clusterDBSCAN
基于密度的数据聚类算法
描述
clusterDBSCAN聚类数据点属于P-维特征空间采用基于密度的应用空间聚类(DBSCAN)算法。聚类算法将特征空间中彼此接近的点分配到单个聚类中。例如,雷达系统可以返回距离、角度和多普勒距离较近的扩展目标的多个探测结果。clusterDBSCAN将这些检测分配给单个检测。
DBSCAN算法假设聚类是数据空间中被低密度区域分开的密集区域,所有密集区域具有相似的密度。
为了测量一个点的密度,该算法计算该点附近的数据点的数量。一个社区是一个P特征空间的-维椭圆(超椭圆)。椭圆的半径是由P向量ε。ε可以是标量,在这种情况下,超椭圆变成了超球。利用欧几里得距离度量计算特征空间中点之间的距离。邻域称为ε邻域。ε值由
ε财产。ε可以是标量还是P向量:当特征空间的不同维度有不同的单位时,使用向量。
标量对所有维度都适用相同的值。
集群首先要找到所有核心点。如果一个点在其ε邻域内有足够多的点,则称之为核心点。一个点成为核心点所需的最低分数是由
MinNumPoints财产。核点ε邻域内的剩余点可以是核点本身。如果不是,那就是边境点。ε邻域内的所有点称为直接密度可及从核心点。
如果一个核点的ε邻域包含其他核点,则所有核点的ε邻域内的点合并在一起形成ε邻域并集。这个过程会一直持续下去,直到不能再添加核心点为止。
ε邻域并集中的所有点为密度可及从第一个核心点开始。事实上,并集中的所有点都是从并集的所有核心点密度可达的。
ε邻域并中的所有点也被称为ε邻域密度连接尽管边界点不一定是可获得的从对方。一个集群是密度连通点的最大集合,可以有任意形状。
不是核心点或边界点的点是噪音点。它们不属于任何集群。
的
clusterDBSCAN对象可以使用k-nearest neighbor search,或者可以指定值。为了让对象估计ε,设置EpsilonSource财产“汽车”.的
clusterDBSCAN对象可以消除包含歧义的数据。距离和多普勒是可能存在模糊数据的例子。集EnableDisambiguation财产真正的消除歧义的数据。
集群检测:
创建
clusterDBSCAN对象,并设置其属性。使用参数调用对象,就像调用函数一样。
要了解更多关于System对象如何工作的信息,请参见什么是系统对象?
创建
描述
clusterer运算= clusterDBSCANclusterDBSCAN对象,clusterer运算,对象的默认属性值。
clusterer运算= clusterDBSCAN(名称,值)clusterDBSCAN对象,clusterer运算,并使用每个指定的属性的名字设置为指定的价值.可以以任意顺序指定其他名称-值对参数,如(Name1,Value1,...,以,家).任何未指定的属性都接受默认值。例如,
clusterer运算= clusterDBSCAN (“MinNumPoints”3,‘ε’2,...“EnableDisambiguation”,真的,“AmbiguousDimension”[1, 2]);
EnableDisambiguation属性设置为true,则AmbiguousDimension设置为[1,2].
属性
使用
语法
描述
[也返回一个备用的集群id集,idx,clusterids] = clusterer运算(X)clusterids,用于分阶段。RangeEstimator和分阶段。DopplerEstimator对象。clusterids为每个噪声点分配一个唯一的ID。
输入参数
输出参数
对象的功能
要使用对象函数,请指定System对象™作为第一个输入参数。例如,释放名为system的对象的系统资源obj,使用下面的语法:
发行版(obj)
例子
距离和多普勒群集探测
通过测量范围和多普勒来创建扩展对象的探测。假设最大无模糊距离为20米,无模糊多普勒跨度从
赫兹,
赫兹。中包含了本示例的数据dataClusterDBSCAN.mat文件。数据矩阵的第一列表示距离,第二列表示多普勒。
输入数据包含以下扩展目标和虚警:
定位于的明确的目标
多普勒定位的模糊目标
在距离范围内定位的模糊目标
距离和多普勒定位的模糊目标
5假警报
创建一个clusterDBSCAN对象,并指定不通过设置执行消歧EnableDisambiguation来假.求解聚类指数。
负载(“dataClusterDBSCAN.mat”);cluster1 = clusterDBSCAN (“MinNumPoints”3,‘ε’2,...“EnableDisambiguation”、假);idx = cluster1 (x);
使用clusterDBSCAN情节对象函数显示集群。
情节(cluster1, x, idx)
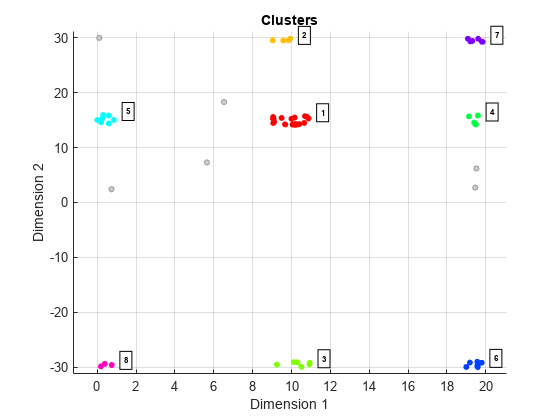
图中显示有8个明显簇和6个噪声点。“尺寸1 '标签对应于范围,而'维度2》标签对应多普勒。
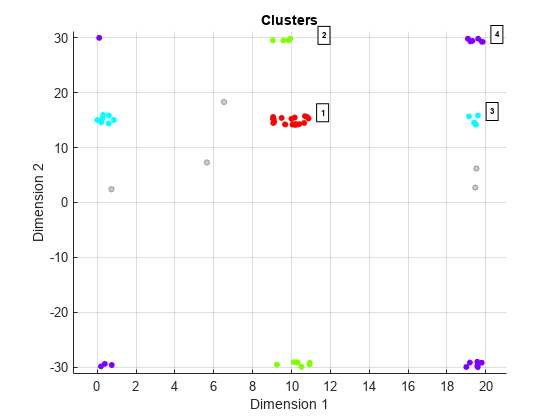
接下来,创建另一个clusterDBSCAN对象并设置EnableDisambiguation来真正的指定跨距离和多普勒模糊边界执行聚类。
cluster2 = clusterDBSCAN (“MinNumPoints”3,‘ε’2,...“EnableDisambiguation”,真的,“AmbiguousDimension”[1, 2]);
利用模糊度限制进行聚类,然后绘制聚类结果。DBSCAN聚类结果正确显示了4个聚类和5个噪声点。例如,距离为0的点与距离为20米的点聚集在一起,因为最大的明确距离是20米。
amblims = [0 maxRange;minDoppler maxDoppler];idx = cluster2 (x, amblims);情节(cluster2 x, idx)
对聚类的影响
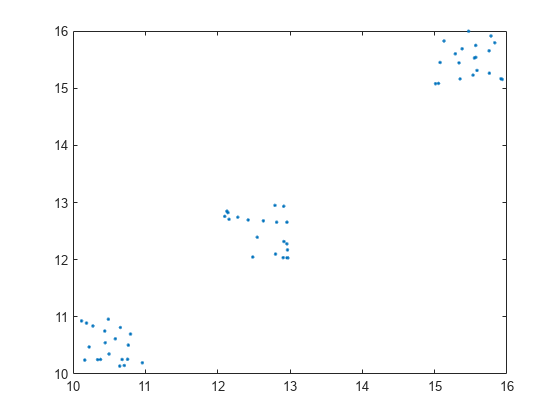
利用二维笛卡儿位置数据聚类clusterDBSCAN.为了说明epsilon的选择如何影响聚类,请将与的聚类结果进行比较ε设为1ε设置为3。
中创建随机目标位置数据xy笛卡儿坐标。
2 x =[兰德(20日)+ 12;兰特(20,2)+ 10;兰德(20,2)+ 15);情节(x (: 1) x (:, 2),“。”)
创建一个clusterDBSCAN对象的ε属性设置为1,则MinNumPoints属性设置为3。
clusterer运算= clusterDBSCAN (‘ε’, 1“MinNumPoints”3);
在以下情况下群集数据ε等于1。
idxEpsilon1 clusterer运算(x) =;
再次群集数据,但与ε设置为3。的值可以更改ε因为它是一个可调属性。
clusterer运算。ε=3.; idxEpsilon2 = clusterer(x);
并排绘制聚类结果。通过将坐标轴句柄和标题传递到情节方法。这张图显示了ε设为1,出现三个集群。当ε为3时,两个较低的集群合并为一个。
hAx1 =情节(1、2、1);情节(clusterer运算,x, idxEpsilon1...“父”hAx1,“标题”,“ε= 1”) hAx2 = subplot(1,2,2);情节(clusterer运算,x, idxEpsilon2...“父”hAx2,“标题”,“ε= 3”)

算法
聚类算法
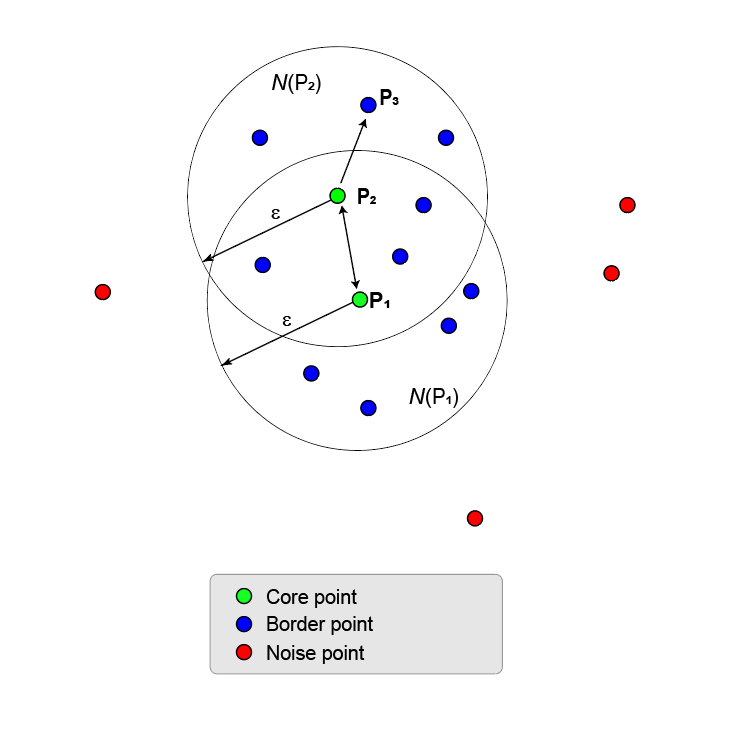
本节阐述了集群形成的基本原则。图中显示了二维特征空间中的点。星系团紧密且分离良好。一些噪声点出现了。

集群从核心点开始。算法的第一步是识别所有的核心点。
这里的图显示了这一点P1和它的ε附近Nε(P1).ε邻域在ε半径内有8个点(包括它自己)。使用
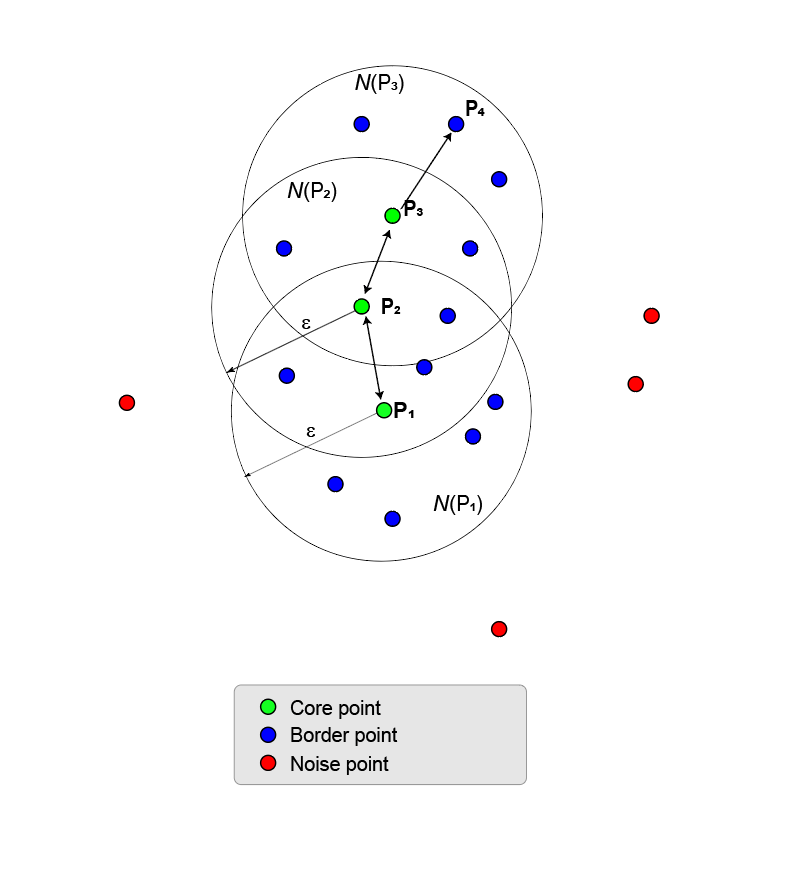
MinNumPoints属性将阈值设置为8表示P1是一个核心点。蓝色的点在里面Nε被称为边界点.这些边界点是直接密度可及从核心角度P1.图中其他点的ε邻域内没有足够的邻域点成为核心点。P2不是一个核心点,因为它在附近只有5个点。P2是否可以直接达到密度P1.反之则不成立,因为P2不是核心。连接两点的单向箭头表示了这种不对称。
落在外面的点Nε(P1)噪音点(红色)不属于集群。
由于没有其他点是核心点,因此核心点和边界点是密度连通点的最大集合,从而形成聚类。
下一个图显示了一个更大的点集合,包含两个核心点,P1和P2.P2边界点是P1但P2也有足够的点在它自己的邻居,成为一个核心点。因为它们都是核心,P1是否可以直接达到密度P2,P1是否可以直接达到密度P2.连接它们的双向箭头显示了这种对称性。

P3.是否可以直接达到密度P2但不从P1(如单向箭头所示)。然而,P3.被称为简单密度可及从P1.
由于没有其他的点是核心点,两个核心点及其边界点形成一个最大的密度连通点集,形成一个簇。

集群的成长过程可以从一个核心点扩展到另一个核心点,直到没有核心点可以添加,核心点和边界点属于同一个集群。一般来说,是一个点Pn从点可以达到密度吗P1当有一系列的核心点时,P1,P2,P3.、……Pn - 1使每个核心点P我+1是否可以直接达到密度P我,Pn是否可以直接达到密度Pn-1.
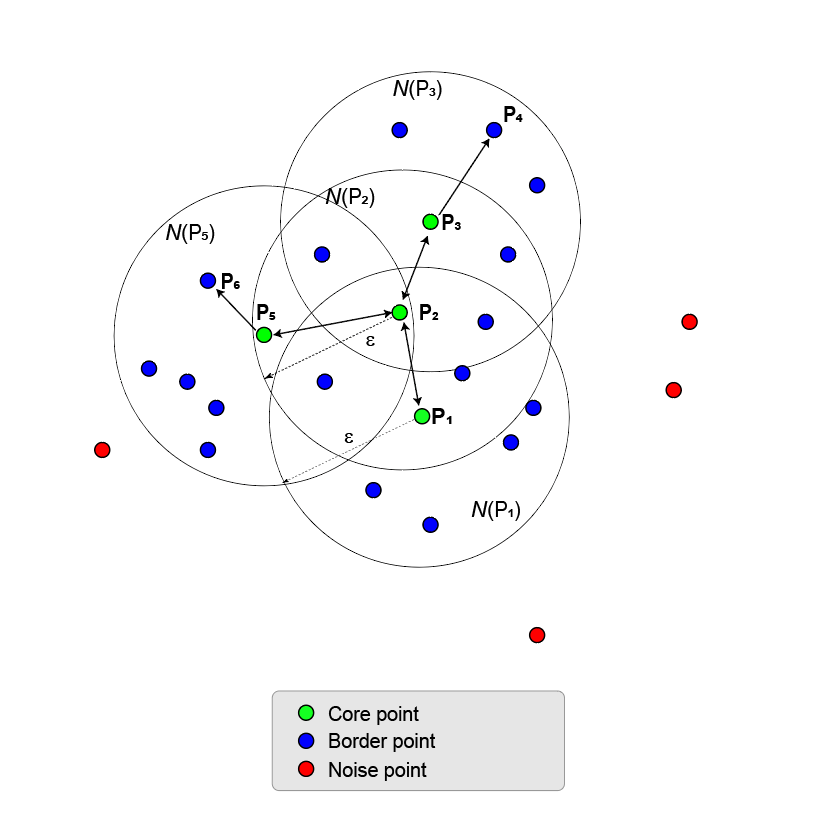
下一个图说明了密度连通性的一些特性。
集群可以有多个分支链,例如(P1,P2,P3.,P4)和(P1,P2,P5,P6).
两个点,P6和P4,都是密度连接当有第三点的时候P2这样P6和P4密度是否可达P2.
两个密度连通点之间不一定密度可达。
聚类由密度连通点的最大集合定义。哪个核心点是起始核心点并不重要。
集群中的所有点的密度都可以从所有核心点到达。
估计ε
DBSCAN聚类需要一个值作为邻域大小参数ε。的clusterDBSCAN对象和clusterDBSCAN.estimateEpsilon函数使用一个k最近邻搜索来估计标量。让D为任意点的距离P对其kth最近的邻居。定义一个Dk(P)-邻里作为一个邻里周围P包含它的k最近的邻居。有k+ 1分Dk(P)-邻域包括点P本身。估计算法的概要如下:
对于每个点,找出它的所有点Dk(P)附近
将所有距离相加Dk(P)的邻居为所有点进入一个单一的向量。
通过增加距离对向量进行排序。
情节的排序kdist图,它是与点数的排序距离。
找到曲线的膝盖。这一点距离的值是的估计值。
这里的图显示了与点索引的距离k= 20。膝盖在1.5左右。低于此阈值的任何点都属于一个集群。任何高于这个值的点都是噪声。

有几种方法可以找到曲线的膝部。clusterDBSCAN和clusterDBSCAN.estimateEpsilon首先定义连接曲线第一个和最后一个点的直线。已排序点的坐标k距离直线最远且垂直于直线的dist图定义。

指定的范围时k值,算法平均所有曲线的估计值。这张图表明对是不敏感的k为k从14岁到19岁。

创建一个k-NN距离图,设置MinNumPoints属性等于MaxNumPoints财产。
参考文献
Ester M., Kriegel h . p ., Sander J., Xu X.。“基于密度的大型空间数据库聚类发现算法”。Proc。第二Int。知识发现与数据挖掘研讨会,波特兰,奥尔特,AAAI出版社,1996,第226-231页。
[2]埃里希·舒伯特,Jörg桑达,马丁·埃斯特,汉斯-彼得·克里格尔,徐晓伟。2017。DBSCAN Revisited, Revisited: Why and How You Should (Still) Use DBSCANACM反式。数据库系统。42,3,第19条(2017年7月),21页。
[3] Dominik Kellner, Jens Klappstein and Klaus Dietmayer,“基于网格的DBSCAN雷达数据扩展目标聚类”,2012 IEEE智能汽车研讨会.
[4] Thomas Wagner, Reinhard Feger, and Andreas Stelzer,“一种用于距离/多普勒/DoA测量的快速网格聚类算法”,第十三届欧洲雷达会议论文集.
[5] Mihael Ankerst, Markus M. Breunig, Hans-Peter Kriegel, Jörg Sander,《OPTICS:排序点识别集群结构》,Proc. ACM SIGMOD ' 99 Int。关于数据管理的会议1999年,宾夕法尼亚州费城。
扩展功能
你也可以从以下列表中选择一个网站: