clusterDBSCAN.estimateEpsilon
语法
描述
ε= clusterDBSCAN.estimateEpsilon (X,MinNumPoints,MaxNumPoints)ε,用于density-based空间聚类的应用程序与噪声(DBSCAN)算法。ε从输入数据计算吗X使用一个k最近的邻居(knn)搜索。MinNumPoints和MaxNumPoints设定一个范围kε是计算的值。范围延伸到MinNumPoints- 1通过MaxNumPoints- 1。k是邻居的一个点的数量,这是一个不到点的数量在一个社区。
clusterDBSCAN.estimateEpsilon (显示一个图显示k神经网络搜索曲线和估计ε。X,MinNumPoints,MaxNumPoints)
例子
估计ε从数据
创建模拟目标数据和使用clusterDBSCAN.estimateEpsilon函数计算一个适当的ε阈值。
创建目标数据xy笛卡儿坐标。
2 X = [randn(20日)+ (11.5,11.5);randn (20, 2) + (25、15);…randn (20, 2) + (8、20);兰德(10 * 10,2)+ [20、20]];
设置的值的范围k神经网络搜索。
minNumPoints = 15;maxNumPoints = 20;
估计聚类阈值ε和显示它的值在一个阴谋。
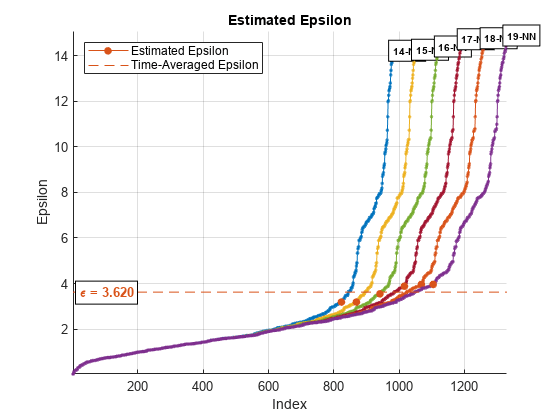
clusterDBSCAN.estimateEpsilon (X, minNumPoints maxNumPoints)
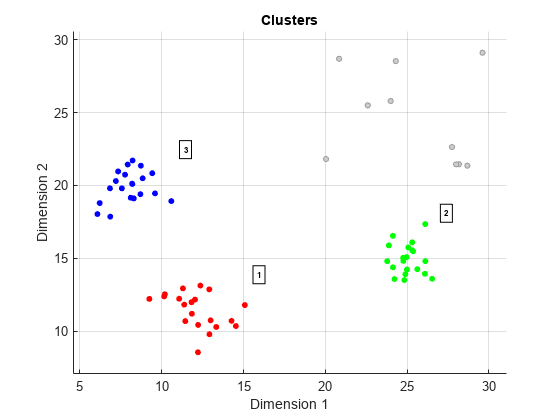
使用估计ε值3.62,clusterDBSCANclusterer运算。然后,绘制集群。
clusterer运算= clusterDBSCAN (“MinNumPoints”6‘ε’,3.62,…“EnableDisambiguation”、假);[idx, cidx] clusterer运算(X) =;情节(clusterer运算,X, idx)
输入参数
输出参数
算法
估计ε
DBSCAN聚类需要一个值邻域大小参数ε。的clusterDBSCAN对象和clusterDBSCAN.estimateEpsilon函数使用一个k最近邻搜索来估计一个标量ε。让D任意一点的距离P对其kth最近的邻居。定义一个Dk(P)社区作为社区周围P包含它的k最近的邻居。有k+ 1分Dk(P)社区包括这一点P本身。大纲的估计算法是:
对于每个点,找到所有的点Dk(P)附近
积累的距离Dk(P所有点到一个向量)的社区。
通过增加距离排序向量。
情节的排序k区域图,排序距离对点数量。
找到曲线的膝盖。距离的值在这一点上是ε的估计。
这里的图绘制对点指数显示距离k= 20。膝盖发生在大约1.5。任何低于这个阈值点属于一个集群。任何比这个值是噪音。

有几种方法来找到曲线的膝盖。clusterDBSCAN和clusterDBSCAN.estimateEpsilon首先定义线连接曲线的第一个和最后一个点。点的纵坐标排序k距离图最远的从线和垂直于行定义了ε。

当你指定一个范围k值,该算法平均估计ε值曲线。这个数字表明,ε相当迟钝k为k从14到19。

创建一个单k神经网络的距离图,设置MinNumPoints财产等于MaxNumPoints财产。
扩展功能
版本历史
介绍了R2021a