障类型。您可以设计一个可以以更自动的方式处理所有故障模式的分类器吗?统计和机器学习工具箱中有许多分类器可用。一种快速的方式尝试其中许多并比较他们的表演是使用分类学习者应用程序。
启动分类学习者应用程序,并从工作区中选择FeatureTable作为新会话的工作数据。留出20%的数据(每个模式10个样本)用于坚持验证。

选择全部下模型类型主选项卡的一部分。然后按火车按钮。

在短时间内,大约有20个分类器被训练出来。它们的准确度显示在历史面板下的名称旁边。线性SVM分类器的性能最好,对保留样本的准确率为86%。该分类器在识别“ClearanceGapWear”时存在一定困难,40%的时间该分类器将其分类为“叶轮出口沉积物”。
要获得性能的图形视图,请从主选项卡的绘图部分打开混淆矩阵图。该曲线显示所选分类器的性能(这里的线性SVM分类器)。




将最佳执行分类器导出到工作区,并使用它以预测新测量。
总结
设计良好的故障诊断策略可以通过最大限度地减少服务停机时间和部件更换成本来节省运营成本。该策略得益于对操作机器动态的良好了解,该动态与传感器测量结合使用,以检测和隔离不同类型的故障。该示例描述了剩余故障在建模任务复杂且模型参数依赖于运行条件的情况下,该方法是基于参数估计和跟踪方法的良好替代方法。
基于残差的故障诊断方法包括以下步骤:
利用物理因素或黑箱系统识别技术,对系统可测量输入和输出之间的动力学进行建模。
计算残差作为测量信号和模型产生信号之间的差值。可能需要进一步过滤残差以提高故障隔离性。
从每个残差信号中提取特征,如峰值振幅、功率、峰度等。
使用异常检测和分类技术使用故障检测和分类功能。
并非所有残留物和衍生特征都对每个故障敏感。特征直方图和散点图的视图可以揭示哪些特征适合于检测某个故障类型。这种挑选功能和评估其故障隔离性能的过程可以是迭代过程。
参考文献
伊斯梅州,罗尔夫,故障诊断的应用。基于模型的状态监测:执行机构,驱动器,机械,工厂,传感器和容错系统,第1版,施普林格-弗拉格柏林海德堡,2011。
金宝app辅助功能
静态泵方程参数估计
功能[x1,x2,dpest] = staticpumpest(w,dp,i)%变速设定下的静态泵PEST静态泵参数估计% I:所选操作区域的样本指数。w1 = [0;w(i)];dp1 = [0;DP(i)];R1 = [W1。^ 2 W1];X = PINV(R1)* DP1;x1 = x(1);x2 = x(2);dpest = r1(2:结束,:) * x;结尾
动态管道参数估计
功能[x3,x4,x5,qest] = dynamicpipeest(dp,q,i)%变速设置下的动态速度动态管道参数估计% I:所选操作区域的样本指数。Q = Q(我);dp = dp (I);R1 = [0;问(1:end-1)];R2 = dp;R2 (R2 < 0) = 0;R2 = sqrt (R2);R = [ones(size(R2)), R2, R1];%删除了政权样本ii=find(I);j=find(diff(ii)~=1);R=R(2:end,:);R(j,:)=[];y=Q(2:end);y(j)=[];x=R\y;x3=x(1);x4=x(2);x5=x(3);Qest=R*x;结尾
使用LPV系统块对泵管模型进行动态、多工况模拟。
功能Qest=模拟泵模型(Ts、th3、th4、th5)%SIMULATEPUMPPIPEMODEL动态管道系统的分段线性建模。% Ts:采样时间% w:泵转速%th1,th2,th3是3个方案的估计模型参数。%此函数需要控制系统工具箱。SS1 = SS(TH5(1),TH4(1),TH5(1),TH4(1),TS);SS2 = SS(TH5(2),TH4(2),TH5(2),TH4(2),TS);SS3 = SS(TH5(3),TH4(3),TH5(3),TH4(3),TS);偏移=润滑([Th3(1),Th3(2),Th3(3)],[3 2 1]);op = struct(“区域”, (1 2 3) ');sys =猫(ss3 ss2 3魔法石,第1章);sys。SamplingGrid =运算;assignin (“基地”,'sys'sys) assignin (“基地”,'抵消',偏移量)mdl =“LPV_泵_管”;sim (mdl);q = logsout.get (“问”);qest = qest.values;QEST = QEST.DATA;结尾
识别逆泵动力学的动态模型。
功能syse=识别非线性模型(Mmot,w,Q,Ts,N)%识别非线性ARX模型识别2输入(w,Q),1输出(Mmot)数据的非线性ARX模型。%投入:%w:转速%Q:流速%Mmot:电机扭矩% N:要使用的数据样本数量%产出:%syse:已识别模型%%此函数使用系统识别工具箱中的NLARX估计器。Sys = idnlarx([2 2 1 0 1], 1);'',‘海关人员’,{“u1(2) ^ 2”,'U1(T)* U2(T-2)','u2(t)^2'});data=iddata(Mmot[wq],Ts);opt=nlarxOptions;opt.Focus='模拟';opt.SearchOptions.MaxIterations=500;syse=nlarx(数据(1:N),sys,opt);结尾
相关话题
您还可以从以下列表中选择一个网站:
