与定制日志谱图层和深度学习的口语数字识别
这个例子展示了如何使用深度卷积神经网络(CNN)和自定义日志谱图层对语音数字进行分类。自定义层使用dlstft函数以支持自动反向传播的方式计算短时间傅里叶变换。金宝app
数据
克隆或下载自由语音数字数据集(FSDD),可在https://github.com/Jakobovski/free-spoken-digit-dataset.FSDD是一个打开的数据集,这意味着它可以随着时间的推移而增长。此示例使用8月12日在2020年8月12日提交的版本,该版本由六位扬声器中获取的数字0到9中的3000个录制组成。每个扬声器都会使用每个数字50次。数据以8000 Hz采样。
使用audioDatastore管理数据访问。设置位置属性设置为计算机上FSDD录音文件夹的位置。这个例子使用MATLAB的返回的基础文件夹tempdir命令。
pathToRecordingsFolder = fullfile (tempdir,“free-spoken-digit-dataset”,“录音”);位置= pathToRecordingsFolder;广告= audioDatastore(位置);
辅助函数helpergenLabels从FSDD文件创建标签的分类数组。的源代码helpergenLabels列在附录中。列出类和每个类的例子数量。
ads.Labels = helpergenLabels(广告);总结(ads.Labels)
1 300 2 300 3 300 4 300 5 300 6 300 7 300 8 300 9 300
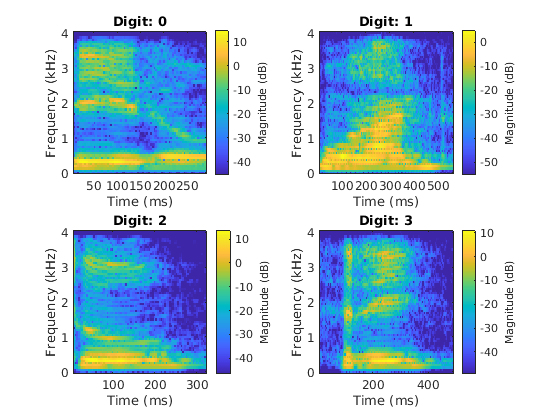
提取四个音频文件对应不同的数字。使用stft用分贝来绘制它们的声谱图。在声谱图上可以看出发音的共振峰结构的差异。这使得谱图成为学习在深度网络中区分数字的合理信号表示。
adsSample =子集(广告,[1301601901]);SampleRate = 8000;为i = 1:4 [audiosample,info] = read(adsSample); / /读取次要情节(2,2,我)stft (audioSamples SampleRate,“FrequencyRange”,“单向的”);标题(的数字:+字符串(info.Label))结束
将FSDD分解为训练集和测试集,同时在每个子集中保持相同的标签比例。为了获得可重复的结果,将随机数生成器设置为其默认值。其中80%,即2400个录音被用于训练。剩下的600段录音,占总数的20%,被保留下来进行测试。
rng默认的;广告= shuffle(广告);[adsTrain, adsTest] = splitEachLabel(广告,0.8);
确认训练集和测试集包含每个类的正确比例。
disp (countEachLabel (adsTrain))
标签数_____ _____ 0 240 1 240 2 240 3 240 4 240 5 240 6 240 7 240 8 240 9 240
DISP(CONSECHANCELABEL(ADSTEST))
标签计数_____ _____ 0 60 1 60 2 60 3 60 4 60 5 60 6 60 7 60 8 60 9 60
FSDD中的记录在样本中没有相同的长度。为了在深度网络中使用谱图作为信号表示,需要一个统一的输入长度。对这个版本的FSDD的音频记录的分析表明,8192个样本的公共长度是合适的,以确保没有语音数字被切断。长度大于8192个样本的录音被截断为8192个样本,而小于8192个样本的录音被对称填充为8192个样本。辅助函数helperReadSPData将数据截断或划接到8192个样本,并按其最大值进行规范化。的源代码helperReadSPData列在附录中。通过与转换数据存储一起使用,这个帮助函数被应用到每个记录audioDatastore.
transTrain =变换(adsTrain @ (x,信息)helperReadSPData (x,信息),“IncludeInfo”,真正的);transtest =转换(adstest,@(x,信息)helperreadspdata(x,Info),“IncludeInfo”,真正的);
定义自定义日志声谱图层
当任何信号处理作为预处理步骤在网络外进行时,网络预测的预处理设置与网络训练中使用的不同的可能性更大。这可能会对网络性能产生重大影响,通常导致性能低于预期。将光谱图或任何其他预处理计算作为一层放置在网络中,可以为您提供一个自包含的模型,并简化部署的管道。它允许您有效地培训、部署或共享您的网络,包括所有所需的信号处理操作。在这个例子中,主要的信号处理操作是谱图的计算。在网络内部计算谱图的能力对于推理和当设备存储空间不足以保存谱图时都是有用的。在网络中计算谱图只需要为当前批谱图分配足够的内存。然而,需要注意的是,这并不是训练速度的最佳选择。如果你有足够的记忆,通过预先计算所有的谱图并存储这些结果,训练时间会显著减少。然后,对网络进行训练,从存储器中读取声谱图“图像”而不是原始音频,并直接将声谱图输入网络。 Note that while this results in the fastest training time, the ability to perform signal processing inside the network still has considerable advantages for the reasons previously cited.
在训练深度网络时,使用信号表示的对数通常是有好处的,因为对数就像一个动态范围压缩器,增强具有小幅度(振幅)但仍然携带重要信息的表示值。在本例中,日志谱图比谱图表现得更好。因此,本例创建了一个自定义日志谱图层,并将其插入到输入层之后的网络中。指定义自定义深度学习层(深度学习工具箱)有关如何创建自定义层的详细信息。
声明参数和创建构造函数
logSpectrogramLayer是一个没有可学习参数的层,因此只需要非可学习属性。这里唯一需要的属性是谱图计算所需的属性。在特性部分。层的预测函数,dlarray-金宝app支持的短时傅里叶变换函数dlstft用于计算声谱图。有关dlstft而这些参数,参见dlstft文档。创建构造层和初始化层属性的函数。指定创建层所需的任何变量作为构造函数的输入。
classdeflogSpectrogramLayer < nnet.layer.Layer特性%(可选)图层属性。%光谱窗口窗口%重叠样本数量OverlapLength% DFT点数FFTLength%信号长度SignalLength结束方法函数层= logSpectrogramLayer (sigLength NVargs)争论sigLength{mustBeNumeric}NVargs。窗口{mustBeFloat, mustBeNonempty, mustBeFinite、mustBeReal mustBeVector}=损害(128“周期”) NVargs。OverlapLength{mustBeNumeric}= 96 NVargs。FFTLength{mustBeNumeric}= 128 nvargs.name.字符串=“logspec”结束层。类型=“logSpectrogram”;层。= NVargs.Name名称;层。SignalLength = sigLength;层。窗口= NVargs.Window;层。OverlapLength = NVargs.OverlapLength;层。FFTLength = NVargs.FFTLength;结束...结束
预测功能
如前所述,自定义层使用dlstft,得到STFT,然后计算STFT的平方幅值的对数,得到对数谱图。您也可以删除日志函数,或者添加任何其他支持dlarray的函数来自定义输出。金宝app你可以复制logSpectrogramLayer.m如果您想要使用predict函数的不同输出进行实验,则可以将其放到不同的文件夹中。建议将自定义层保存在不同的名称下,以防止与本例中使用的版本发生冲突。
函数Z =预测(层,X)%在预测时间通过层转发输入数据%输出结果。%%的输入:% layer -要转发的层% X -输入数据,指定为1 × 1 × c × n% dlarray,其中N为迷你批处理大小。%输出:% Z -层前向函数的输出返回为% an sz(1)-by-sz(2)-by-sz(3)-by-N%,其中sz为层输出大小,N为%小批量大小。%使用dlstft计算短时傅里叶变换。%指定数据格式为SSCB以匹配的输出% imageInputLayer。X =紧缩(X);(年,易)= dlstft (X,“窗口”层。窗口中,...“FFTLength”层。FFTLength,“OverlapLength”层。OverlapLength,...“DataFormat”,“确认”);%这个代码是需要处理的事实,2D卷积% DAG网络期望SSCBYR = permute(YR,[1 4 2 3]);YI = permute(YI,[1 4 2 3]);取短时间傅里叶模的对数平方%变换。日志(年Z =。^ 2 +易。^ 2);结束
因为logSpectrogramLayer使用相同的前向通道进行训练和预测(推断),只有预测函数是必需的,而不是向前函数是必需的。另外,因为预测功能使用dlstft,它支持金宝appdlarray,逆向传播的微分可以自动完成。这意味着你不需要写落后的函数。这是编写支持的自定义层的一个显著优势金宝appdlarray.获取支持的函数列表金宝appdlarray对象,看到支持dlarray的函数列表金宝app(深度学习工具箱).
深度卷积神经网络(DCNN)架构
您可以使用自定义层与深度学习工具箱中的任何其他层相同的方式。构造一个小的DCNN作为层数组,其中包括自定义层logSpectrogramLayer.使用卷积和批处理归一化层,并使用最大池化层对特征映射进行向下采样。为了防止过拟合,在最后一个全连接层的输入上添加少量的dropout。
sigLength = 8192;dropoutProb = 0.2;numF = 12;[imageInputLayer([sigLength 1]) logSpectrogramLayer(sigLength,“窗口”、汉明(1280)“FFTLength”, 1280,...“OverlapLength”, 900) convolution2dLayer (5 numF“填充”,“相同”maxPooling2dLayer(3,“步”2,“填充”,“相同”) convolution2dLayer (3 2 * numF“填充”,“相同”maxPooling2dLayer(3,“步”2,“填充”,“相同”) convolution2dLayer(3、4 * numF,“填充”,“相同”maxPooling2dLayer(3,“步”2,“填充”,“相同”) convolution2dLayer(3、4 * numF,“填充”,“相同”) batchNormalizationLayer reluLayer卷积2dlayer (3,4*numF,“填充”,“相同”) batchNormalizationLayer reluLayer maxPooling2dLayer(2) dropoutLayer(dropoutProb) fulllyconnectedlayer (numel(categories(ads.Labels))) softmaxLayer classificationLayer(“类”类别(ads.Labels));];
设置用于训练网络的超参数。使用小批量的50学习速率1的军医.指定亚当优化。集UsePrefetch来真正的启用异步预取和数据排队,优化训练性能。后台数据调度和使用GPU训练网络需要并行计算工具箱™。
UsePrefetch =真正的;选择= trainingOptions (“亚当”,...“InitialLearnRate”1的军医,...“MaxEpochs”30岁的...“MiniBatchSize”, 50岁,...“洗牌”,“every-epoch”,...“DispatchInBackground”UsePrefetch,...“阴谋”,“训练进步”,...“详细”,错误的);

培训网络。
[trainedNet, trainInfo] = trainNetwork (transTrain层,选项);

使用经过训练的网络来预测测试集的数字标签。计算预测精度。
(YPred,聚合氯化铝)= (trainedNet transTest)进行分类;cnnAccuracy = (YPred = = adsTest.Labels) /元素个数之和(YPred) * 100
cnnAccuracy = 97
用混淆图总结训练网络在测试集上的性能。通过使用列和行摘要显示每个类的精度和召回率。混淆图底部的表格显示了精度值。混淆图右侧的表格显示了召回值。
图(“单位”,“归一化”,“位置”,[0.2 0.2 0.5 0.5]);ccDCNN = confusionchart (adsTest.Labels YPred);ccDCNN。Title =“DCNN的困惑图”;ccdcnn.columnsummary =“column-normalized”;ccDCNN。RowSummary =“row-normalized”;

概括
这个例子展示了如何创建一个自定义的光谱图层使用dlstft.使用支持的功能金宝appdlarray,该示例演示了如何以一种支持反向传播和gpu使用的方式将信号处理操作嵌入到网络中。金宝app
附录:辅助函数
函数标签= helpergenLabels(广告)%此功能仅用于“语音数字识别”%自定义日志谱图层和深度学习的例子。它可能会改变%将在未来的版本中被删除。tmp =细胞(元素个数(ads.Files), 1);表达=“[0 - 9]+ _”;为nf = 1:numel(ads.Files) idx = regexp(ads.Files{nf},expression);tmp {nf} = ads.Files {nf} (idx);结束标签=分类(tmp);结束
函数[out,信息] = HelperReadspdata(X,Info)%此功能仅用于“语音数字识别”%自定义日志谱图层和深度学习的例子。它可能会改变%将在未来的版本中被删除。N =元素个数(x);如果n> 8192 x = x(1:8192);elseifN < 8192 pad = 8192-N;前置液=地板(垫/ 2);postpad =装天花板(垫/ 2);X = [0 (prepad,1);x;0 (postpad 1)];结束x = x / max (abs (x));出= {x / max (abs (x)), info.Label};结束
你也可以从以下列表中选择一个网站:
