Train PG Agent to Balance Cart-Pole System
This example shows how to train a policy gradient (PG) agent to balance a cart-pole system modeled in MATLAB®. For more information on PG agents, seePolicy Gradient Agents。
有关用基线列举PG代理的示例,请参阅Train PG Agent with Baseline to Control Double Integrator System。
车杆Matlab环境
用于该示例的增强学习环境是连接到推车上的unactuat接头的杆,其沿着无摩擦轨道移动。培训目标是使摆锤直立直立而不会摔倒。

For this environment:
The upward balanced pendulum position is
0.弧度和向下悬挂的位置是piradians.摆锤直立,初始角度在-0.05和0.05弧度之间。
The force action signal from the agent to the environment is from –10 to 10 N.
来自环境的观察是推车,摆角和摆角衍生物的位置和速度。
如果杆从垂直或撞车从原始位置移动超过2.4米,杆终止终止。
A reward of +1 is provided for every time step that the pole remains upright. A penalty of –5 is applied when the pendulum falls.
关于这个模型的更多信息,请参阅负载预定义控制系统环境。
创建环境界面
Create a predefined environment interface for the pendulum.
Env = Rlpredefinedenv(“cartpole - 离散”)
env = CartPoleDiscreteAction with properties: Gravity: 9.8000 MassCart: 1 MassPole: 0.1000 Length: 0.5000 MaxForce: 10 Ts: 0.0200 ThetaThresholdRadians: 0.2094 XThreshold: 2.4000 RewardForNotFalling: 1 PenaltyForFalling: -5 State: [4x1 double]
The interface has a discrete action space where the agent can apply one of two possible force values to the cart, –10 or 10 N.
Obtain the observation and action information from the environment interface.
ObsInfo = GetobservationInfo(ENV);numobservations = Obsinfo.dimension(1);Actinfo = GetActionInfo(Env);
Fix the random generator seed for reproducibility.
RNG(0)
创建PG代理
PG代理决定使用演员表示来考虑观察的行动。要创建演员,首先创建一个具有一个输入(观察)和一个输出(动作)的深神经网络。Actor网络具有两个输出,其对应于可能的动作的数量。有关创建深度神经网络策略表示的更多信息,请参阅创建策略和值函数表示。
actorNetwork = [ featureInputLayer(numObservations,'正常化'那'没有'那'名称'那'state')全连接列(2,'名称'那'fc')softmaxlayer('名称'那'actionProb')];
指定使用的Actor表示的选项rlrepresentationOptions.。
Actoropts = RlRepresentationOptions('学习',1e-2,'gradientthreshold'那1);
使用指定的深神经网络和选项创建演员表示。您还必须指定从环境界面获取的批评者的操作和观察信息。有关更多信息,请参阅rlStochasticActorRepresentation。
actor = rlStochasticActorRepresentation(actorNetwork,obsInfo,actInfo,'观察'那{'state'},actoropts);
Create the agent using the specified actor representation and the default agent options. For more information, seerlPGAgent。
agent = rlPGAgent(actor);
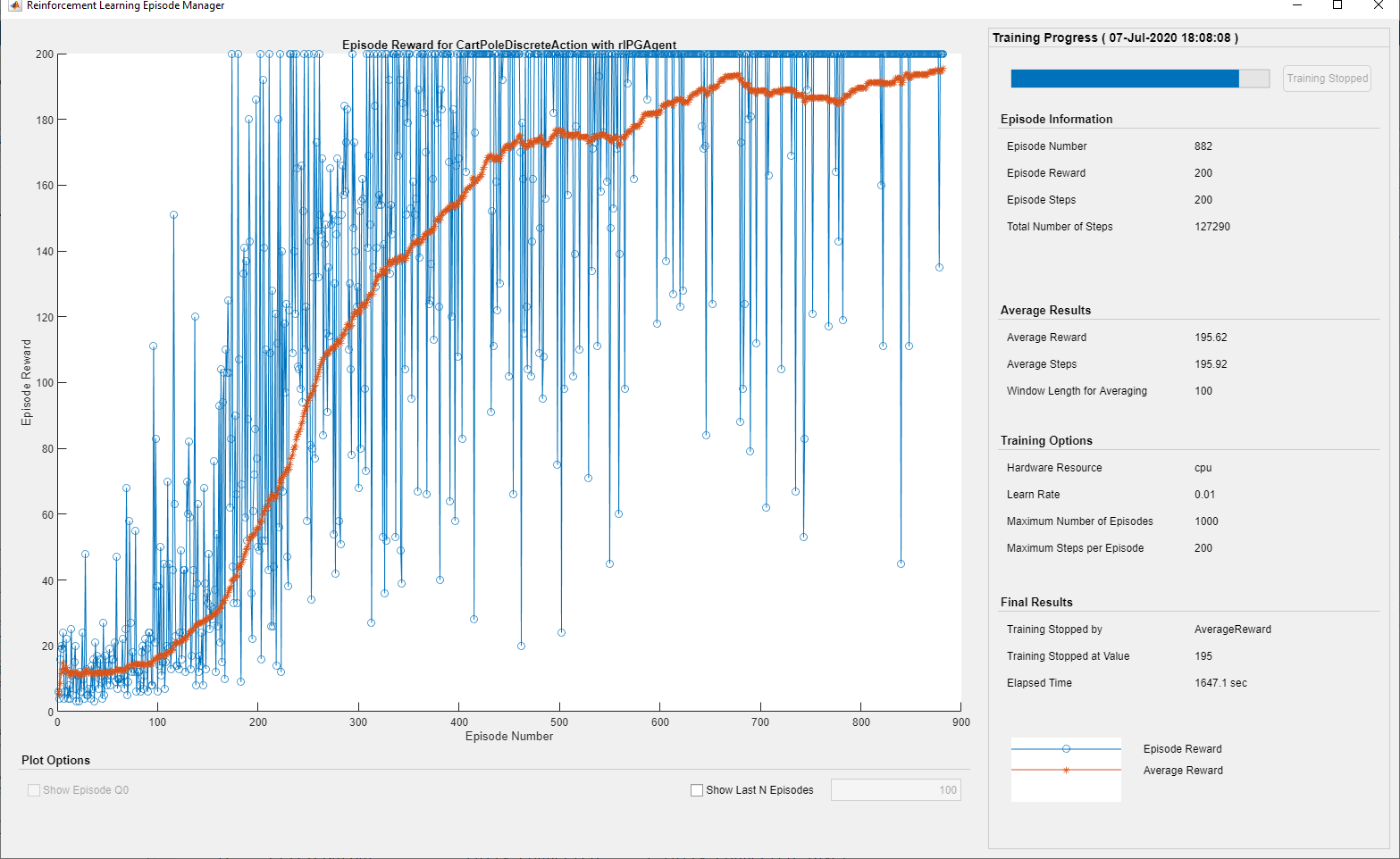
火车代理
要培训代理,首先指定培训选项。对于此示例,请使用以下选项。
Run each training episode for at most 1000 episodes, with each episode lasting at most 200 time steps.
在Episode Manager对话框中显示培训进度(设置
绘图选项)并禁用命令行显示(设置verboption to假)。Stop training when the agent receives an average cumulative reward greater than 195 over 100 consecutive episodes. At this point, the agent can balance the pendulum in the upright position.
有关更多信息,请参阅rlTrainingOptions。
训练= rltrainingOptions(......'MaxEpisodes',1000,......'MaxStepsPerEpisode',200,......'verbose',假,......'plots'那'培训 - 进步'那......'stoptrinaincriteria'那'AverageReward'那......'StopTrainingValue',195,......'scoreaveragingwindowlength'那100);
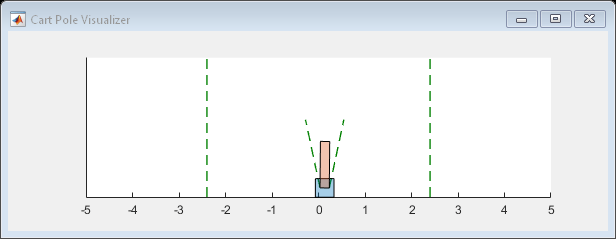
您可以使用使用的可视化推车系统系统情节培训或模拟期间的功能。
情节(env)

Train the agent using the培养功能。培训此代理是一个计算密集型进程,需要几分钟才能完成。要在运行此示例的同时节省时间,请通过设置加载预制代理用圆形至假。To train the agent yourself, set用圆形至true。
用圆形= false;如果用圆形%训练代理人。Trainstats =火车(代理,env,训练);其他%加载预磨料的代理。加载('MATLABCartpolePG.mat'那'代理');结束
Simulate PG Agent
要验证培训的代理的性能,请在推车杆环境中模拟它。有关代理模拟的更多信息,请参阅rlSimulationOptionsandSIM。即使仿真时间增加到500步,代理也可以平衡推车杆系统。
SIMOptions = rlSimulationOptions('MaxSteps',500);体验= SIM(ENV,Agent,SimOptions);
TotalReward = Sum(经验.Rward)
至talReward = 500
也可以看看
Related Topics
You can also select a web site from the following list:
美洲
- América Latina(Español)
- 加拿大(英语)
- 美国(英语)
